多模态相关技术探讨
Stable Diffusion为实现文生图,引入了Conditioning模块,该模块用于接收图文等多种模态的数据,并将其编码为Embedding空间的向量,使得Stable Diffusion在训练和推理时,可以受到多模态数据设置的条件约束。Stable Diffusion中的Conditioning模块采用CLIP处理多模态数据,如图1所示。
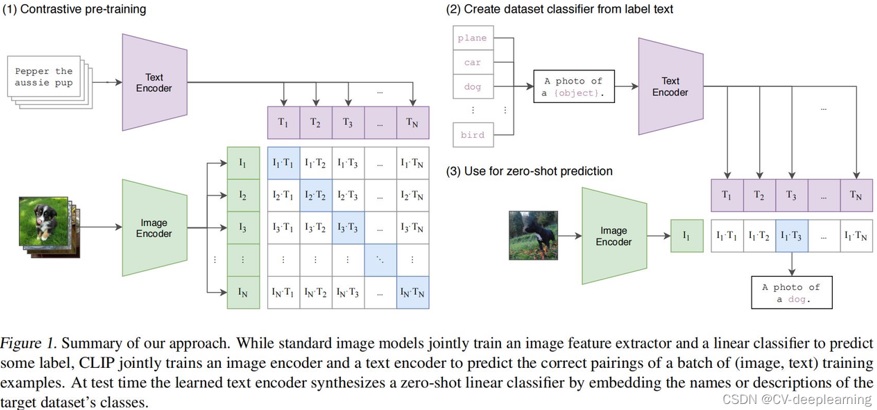
图1 CLIP原理(来源于网络)
图2描述了多模态技术发展路线,可以发现2023年以后,多模态技术井喷式快速增长,其原因是2022年底,OpenAI率先发布商用的大模型ChatGPT-4,其惊艳的效果打动了全世界,致使世界进入大模型时代,而2023年成为大模型元年,全球都在研发各种大模型技术,而多模态的主要应用场景,则为大模型处理多种不同模态的数据,所以大模型的盛行,促进了多模态技术的发展。
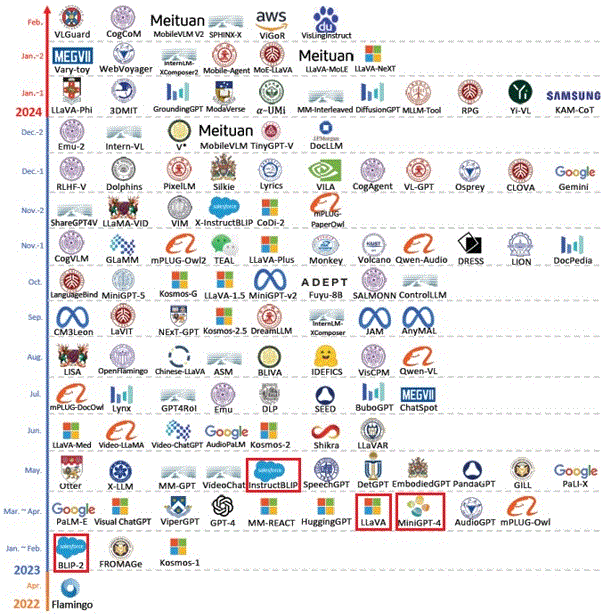
图2 多模态技术发展路线(来源于网络)
本文对BLIP、BLIP2、InstructBLIP、LLAVA和MiniGPT-4的原理,做了一些调研。
1、BLIP
BLIP英文全称Boostrapping Language-Image Pretraining, 中文意为语言-图像关联预训练,其主要目标除了训练提取语言和图像特征的编码器外,还要解决从网上获取的预训练数据存在大量噪声的问题。
图3描述了BLIP的原理,BLIP预训练任务由ITC、ITM、LM任务构成,这三个任务是同时训练的,通过同时施加ITC、ITM、LM三个方面的约束,使得BLIP训练出的图像、语言Encoder拥有更出色的内容理解能力。其中ITC为图片文本对照模型,是为了使文本和图像的内容相匹配,相当于CLIP模型; ITM为图片文本匹配模型,通过提取图片自身的注意力内容、文本本身的注意力内容、图片和文本的交叉注意力内容,从更细致的粒度上匹配图片和文本的内容; LM为训练从图片生成对应文本的能力。
BLIP完整的预训练任务由ITC、ITM、LM三个子任务构成,而BLIP预训练时,会执行两遍完整的预训练,第一次预训练会使用网上下载的图文对资源,得到ITC、ITM、LM的初步预训练版本,然后BLIP会借由LM生成图像对应的文本,并使用ITM过滤网上下载的图文对资源和图像-LM生成文本,得到一个干净的去除噪声后的训练数据集,最后基于去噪后的完整数据集,再执行一遍完整的BLIP预训练任务,图11描述了BLIP过滤网络数据集的原理。
BLIP预训练,通过多任务同步进行以使模型受更多制约、二次训练过滤网络数据噪声的方式,使其训练出的Image-Text Encoder更为出色。
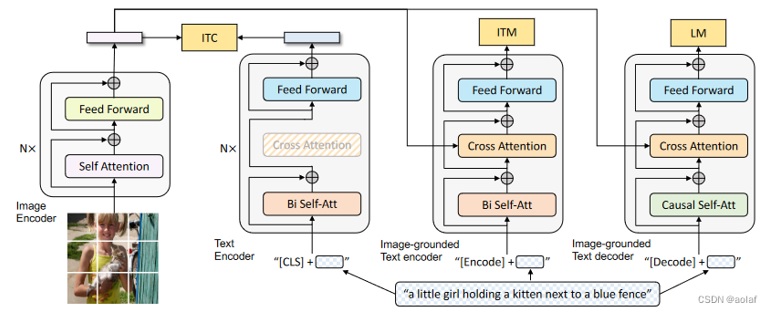
图3 BLIP原理(来源于网络)
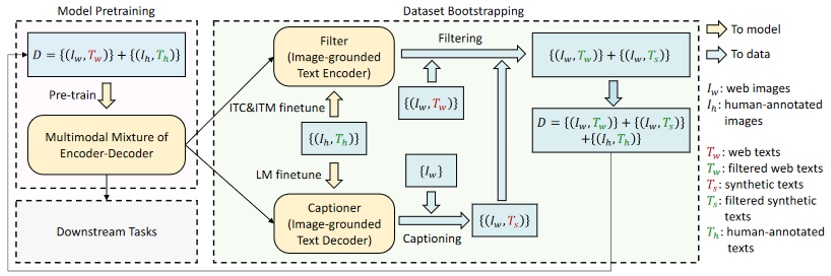
图4 BLIP过滤网络数据集原理(来源于网络)
1.1 ITC任务
ITC任务全称为Image-Text Contrast,是一种图片-文本对照模型,目标为训练Image Encoder和Text Encoder,以提取图像和文本特征。Image Encoder为Transformer的Encoder部分,由多个Transformer Encoder Block构成,Text Encoder为Transformer的Decoder部分,但其Cross Attention模块在ITC任务下是禁用状态,如图5所示。
ITC任务相当于Stable Diffusion的CLIP模型,其主要工流程有三步:
1)提取图像特征
图像先经由ViT模块转换为序列数据,序列数据随后进入Image Encoder,在Image Encoder内部会对序列数据计算自注意力,以获取图像关注点,后续会经由多个Transformer Encoder Block重复前面的计算操作,最终会提取出一个较优的全局特征。
2)提取文本特征
文本经由Tokenize和Embedding操作,转换为Embedding序列,然后在Embedding序列前增加一个[CLS]以表示序列的全局特征,[CLS]表示该全局特征用于分类任务。随后序列会进入Text Encoder内部,在Text Encoder内部会通过自注意力获取序列的全局特征。
3)图文特征对照
提取出图文特征后,就像CLIP那样匹配图文特征,最大化正样本间的匹配,最小化负样本间的图文相似度。
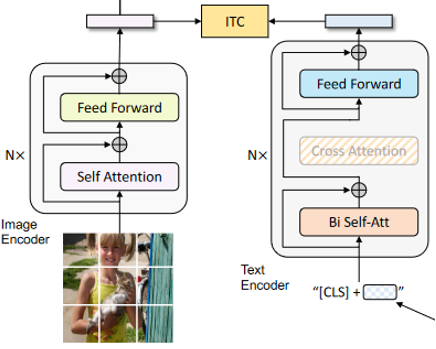
图5 ITC任务
1.2 ITM任务
ITM任务全称为Image-Text Match,也是为匹配图文信息而设计,与ITC不同的是ITM通过计算图文之间的交叉注意力,在更细粒度的内容上,去匹配图像和文本,图6描述了ITM任务的原理。
图5左边为ITC任务的Image Encoder,右边为ITM任务重点训练的基于图像的Text Encoder,该Text Encoder会计算输入文本和图像的交叉注意力,以在更细粒度的层面判断文本图像是否匹配,ITM任务的输出是0或1,即图像和文本是否匹配,该任务后面会作为Filter,以过滤网上下载的图文信息和生成的图文信息。
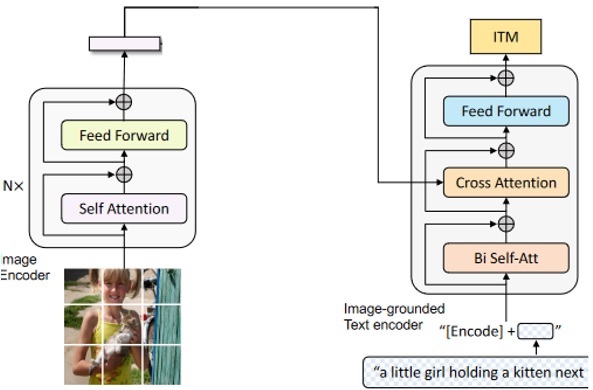
图6 ITM任务
1.3、LM任务
LM任务英文全称为Language Model,本质是Transformer的Decoder,根据Image Encoder提取的输入图像信息,生成对应的文本,但在训练时,还需借助Teacher Forcing技术,输入标签文本,标签文本经由Tokenize和Embedding后,需计算标签文本自身的注意力信息,这里计算注意里有个Causal Self-Att,意为因果自注意力,其本质就是Transformer里的文本mask,因为是生成式任务,需规避未来函数,即当前生成的文本,只能参照在其时刻之前已生成的文本,并计算当前文本和已生成文本之前的注意力,之后通过Cross Attention计算与输入图像的特征间的交叉注意力,以此交叉注意力特征作为生成文本的根据,图7描述了LM任务的原理。
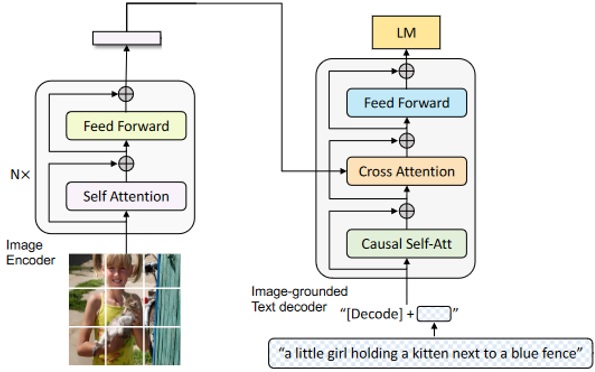
图7 LM任务
2、BLIP2
BLIP2的提出,从多模态技术发展时间线来看,其出现在2023年上半年,这个时间点恰巧在大模型暴发的时点,正是出于看到OpenAI ChatGPT优异的生成能力,BLIP2在BLIP的基础上,将大语言模型引入并替换BLIP中的LM模型,以期待通过大模型优异的生成能力,以生成更丰富更贴合输入图像的文本表达。
图8描述了BLIP2总体原理框架,可见BLIP2使用大模型作为Decoder,以生成丰富的文本表达,此外,BLIP2引入Q-Former结构,因为BLIP版本提取的图像特征,只是Image Encoder自认为重要的特征,而在实际的任务中,这些提取的图像特征并不是对应文本所关注的,所以BLIP2 Q-Former结构引入了Queries序列,用来指示应该提取哪些图像特征,以使提取的图像特征更有针对性。
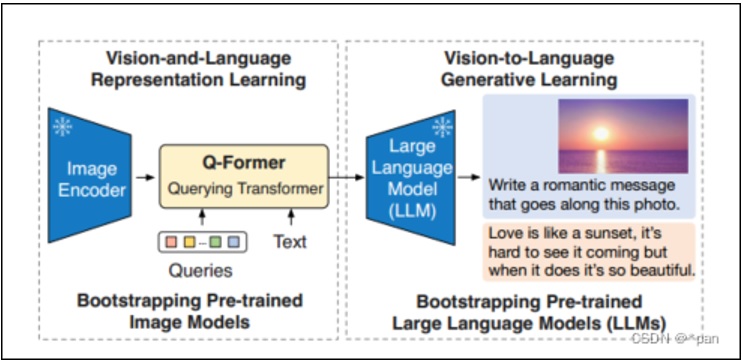
图8 BLIP2总体原理(来源于网络)
2.1 Q-Former结构
第一代BLIP的三个预训练任务ITC、ITM、LM(ITG),在第二代BLIP2里,被调整到Q-Former里,功能原理与BLIP基本一样。
Q-Former与BLIP较大的不同,是引入了一个Learned Queries序列,在其和Input Text输入文本序列做双向注意力计算后,以确定对当前图像应该获取哪些部位的信息,之后Learned Queries便有针对性地与Input Image做交叉注意力计算,以获取当前图像特定部位的信息,之后的ITC、ITM、ITG流程与第一代BLIP基本相同。ITG流程采用LLM输出最终生成文本。
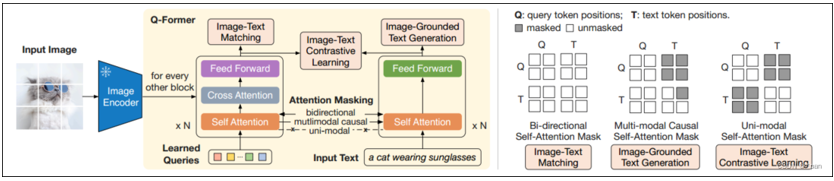
图9 Q-Former原理(来源于网络)
2.2 Learned Queries
Learned Queries是一个参数序列,序列长度表示有多少个query,其中每个query都是可学习的,此外,Learned Queries序列长度可配置的。
Learned Queries序列的值表示图像的哪些区域的特征应该被提取,以图10为例,一幅拍有猫照片,被划分为4*4个patches,而Learned Queries序列长度为5,这5个query指示Q-Former应该提取图像中最重要的5个patch,图10中绿色的query提取图中绿色区域的patch,蓝色的query提取图中蓝色区域的patch,其他的以此类推。
通过Learned Queries,Q-Former能够更有针对性地提取图像中关键区域的特征。

图10 Learned Queries功能示意
3、InstructBLIP
InstructBLIP是BLIP系列的第三步曲,基于BLIP2优化而来,优化点主要有两个:
1)引入Instruction实时指导Queries提取特征
BLIP2基于BLIP,引入了Learned Queries,以提示模型应该提取输入图像哪些部位的特征,相较BLIP在性能上有了较大提升,但并不具有普遍适用性,如果任务发生变换,Q-Former往往需要重新训练,因为不同任务的数据,其图像中关键内容所在区域是不 同的。
为了实现像Java那样,编译一次,处处运行,InstructBLIP引入了Instruction机制,在训练和推理时,Instruct指令实时动态调整Q-Former提取的图像特征,以解决BLIP中Image Encoder不能随任务的变化,而动态调整其从图像中抽取的内容特征,无论任务数据如何变化,只要提供合适的Instruct指令,InstructBLIP就能提取到图像中正确位置的特征,实现了训练一遍便可处处部署和推理。
2)引入Fully Connected投影层
将数据从Q-Former空间映射到LLM空间,使数据表达更符合LLM空间特点,这种投影机制也应用在LLAVA、MiniGPT-4。
图11展示了InstructBLIP的原理,引入Instruction动态引导Q-Former提取输入图像的特征,也就是说Instruction发生变化,提取出的图像特征也发生相应的变化,这一功能与Stable Diffusion文生图类似,提示词文本发生变化,生成的图像也相应变化。
Instruction与Queries在Q-Former内部通过注意力融合其相互间的特征,然后影响Queries与Image Embeddings的交叉注意力计算,从实现提取Instruct指令所需的图像特征。
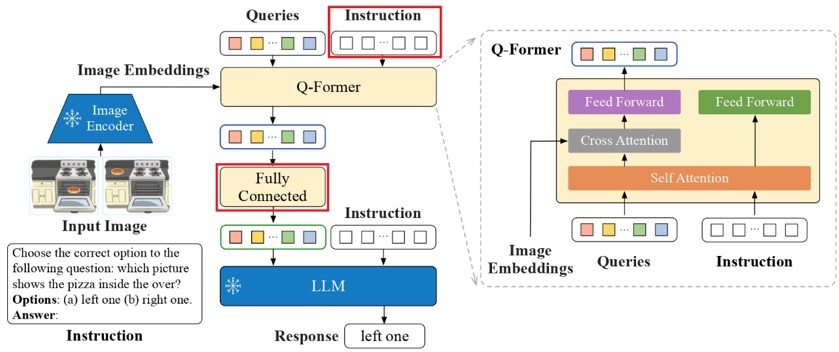
图11 InstructBLIP原理(来源于网络)
4、LLAVA
LLAVA也是一种多模态模型,其模型架构和BLIP类似,包含Vision Encoder、Projection和Language Model三层,Vision Encoder一般采用CLIP提取图像特征,Language Model用于生成文本,Projection是投影层,负责将提取的图像特征映射到Language Model所在的空间,此外Language Model还接受Instruction指令,该指令引导Language Model应该提取图像哪些位置的信息,这点与InstructBLIP比较相似,最后投影后的图像特征和Instruct指令拼接,并作为Language Model的输入,最终会得到一个响应输出。
图12描述了LLAVA模型的原理。
LLAVA模型比较简洁,用一个Projection层将视频特征映射到文本空间,再利用Instruct文本动态引导模型关注图像内容的焦点,使得LLAVA模型具有较好的普遍适用性。
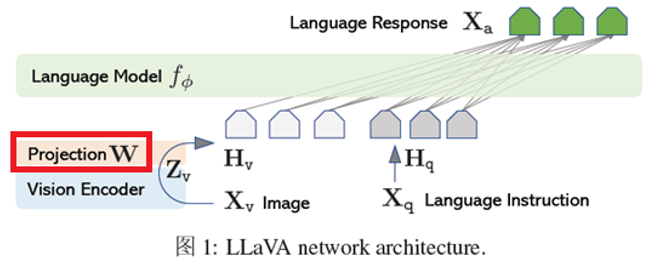
图12 LLAVA原理(来源于网络)
5、MiniGPT-4
MiniGPT-4的模型结构与BLIP2相似,都基于Q-Former和LLM,但其相较BLIP2有所改进,引入了一个Linear Layer作为投影层,以联结被冻结的视频特征提取模块和LLM,投影层的功能也是将特征从视频空间转换为语言模型空间,此外,MiniGPT-4也支持Instruction指令动态引导LLM提取图像相应区域的特征。
图13描述了MiniGPT-4的原理。
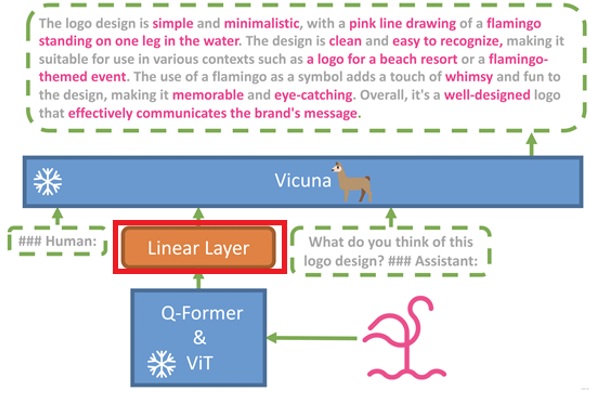
图13 MiniGPT-4原理(来源于网络)
通过以上比较的6个模型,InstructBLIP、LLAVA、MiniGPT-4模型是比较相似的:
- 都引入LLM以增强其语言理解和生成能力;
- 都引入Projection层将视频空间特征映射到语言模型空间;
- 都使用Instruction动态引导模型提取图像特征。
而InstructBLIP是BLIP、BLIP2不断进化的版本,而BLIP又是对CLIP的增强,图14描述了这6个多模态技术发展关系。
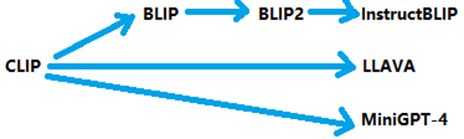
图14 多模态技术发展路线

关注更多安卓开发、AI技术、股票分析技术及个股诊断等理财、生活分享等资讯信息,请关注本人公众号(木圭龙的知识小屋)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号