Sora初探
Sora是OpenAI今年初推出的一款文生视频模型,相较于MidJourney这些传统AI绘图工具而言,Sora生成的视频时长更长,视频效果更逼真、更符合物理世界的客观规律。
Sora生成的视频可长达60s以上,较之前的文生视频模型只能生成2~3s视频而言,是个巨大的突破,从Sora官方公布的视频效果来看,其生成的视频效果画质清晰,也很符合物理规律,图1展示了Sora生成视频帧的效果,可见效果是比较逼真的,左图行驶中的车在阳光照射下的影子,右图蜡烛火焰在动物眼中的镜像等,这些细节都做得非常逼真。

图1 Sora生成视频效果
但Sora也有其弱点,比如图2展示的Sora生成视频,播放该视频会发现,随着时间的流逝,画面中生成狼的数量是不断变化的,而且可以比较明显地发现画面中间区域会不断地产生狼,这点就有所失真了。

图2 Sora生成视频效果
此外,Sora还可以将2个视频无缝拼接,以及从图像生成视频。
1、Sora技术架构
Sora目前还没有对公众开放,OpenAI只将Sora发放给一些艺术家使用和测评,所以业内对Sora的技术架构,只是一个推测。
图3展示了业内推测的Sora技术架构,其构成与Stable Diffusion相似,由VAE、LDM、Conditioning三大块构成。Sora的主要技术架构区别在于LDM内部构成,由Clean Latent、Latent Spacetime Patches、Noised Latent、DiT和Denoised Latent阶段构成。
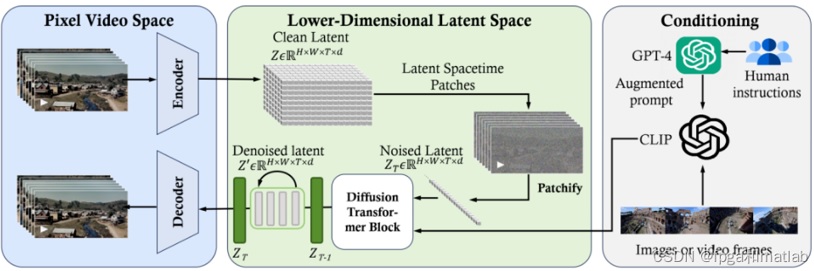
图3 Sora技术架构(业内推测)
1.1 Clean Latent阶段
图4描述了Clean Latent生成阶段的工作流程,视频逐帧排列形成一个视频帧序列,每一帧图像经由Encoder编码,便形成视频在潜空间Clean Latent中间表达。
Clean Latent阶段为视频压缩网络,用于将视频内容“打扫和组织”成一个更加紧凑、更加高效的形式(即降维),这样Sora在处理时就更高效,同时能保留足够的信息来重建原始视频。
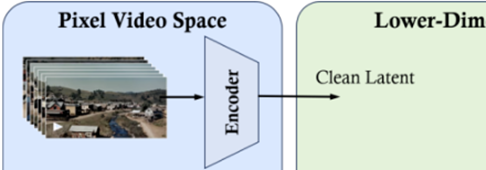
图4 Clean Latent生成阶段
1.2 Latent Spacetime Patches生成阶段
图5描述了Latent Spacetime Patches生成阶段,视频经由Clean Latent阶段后,Sora会将每一个视频帧分成一个一个小块(patch),每个patch记录了视频帧在该位置处的时间和空间信息,就好比视频内容的详细“清单”,以备后续Sora可以针对性地处理视频的每一部分。

图5 Latent Spacetime Patches阶段
1.3 Noised Latent生成阶段
图6为Noised Latent生成阶段对应的流程,该流程为扩散过程的加噪过程,即不断地向视频所有帧对应的时空patch加噪声,直到每帧所有patch均为完全的噪声图像,该阶段的输出为Noised Latent。
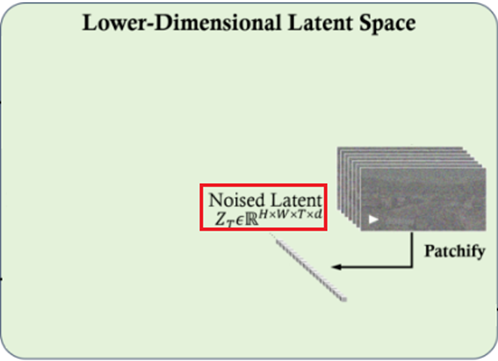
图6 Noised Latent生成阶段
1.4 DiT(Diffusion Transformer)阶段
图7描述了DiT阶段的工作流程,该阶段是最主要也是最复杂的阶段,其主要组件为Diffusion Transformer Block,是一个扩散模型,将扩散模型融入Transformer架构,主要目标是结合Conditioning中的用户指令,将Noised Latent逐步去噪的过程。
该阶段的输出为清晰视频帧图像在Latent空间的表达。
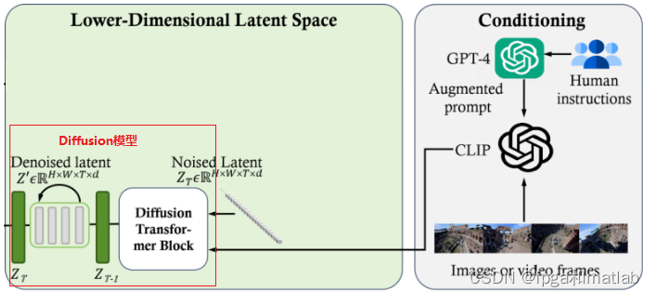
图7 DiT(Diffusion Transformer)阶段
1.5 重建视频帧图像
图8为重建视频帧图像对应的流程,在DiT阶段结束后,会输出一个去噪后的Denoised Latent,将此Denoised Latent传给Decoder,便可重建或生成视频帧中的图像。
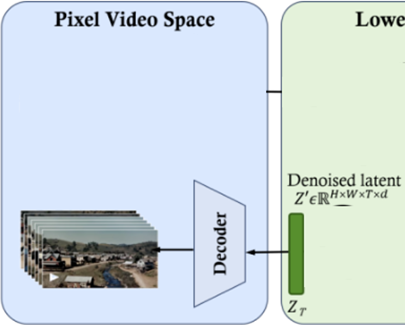
图8 重建视频帧图像
从以上Sora架构分析,Sora架构的构成还是VAE、LDM、Conditioning,基于这些基础模型架构,Sora提出了DiT架构,用Transformer提取特征来预测噪声。
2、总结
AIGC是大模型里的一个重要方向,其技术栈自成一个体系,从最开始的AE、VAE,逐步发展出GAN、Diffusion体系,同时带动了多模态技术的发展,而Sora更是基于Stable Diffusion将AIGC拓展到视频生成领域。

关注更多安卓开发、AI技术、股票分析技术及个股诊断等理财、生活分享等资讯信息,请关注本人公众号(木圭龙的知识小屋)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号