ChatGLM3-6B模型分析
ChatGLM3是清华、智谱2023年开源的一款大模型。ChatGLM3-6B模型代码,目前还在研读中,尚未全部读完。
图1为ChatGLM3-6B模型简图,其结构基于Transformer Encoder架构的Encoder,大体上与BERT架构类似。ChatGLM3实现模型架构时,已预置支持P-tuning v2微调结构,图7中的PrefixEncoder,负责将若干Prefix Tokens映射到各GLM Block层的输入层,并与上一个GLM Block层的输出结合为当前GLM Block层的输入。后续各落地场景数据,只需通过P-tuning v2微调Prefix encoder即可。
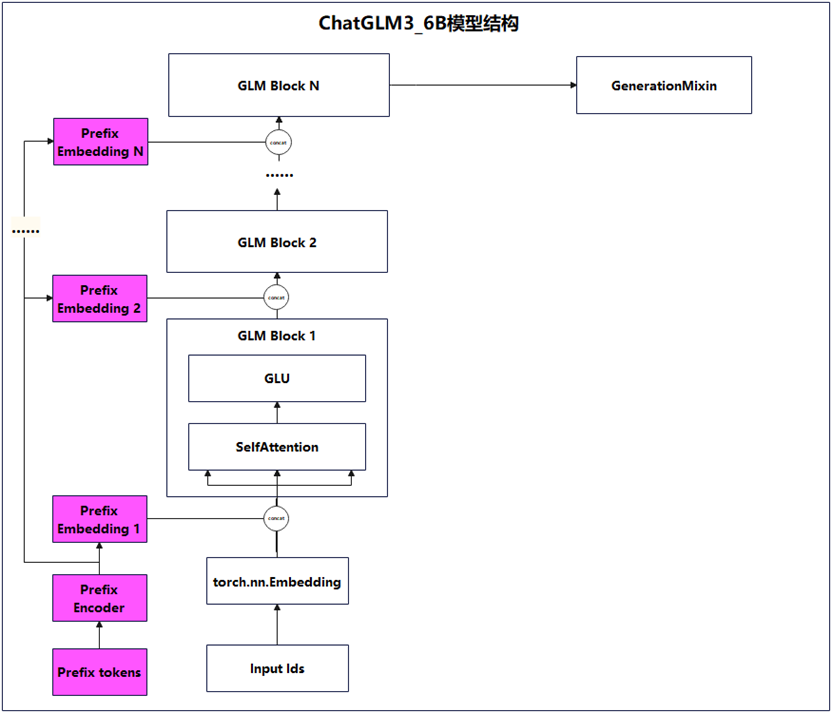
图1 ChatGLM3-6B模型简图
1、算法论文及代码
- 论文
《General Language Model Pretraining with Autoregressive Blank Infilling》
https://arxiv.org/pdf/2103.10360
- 代码
https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
2、P tuning-v2微调机制
ChatGLM3模型内置支持P-tuning v2微调,图7中最左边一列始从Prefix tokens,然后自底向上Prefix Embedding X,这条支线是为后续微调ChatGLM3大模型,预置的微调结构。
图2以第X层GLM Block为例,更为详细地描述P-tuning v2微调是如何实现的,图2中的Prefix序列有2个token:(t1,t2),经由PrefixEncoder编码后,得到一个维度为[2, num_layers*hidden_size*2]的Prefix序列矩阵,第1个维度取值2,表示有2个token,即t1和t2,第2个维度取值,表示在每一层GLM Block,都会有2个(t1, t2)的Prefix序列,其中第1个(t1,t2)是输入给k矩阵的,而第2个(t1, t2)是输入给v矩阵的,且每一个t1、t2,其向量长度为hidden_size。
从图2可知,ChatGLM3的每一层GLM Block,均可微调其输入中的k矩阵和v矩阵。由于引入了更多的微调参数,P-tuning v2相较P-tuning v1只能微调第一层GLM Block,其表达能力和微调效果,理论上会好很多。

图2 ChatGLM3之P-tuning v2实现原理
3、LoRA微调
ChatGLM3除了“天然”支持P-tuning v2微调,还支持LoRA微调,但LoRA微调是通过peft库实现,即Parameter Efficient Finetune。
4、模型量化
ChatGLM3在加载模型时,可动态地进行4位或8位量化。ChatGLM3实际执行量化的代码,是由C/C++编写,并将编译后的可执行代码做BASE64编码,然后将base64编码结果通过硬编码的方式,写死在ChatGLM3的实现python代码中,即图3中的quantization_code变量存储的字符串,即量化代码字节流的base64编码。
将quantization_code值经由Base64解码和BZ2解压缩后,得到一串字节流,见图3中右下角的命令行区域。
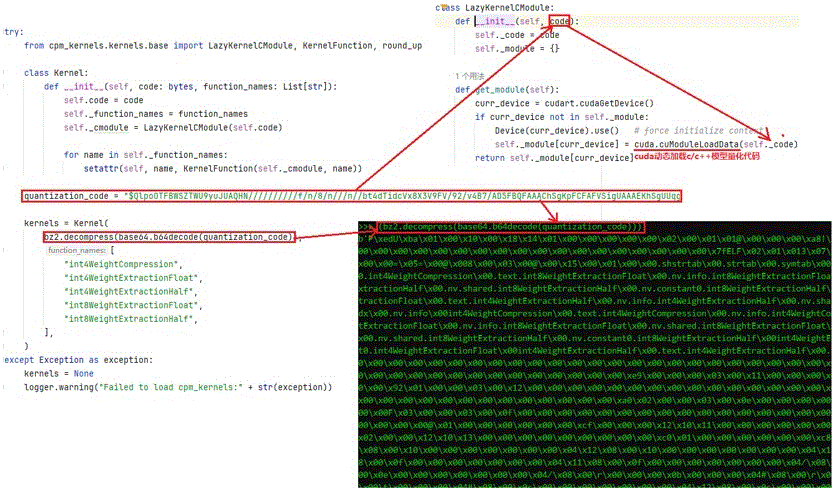
图3 ChatGLM3加载量化代码原理

关注更多安卓开发、AI技术、股票分析技术及个股诊断等理财、生活分享等资讯信息,请关注本人公众号(木圭龙的知识小屋)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号