基本概念:ES(一): 架构及原理
-
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns) Elasticsearch ⇒ 索引(Index) ⇒ 类型(Type) ⇒ 文档(Document) ⇒ 字段(Fields) - 正向数据的层次结构: 索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)
- 存储方式: Lucene的索引结构中,即保存了正向信息(正向数据),也保存了反向信息(倒排索引)。
- 存储形式:主要包含行存储(storefiled),列存储(docvalues)和 倒排索引(invertindex)
- 5.5.0版本的倒排索引实现为FST tree (Finite State Transducer - 有限状态转换器),FST tree的最大优势就是内存空间占用非常低
Elasticsearch索引结构
Elasticsearch对外提供的是index的概念,如上可以类比为DB,用户查询是在index上完成的,每个index由若干个shard组成,以此来达到分布式可扩展的能力。比如下图是一个由10个shard组成的index。
![]()
- shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。Elasticsearch集群的存储容量则为所有index存储容量之和。
- 一个shard就对应了一个lucene的library。对于一个shard,Elasticsearch增加了translog 的功能,类似于HBase WAL,是数据写入过程中的中间数据,其余的数据都在lucene库中管理的。
- 所以Elasticsearch索引使用的存储内容主要取决于lucene中的数据存储。
Flag: translog 在对数据准确性要求不高的场景下如何配置关闭translog ?
Re:https://discuss.elastic.co/t/encrypt-translog-or-completely-disable-it/142533/5
lucene数据存储
1、lucene基本概念
- 段(Segment) : lucene内部的数据是由一个个segment组成的,写入lucene的数据并不直接落盘,而是先写在内存中,经过了refresh间隔,lucene才将该时间段写入的全部数据refresh成一个segment,segment多了之后会进行merge成更大的segment。lucene查询时会遍历每个segment完成。由于lucene* 写入的数据是在内存中完成,所以写入效率非常高。但是也存在丢失数据的风险,所以Elasticsearch基于此现象实现了translog,只有在segment数据落盘后,Elasticsearch才会删除对应的translog。
- 文档(doc) : doc表示lucene中的一条记录
- 域(Field) :field表示记录中的字段概念,一个doc由若干个field组成。
- 词(Term):term是lucene中索引的最小单位,是经过词法分析和语言处理后的字符串。某个field对应的内容如果是全文检索类型,会将内容进行分词,分词的结果就是由term组成的。如果是不分词的字段,那么该字段的内容就是一个term。
- 倒排索引(inverted index): lucene索引的通用叫法,即实现了term到doc list的映射。
- 正排数据:搜索引擎的通用叫法,即原始数据,可以理解为一个doc list。
- docvalues :Elasticsearch中的列式存储的名称,Elasticsearch除了存储原始存储、倒排索引,还存储了一份docvalues,用作分析和排序。
2、测试数据示例
2.1 下面我们以真实的数据作为示例,看看lucene中各类型数据的容量占比。
- 写100w数据,有一个uuid字段,写入的是长度为36位的uuid码,字符串总为3600w字节,约为35M。
- 数据使用一个shard,不带副本,使用默认的压缩算法,写入完成后merge成一个segment方便观察。
- 使用线上默认的配置,uuid存为不分词的字符串类型。创建如下索引:
-
PUT test_field { "settings": { "index": { "number_of_shards": "1", "number_of_replicas": "0", "refresh_interval": "30s" } }, "mappings": { "type": { "_all": { "enabled": false }, "properties": { "uuid": { "type": "string", "index": "not_analyzed" } } } } } -
首先写入100w不同的uuid,使用磁盘容量细节如下:
-
可以看到正排数据、倒排索引数据,列存数据容量占比几乎相同,正排数据和倒排数据还会存储Elasticsearch的唯一id字段,所以容量会比列存多一些。
1 health status index pri rep docs.count docs.deleted store.size pri.store.size 2 green open test_field 1 0 1000000 0 122.7mb 122.7mb 3 4 -rw-r--r-- 1 weizijun staff 41M Aug 19 21:23 _8.fdt 5 -rw-r--r-- 1 weizijun staff 17K Aug 19 21:23 _8.fdx 6 -rw-r--r-- 1 weizijun staff 688B Aug 19 21:23 _8.fnm 7 -rw-r--r-- 1 weizijun staff 494B Aug 19 21:23 _8.si 8 -rw-r--r-- 1 weizijun staff 265K Aug 19 21:23 _8_Lucene50_0.doc 9 -rw-r--r-- 1 weizijun staff 44M Aug 19 21:23 _8_Lucene50_0.tim 10 -rw-r--r-- 1 weizijun staff 340K Aug 19 21:23 _8_Lucene50_0.tip 11 -rw-r--r-- 1 weizijun staff 37M Aug 19 21:23 _8_Lucene54_0.dvd 12 -rw-r--r-- 1 weizijun staff 254B Aug 19 21:23 _8_Lucene54_0.dvm 13 -rw-r--r-- 1 weizijun staff 195B Aug 19 21:23 segments_2 14 -rw-r--r-- 1 weizijun staff 0B Aug 19 21:20 write.lock
-
.fdt:(Field Data) 存储了正排存储数据,写入的原文存储在这
- .fdx: (Field Index) 正排存储文件的元数据信息
- .fnm: (Fields) 保存了fields的相关信息
- .si: (Segment Info) segment的元数据文件
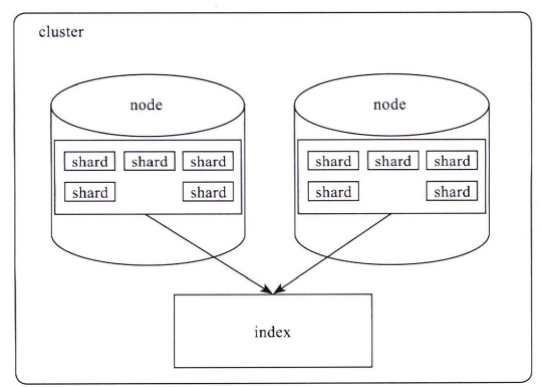
- .doc: (Frequencies) 保存了每个term的doc id列表和term在doc中的词频
- .tim: (Term Dictionary) 倒排索引的元数据信息,存储着每个域中Term的统计信息且保存着指向.doc, .pos, and .pay 索引文件的指针
- .tip: (Term Index) 倒排索引文件,保存着Term 字典的索引信息,可支持随机访问
- .dvd:lucene的 docvalues 文件,即数据的列式存储,用作聚合和排序
- .dvm: 保存索引文档加权因子的元数据
-
2.2 Elasticsearch默认是开启_all参数的,_all可以让用户传入的整体json数据作为全文检索的字段,可以更方便的检索,但在现实场景中已经使用的不多,相反会增加很多存储容量的开销,可以看下开启_all的磁盘空间使用情况:
1 health status index pri rep docs.count docs.deleted store.size pri.store.size
2 green open test_field 1 0 1000000 0 162.4mb 162.4mb
3
4 -rw-r--r-- 1 weizijun staff 41M Aug 18 22:59 _20.fdt
5 -rw-r--r-- 1 weizijun staff 18K Aug 18 22:59 _20.fdx
6 -rw-r--r-- 1 weizijun staff 777B Aug 18 22:59 _20.fnm
7 -rw-r--r-- 1 weizijun staff 59B Aug 18 22:59 _20.nvd
8 -rw-r--r-- 1 weizijun staff 78B Aug 18 22:59 _20.nvm
9 -rw-r--r-- 1 weizijun staff 539B Aug 18 22:59 _20.si
10 -rw-r--r-- 1 weizijun staff 7.2M Aug 18 22:59 _20_Lucene50_0.doc
11 -rw-r--r-- 1 weizijun staff 4.2M Aug 18 22:59 _20_Lucene50_0.pos
12 -rw-r--r-- 1 weizijun staff 73M Aug 18 22:59 _20_Lucene50_0.tim
13 -rw-r--r-- 1 weizijun staff 832K Aug 18 22:59 _20_Lucene50_0.tip
14 -rw-r--r-- 1 weizijun staff 37M Aug 18 22:59 _20_Lucene54_0.dvd
15 -rw-r--r-- 1 weizijun staff 254B Aug 18 22:59 _20_Lucene54_0.dvm
16 -rw-r--r-- 1 weizijun staff 196B Aug 18 22:59 segments_2
17 -rw-r--r-- 1 weizijun staff 0B Aug 18 22:53 write.lock
- 开启_all比不开启多了40mb的存储空间,多的数据都在倒排索引上,大约会增加30%多的存储开销。所以线上都直接禁用。7.X以上版本已放弃该属性
2.3 接 2.1 节,35M的uuid存入Elasticsearch后,数据膨胀了3倍,达到了122.7mb。Elasticsearch竟然这么消耗资源,不要着急下结论,接下来看另一个测试结果。
- 我们写入100w一样数据值的uuid,然后看看Elasticsearch使用的容量。
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 13.2mb 13.2mb
-rw-r--r-- 1 weizijun staff 5.5M Aug 19 21:29 _6.fdt
-rw-r--r-- 1 weizijun staff 15K Aug 19 21:29 _6.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 19 21:29 _6.fnm
-rw-r--r-- 1 weizijun staff 494B Aug 19 21:29 _6.si
-rw-r--r-- 1 weizijun staff 309K Aug 19 21:29 _6_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 7.0M Aug 19 21:29 _6_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 195K Aug 19 21:29 _6_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 244K Aug 19 21:29 _6_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 252B Aug 19 21:29 _6_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 195B Aug 19 21:29 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 19 21:26 write.lock
- 这回35M的数据Elasticsearch容量只有13.2mb,其中还有主要的占比还是Elasticsearch的唯一id,100w的uuid几乎不占存储容积。
- 所以在Elasticsearch中建立索引的字段如果基数越大(count distinct),越占用磁盘空间。
2.4 开启最佳压缩参数对存储空间的影响:
1 health status index pri rep docs.count docs.deleted store.size pri.store.size
2 green open test_field 1 0 1000000 0 107.2mb 107.2mb
3
4 -rw-r--r-- 1 weizijun staff 25M Aug 20 12:30 _5.fdt
5 -rw-r--r-- 1 weizijun staff 6.0K Aug 20 12:30 _5.fdx
6 -rw-r--r-- 1 weizijun staff 688B Aug 20 12:31 _5.fnm
7 -rw-r--r-- 1 weizijun staff 500B Aug 20 12:31 _5.si
8 -rw-r--r-- 1 weizijun staff 265K Aug 20 12:31 _5_Lucene50_0.doc
9 -rw-r--r-- 1 weizijun staff 44M Aug 20 12:31 _5_Lucene50_0.tim
10 -rw-r--r-- 1 weizijun staff 322K Aug 20 12:31 _5_Lucene50_0.tip
11 -rw-r--r-- 1 weizijun staff 37M Aug 20 12:31 _5_Lucene54_0.dvd
12 -rw-r--r-- 1 weizijun staff 254B Aug 20 12:31 _5_Lucene54_0.dvm
13 -rw-r--r-- 1 weizijun staff 224B Aug 20 12:31 segments_4
14 -rw-r--r-- 1 weizijun staff 0B Aug 20 12:00 write.lock
- 只有正排数据会启动压缩,压缩能力确实强劲,不考虑唯一id字段,存储容量大概压缩到接近50%
我还验证了数据长度是否和数据量成正比,发现把uuid增长2倍、4倍,存储容量也响应的增加了2倍和4倍。在此就不一一列出数据了。
3、lucene文件内容
lucene包的文件是由很多segment文件组成的,segments_xxx文件记录了lucene包下面的segment文件数量。每个segment会包含如下的文件。
lucene文件层次结构
Lucene的索引结构中,即保存了正向信息,也保存了反向信息。
所谓正向信息:
- 按层次保存了从索引一直到词的包含关系:索引(Index) –> 分片(shard) -> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)
- 也即此索引包含了那些段,每个段包含了那些文档,每个文档包含了那些域,每个域包含了那些词。
- 既然是层次结构,则每个层次都保存了本层次的信息以及下一层次的元信息,也即属性信息,比如一本介绍中国地理的书,应该首先介绍中国地理的概况, 以及中国包含多少个省,每个省介绍本省的基本概况及包含多少个市,每个市介绍本市的基本概况及包含多少个县,每个县具体介绍每个县的具体情况。如下图
![]()
-
索引(Index):
- 在Lucene中一个索引是放在一个文件夹中的。
- 如上图,同一文件夹中的所有的文件构成一个Lucene索引。
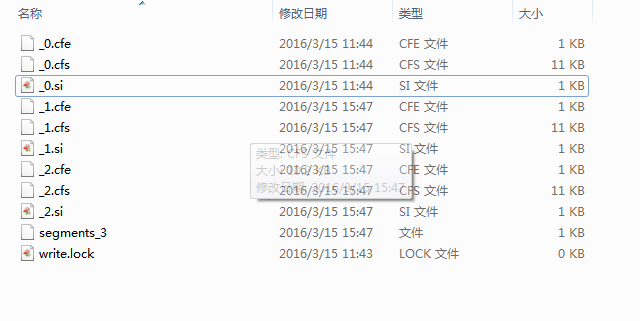
- 段(Segment):
- 一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并。
- 如上图,具有相同前缀文件的属同一个段,图中共三个段 "_0" 和 "_1"和“_2”。
- segments.gen和segments_X是段的元数据文件,也即它们保存了段的属性信息。
- 如上图,包含正向信息的文件有:
- segments_N:保存了此索引包含多少个段,每个段包含多少篇文档。
- XXX.fdx,XXX.fdt:保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
- XXX.fnm:保存了此段包含了多少个域,每个域的名称及索引方式。
- XXX.tvx,XXX.tvd,XXX.tvf:保存了此段包含多少文档,每篇文档包含了多少域,每个域包含了多少词,每个词的字符串,位置等信息。
所谓反向信息:
- 保存了词典到倒排表的映射:词(Term) –> 文档(Document)
- 如上图,包含反向信息的文件有:
- XXX.tim,XXX.tip:保存了词典(Term Dictionary),也即此段包含的所有的词按字典顺序的排序。
- XXX.frq:保存了倒排表,也即包含每个词的文档ID列表
- XXX.prx:保存了倒排表中每个词在包含此词的文档中的位置
行存储、列存储、倒排索引
es的底层存储使用lucene,主要包含行存储(storefiled),列存储(docvalues)和倒排索引(invertindex)。大多数使用场景中,没有必要同时存储这三个部分,可以通过下面的参数来做适当调整
1、mapping type index 设置
1 mappings = { 2 'testdata': { 3 '_source': {'enabled': False}, 4 '_all': {'enabled': False}, 5 'properties': { 6 'name': { 7 'type': 'string', 8 'index': false, 9 'store': False, 10 'dynamic': 'strict', 11 'fielddata': {'format': 'doc_values'} 12 } 13 } 14 } 15 }
注: 5.x及以后版本的es , string字段被拆分成两种新的数据类型: text(分词)用于全文搜索的, 而keyword(不分词)用于关键词搜索

Flag : searchable / aggregatable / analyzed / excluded / selectable ?
- 行存储,其中占比最大的是_source字段,它控制doc原始数据的存储。在写入数据时,ES把doc原始数据的整个json结构体当做一个string,存储为_source字段。查询时,可以通过_source字段拿到当初写入时的整个json结构体。 所以,如果没有取出整个原始json结构体的需求,可以通过如上面的命令,在mapping中关闭_source字段或者只在_source中存储部分字段,数据查询时仍可通过ES的docvalue_fields获取所有字段的值。
- 注意:关闭_source后, update, update_by_query, reindex等接口将无法正常使用,所以有update等需求的index不能关闭_source。
- store:默认情况下,字段会被索引,也可以搜索,但是不会存储,虽然不会被存储的,但是 _source 中有一个字段的备份。如果想将字段存储下来,可以通过配置 store 来实现。
解释 _source 与 字段的 store 属性:参考(https://www.cnblogs.com/sanduzxcvbnm/p/12157453.html)
- 如果文档的某一字段设置了 store 为 yes (默认为 no),这时候会在 _source 存储之外再为这个字段独立进行存储,这么做的目的主要是针对内容比较多的字段,放到 _source 返回的话,因为_source 是把所有字段保存为一份文档,命中后读取只需要一次 IO,包含内容特别多的字段会很占带宽影响性能,通常我们也不需要完整的内容返回(可能只关心摘要),这时候就没必要放到 _source 里一起返回了(当然也可以在查询时指定返回字段)
- 内容太长的字段,将 store 设置为 yes ,一般来说还应该在 _source 排除 exclude 掉这个字段,这时候索引的字段,不会保存在 _source 里了,会独立存储一份,查询时 _source 里也没有这个字段了,但是还是可以通过指定返回字段来获取,但是会有额外的 IO 开销,因为 _source 的读取只有一次 IO ,而已经 exclude 并设置 store 的字段,是独立存储的需要一个新的 IO 。
- 值得注意的是,虽然这个字段没有存储在 _source 了,但是这个字段还是可以 match 和高亮的。当然如果 _source 不存储,并且 store 也为 no 这时候,数据就不会返回了,也不能高亮了。但是还是可以 match 的,前提是这个字段映射时 index 属性设置了 analyzed ,lucence 对这个字段建立了倒排索引。如果 index 设置为 no 这时候等于就是没有映射这个字段了,既不能查询,也不能得到返回。
![]()
Flag: 这里的fields是...?
2、字段doc_values设置
1 PUT student 2 { 3 "mappings" : { 4 "properties" : { 5 "name" : { 6 "type" : "keyword", 7 "doc_values": false 8 }, 9 "age" : { 10 "type" : "integer", 11 "doc_values": false 12 } 13 } 14 } 15 }
- 控制列存。ES主要使用列存来支持sorting, aggregations和scripts功能,默认为 true, text 类型字段除外。
3、字段索引设置
- "index": false
- 控制倒排索引。ES默认对于所有字段都开启了倒排索引,用于查询。
_source、_all、store和index
上面几个属性在Elasticsearch中属于几个比较容易混淆的关键属性,对着图解的方式来_source、_all、store和index属性
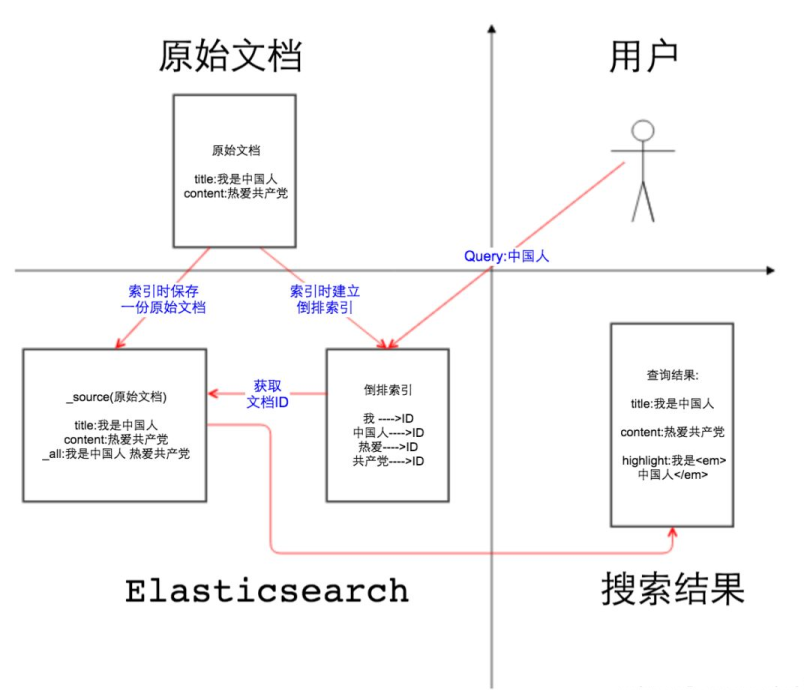
如上图, 第二象限是一份原始文档,有title和content2个字段,字段取值分别为”我是中国人”和” 热爱ZCD”。我们把原始文档写入Elasticsearch,默认情况下,Elasticsearch里面有2份内容:
- 一份是原始文档,也就是_source字段里的内容。
- 另一份是倒排索引,倒排索引中的数据结构是倒排记录表,记录了词项和文档之间的对应关系,比如关键词”中国人”包含在文档ID为1的文档中,倒排记录表中存储的就是这种对应关系,当然也包括词频等更多信息。
- 默认情况下是对所有字段创建倒排索引的(动态mapping解析出来为数字类型、布尔类型的字段除外?),某个字段是否生成倒排索引是由字段的index属性控制的
Elasticsearch底层用的是Lucene的API,Elasticsearch之所以能完成全文搜索的功能就是因为存储的有倒排索引
_all字段:顾名思义,_all字段里面包含了一个文档里面的所有信息,是一个超级字段。(6.X以上已默认禁用)
- 以图中的文档为例,如果开启_all字段,那么title+content会组成一个超级字段,这个字段包含了其他字段的所有内容,当然也可以设置只存储某几个字段到_all属性里面或者排除某些字段。
- _all字段默认是关闭的,如果要开启_all字段,索引增大是不言而喻的。_all字段开启适用于不指定搜索某一个字段,根据关键词,搜索整个文档内容
关键字高亮实质上是根据倒排记录中的词项偏移位置,找到关键词,加上前端的高亮代码。这里就要说到store属性,store属性用于指定是否将原始字段写入索引,默认取值为no。
- 如果在Lucene中,高亮功能和store属性是否存储息息相关,因为需要根据偏移位置到原始文档中找到关键字才能加上高亮的片段。
- 在Elasticsearch,因为_source中已经存储了一份原始文档,可以根据_source中的原始文档实现高亮,在索引中再存储原始文档就多余了,所以Elasticsearch默认是把store属性设置为no。
注意:如果想要对某个字段实现高亮功能,_source和store至少保留一个
Flag
- Flag:ES手工创建索引时,需要指定主键字段吗?
- Re: 不用,示例 :插入 curl -X PUT 'localhost:9200/accounts/person/1' -d '{........}' 其中: 1 是该条记录的 Id。每一个 doc 都有一个全局唯一的 doc_id,这个 doc_id 可自定义,也可以让ES自动生成。
- Flag : searchable / aggregatable / analyzed / excluded / selectable ?
- Flag: ES中默认的哪些类型字段开启了列存储?倒排序索引?
- Re: 列存储:除了 text 字段,默认所有字段开启列存储。
- 倒排序索引:默认所有字典开启倒排序索引存储,当字段类型为text时,存储的是分词后的结果,即多个term.
- Flag: 如上图在Kibana中看到的结果中fields是.....?
- Flag: 订单结构手工Mapping 定义的Schema,为什么在Kibanan无法全文搜索?高级过滤里面的包含? 模型匹配? 与 text 类型字段全文搜索?
- Flag:
参考资料
- https://elasticsearch.cn/article/6178
- https://blog.csdn.net/justlpf/article/details/106694471
- https://elasticsearch.cn/article/86
- http://www.kailing.pub/article/index/arcid/73.html
- https://www.cnblogs.com/chong-zuo3322/p/14037214.html
- https://blog.csdn.net/helllochun/article/details/52136954
- https://www.cnblogs.com/sanduzxcvbnm/p/12157453.html
- https://blog.csdn.net/napoay/article/details/62233031

 浙公网安备 33010602011771号
浙公网安备 33010602011771号