Doris是一个MPP的OLAP系统,以较低的成本提供在大数据集上的高性能分析和报表查询功能。
MPP (Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)
注:MPPDB与Hadoop都是将运算分布到节点中独立运算后进行结果合并(分布式计算),但由于依据的理论和采用的技术路线不同而有各自的优缺点和适用范围。
我们现在大数据存储与处理趋势:MPPDB+Hadoop混搭使用,用MPP处理PB级别的、高质量的结构化数据,同时为应用提供丰富的SQL和事物支持能力;用Hadoop实现半结构化、非结构化数据处理。这样可以同时满足结构化、半结构化和非结构化数据的高效处理需求。
名称解释
- FE:Frontend,即 Doris 的前端节点。主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作。
- BE:Backend,即 Doris 的后端节点。主要负责数据存储与管理、查询计划执行等工作。
- Tablet:Tablet是一张表实际的物理存储单元,一张表按照分区和分桶后在BE构成分布式存储层中以Tablet为单位进行存储,每个Tablet包括元信息及若干个连续的RowSet。
- Rowset:Rowset是Tablet中一次数据变更的数据集合,数据变更包括了数据导入、删除、更新等。Rowset按版本信息进行记录。每次变更会生成一个版本。
- Version:由Start、End两个属性构成,维护数据变更的记录信息。通常用来表示Rowset的版本范围,在一次新导入后生成一个Start,End相等的Rowset,在Compaction后生成一个带范围的Rowset版本。
- Segment:表示Rowset中的数据分段。多个Segment构成一个Rowset。
- Compaction:连续版本的Rowset合并的过程成称为Compaction,合并过程中会对数据进行压缩操作。
Doris 定位
在数据分析处理框架中,Doris 主要做的是 Online 层面的数据服务,主要处理的是数据分析方面的服务。

Doris 的目标是:实现低成本,可线性扩展,支持云化部署,高可用,高查询性能,高加载性能。
Doris架构
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine) 和 Apache ORCFile (存储格式,编码和压缩) 的技术。
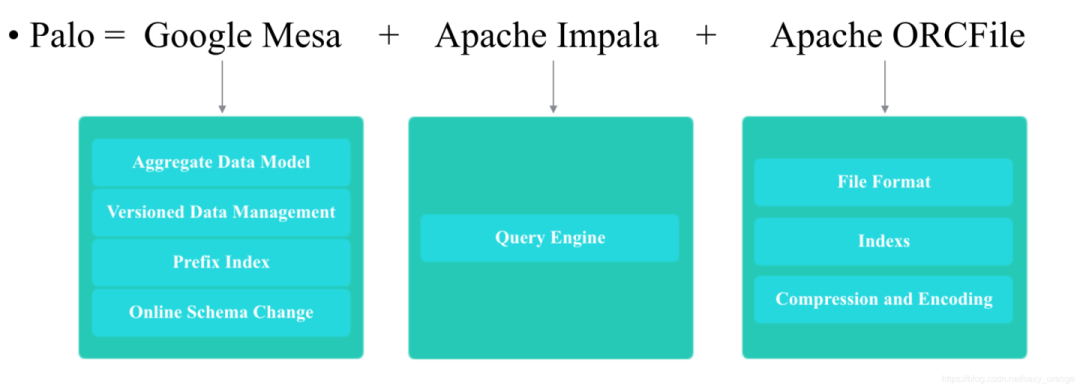
为什么要将这三种技术整合?
- Mesa是一种高度可扩展的分析数据存储系统,用于存储与Google的互联网广告业务有关的关键测量数据。Mesa旨在满足一系列复杂且具有挑战性的用户和系统需求,包括接近实时的数据提取和查询能力,以及针对大数据和查询量的高可用性,可靠性,容错性和可伸缩性。
- Impala是为Hadoop数据处理环境从头开始构建的现代开源MPP SQL引擎。
Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎;Impala是一个非常好的MPP SQL查询引擎,但是缺少完美的分布式存储引擎;ORCFile:采用列式存储(只访问查询涉及的列,能大量降低系统I/O;列数据相对来说比较类似,压缩比更高;每一列由一个线索来处理,更有利于查询的并发处理)。因此选择了这三种技术的组合。
Doris的系统架构如下图: 架构很简洁,只设FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维。

Doris 的整体架构和 TiDB 类似,借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC以及MySQL 的客户端,都可以直接访问 Doris。
Doris 中的模块包括 FE 和 BE 两类:FE 主要负责元数据的管理、存储,以及查询的解析等;一个用户请求经过 FE 解析、规划后,具体的执行计划会发送给 BE,BE 则会完成查询的具体执行。BE 节点主要负责数据的存储、以及查询计划的执行。
FE 包含的三种角色的理解 ,参见:Zookeeper中的角色
- leader跟follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
- observer只是用来扩展查询节点,就是说如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加observer的节点。observer不参与任何的写入,只参与读取。
FE:主要负责查询的编译,分发和元数据管理(基于内存,类似HDFS NN)
- 管理元数据, 执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
- FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE leader节点完成, FE follower节点可执行读操作。 元数据的读写满足顺序一致性。 FE的节点数目采用2n+1, 可容忍n个节点故障。 当FE leader故障时, 从现有的follower节点重新选主, 完成故障切换。
- FE的SQL layer对用户提交的SQL进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
- FE的Planner负载把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
- FE监督BE, 管理BE的上下线, 根据BE的存活和健康状态, 维持tablet副本的数量。
- FE协调数据导入, 保证数据导入的一致性。
BE:主要负责数据的存储、以及查询计划的执行
- BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。
- BE受FE指导, 创建或删除子表。
- BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。
- BE读本地的列存储引擎, 获取数据, 通过索引和谓词下沉快速过滤数据。
- BE后台执行compact任务, 减少查询时的读放大。
- 数据导入时, 由FE指定BE coordinator, 将数据以fanout的形式写入到tablet多副本所在的BE上。
Frontend MetaData Management
元数据层面,Doris采用Paxos协议以及Memory + Checkpoint + Journal的机制来确保元数据的高性能及高可靠。

解释:
- 元数据的每次更新,都首先写入到磁盘的日志文件中,然后再写到内存中,最后定期checkpoint到本地磁盘上。
- 相当于是一个纯内存的一个结构,也就是说所有的元数据都会缓存在内存之中,从而保证FE在宕机后能够快速恢复元数据,而且不丢失元数据。
- Leader、follower和 observer它们三个构成一个可靠的服务,单机的节点故障的时候其实基本上三个就够了,因为FE节点毕竟它只存了一份元数据,它的压力不大,所以如果FE太多的时候它会去消耗机器资源,所以多数情况下三个就足够了,可以达到一个很高可用的元数据服务。
- 在百度内部的话,我们一般是部署一个leader两个follower,外部公司目前来说基本上也是这么部署的。
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号