BERT模型分析
研读BERT代码,是因为BERT作为大模型起源鼻祖,比GPT起源还早,弄明白其算法思想和其主体代码具体实现逻辑,有利于理解现行流行大模型为何演化为如今这样。
1、算法论文及代码
- 论文
《BERT Pre-training of Deep Bidirectional Transformers for Language Understanding》
https://arxiv.org/pdf/1810.04805
- 代码
https://github.com/%20google-research/bert
2、算法模型
图1为BERT模型简图,仅展示主要组件及其间的关系。
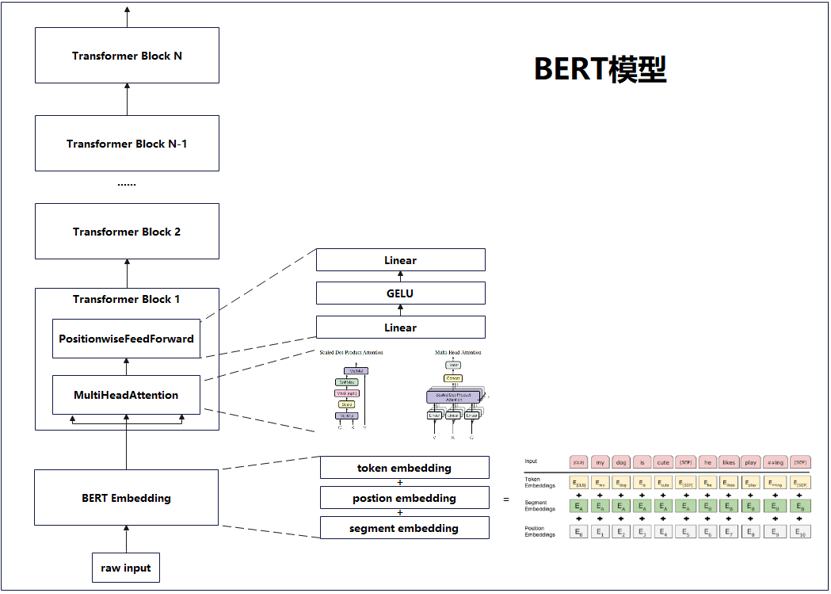
图1 BERT模型简图
BERT模型主要是由多个Transformer Block构成,BERT默认配置有12个Transformer Block,而Transformer Block内部主要的计算是多头注意力计算,每一个Block为标准Transformer的一个Encoder,即BERT模型主体架构基于Transformer Encoder。
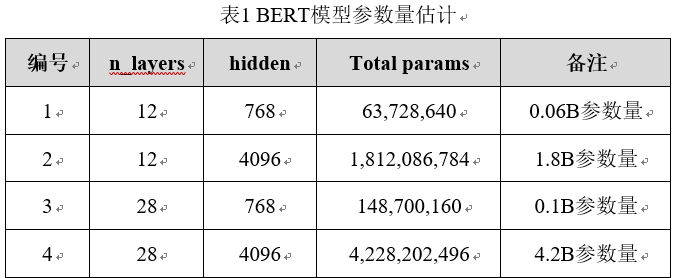
图2为BERT默认配置,粗略预估其参数量公式如下,其中ffw_params为TransformerBlock中多头注意力计算之后的PositionWiseFeedForward:


图2 BERT默认配置
表1为BERT模型在Transformer Block层数及隐藏层神经元大小取值不同时,根据式1计算,得到最终总模型参数量的差异对比。
BERT另一个比较有特点的是对原始输入的embedding操作,从token、position、segment三个维度提取原始输入中的信息,其中,token embedding即词嵌入,postion对输入信息的每个位置进行编码,segment对输入信息划分为不同的部分,每个部分有其唯一的段落编码。
3、模型预训练
相较以前的中小模型,BERT模型的参数量比较大,所以需要大量的数据进行训练,为了减少标注数据的成本,BERT采用自监督的模式进行训练。
图3为BERT的预训练框架,为了较好地训练BERT的自然语言理解能力,BERT特别定义了一个BERTLM的语言模型,其内包含MLM和NSP两个任务,这两个任务都依托于待训练的BERT语言模型,而用于评价训练效果的TrainingLoss,是MLM和NSP两个任务输出的损失之和,这样就有机地将MLM和NSP结合起来进行训练。
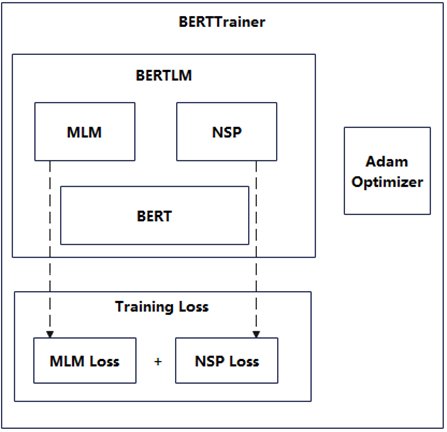
图3 BERT预训练框架

关注更多安卓开发、AI技术、股票分析技术及个股诊断等理财、生活分享等资讯信息,请关注本人公众号(木圭龙的知识小屋)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号