Stable Diffusion技术路线发展历程回顾
图1描述了Stable Diffusion模型的发展历程,从最初的AE(Auto Encoder),逐步发展到DDPM、VQVAE、LDM,并最终产生了Stable Diffusion。从技术路线上看,Stable Diffusion由2条技术路线汇聚而成,一条是路线1:AE -> VAE -> DDPM,另一条是路线2:AE -> VQVAE -> LDM。路线1主要解决生成图像质量不高的问题,而路线2解决的是生成图像速度慢的问题,而Stable Diffusion结合了路线1和路线2的研究成果,可较快地生成较高质量的图像。
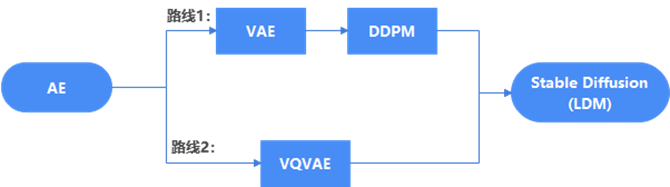
图1 Stable Diffusion发展历程
1、AE的问题
AE是一种比较早期的图像压缩和生成模型,是一种Encoder-Decoder架构,一幅图像经由AE的Encoder编码后,得到一个中间向量vector,vector即为一幅图像的中间表达,经由Decoder反向解码后,可还原图像。
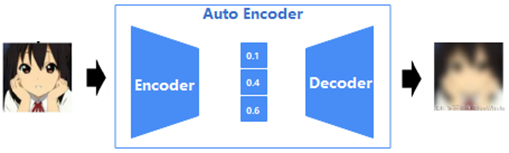
图2 Auto Encoder原理
AE的Encoder可看作是图像压缩过程,而Decoder可看作图像生成过程,中间向量vector即为图像的中间表达,也可理解为压缩后的图像表达,图2描述了图像经AE压缩和生成的过程,由于压缩过程丢弃了比较多的信息,所以还原后的图像相较原图模糊很多。
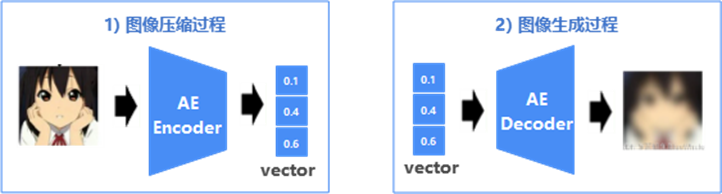
图3 AE图像压缩和生成过程
AE作为早期的图像生成模型,其学习到的知识更像是一种具体的数据映射规则,其中AE Encoder学的是图片到向量的映射,而AE Decoder学的则是向量到图片的映射。AE最大的问题是模型过拟合,AE对训练数据学习得比较好,强行记住了训练集数据Encoder后的中间状态,如果来了一个不是训练集的数据,那么效果就比较差。AE另一个问题是还原图片的质量不是太好,比较模糊。因此,便产生了路线1和路线2里的那些技术。
2、路线1:VAE -> DDPM
路线1最大的贡献,是大大提高了生成图像的质量,相较AE更清晰,但计算代价也大为提高,生成图像的速度也更慢。
2.1 VAE
VAE英文全称为Variational Auto Encoder,即变分自编码器,其基于AE发展而来,与AE不同的是,VAE学习的目标不再是强行记忆训练集数据的编码输出,而是学习训练数据集的分布,使得AE过拟合现象有所缓解。
图4描述了VAE原理,与AE的结构比较相似,不同的是VAE编码过程是获取训练集的均值u和标准差σ,然后从正态分布N(u, σ2)上随机采样一个数据,并输入给Decoder做图像生成,即VAE学习的是数据集分布,不再是具体的某几个中间数据状态,具有一定的泛化能力。
VAE虽然缓解了AE过拟合的问题,但生成图像的质量,仍然比较模糊,可能是因为VAE训练损失函数只施加以下两个约束:
1)重建图像和原图尽量相似;
2)编码器输出N(u, σ2)要与N(0, 1)尽量相似。
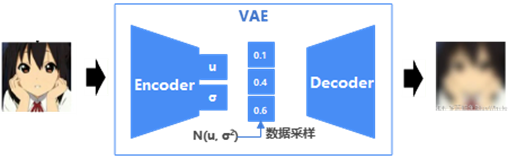
图3 VAE原理
2.2 DDPM
DDPM英文全称是Denoise Diffusion Probabilistic Model,即去噪扩散概率模型。DDPM作为扩散模型的鼻祖,得益于热力学启发,提出了加噪声的扩散过程和预测噪声的推理过程,图5描述了DDPM的原理。

图5 DDPM原理
- 扩散过程
DDPM扩散过程是一个由T个时间步组成的一个马可夫链,对于马可夫链的某个节点xt,首先会生成一个和输入图像尺寸相同的噪声ϵ,ϵ采样自N(0, 1)的正态分布,然后将上个节点的输出与ϵ进行加权融合,以下公式为融合当前噪声和上个结点输出的方式:
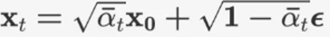
- 去噪过程
该过程也是由T个时间步组成的一个马可夫链,每个马可夫链结点会预测当前步骤要去除的噪声 ϵθ,然后用上个节点的输出加权减去ϵθ,得到当前节点预测的图像内容。
通常使用UNet网络来预测噪声ϵθ,如图6所示,对于预测出的噪声ϵθ,通过loss函数约束,使其尽量逼近扩散过程中对应时间步t所添加的噪声ϵ。
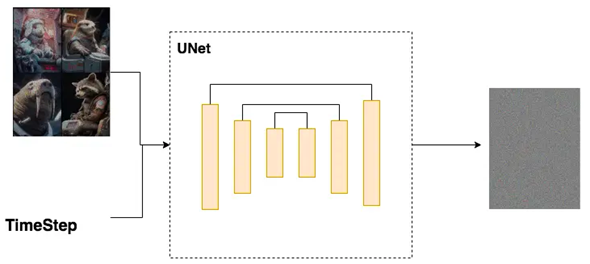
图6 UNet预测噪声
DDPM通过引入扩散过程,解决了AE过拟合的问题,同时通过加噪和去噪过程,学习如何生成高质量图像的手段,所以DDPM比VAE更进了一步,除了解决AE过拟合问题,还能生成高质量图像,但DDPM是按原图尺寸进行加噪和去噪,所以其计算代价是非常高的,生成图像的速度会比较慢,尤其是大尺寸图像。此时,就进入技术路线2,以期突破生成图像速度慢的性能瓶颈。
3、路线2:VQVAE
3.1 VQVAE
VQVAE英文全称Vector Quantised Variantioal Auto Encoder,即向量量化变分自编码器,其原理是通过将Encoder后的向量离散化,然后再经由Embedding映射到一个连续空间,从而解决AE过拟合的问题,其最大的贡献是提出将输入图片经由Encoder压缩为一个尺寸更小的图像,后续解码器对该小图像解码,以最终还原原图,图7描述了VQ-VAE的原理。
通过VQ-VAE将大图像压缩为小图像,后续操作都施加在小图像上,计算代价就大为减少,这点恰好弥补了DDPM生成图像慢的短板。
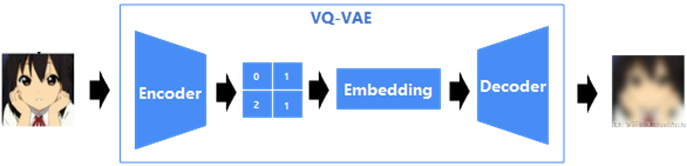
图7 VQ-VAE原理
4、Stable Diffusion模型
结合路线1和路线2模型的优劣,取长补短,最终诞生了Stable Diffusion模型。在Stable Diffusion模型里,提出了一个叫Latent Diffusion Model的潜空间扩散模型,如图8所示。
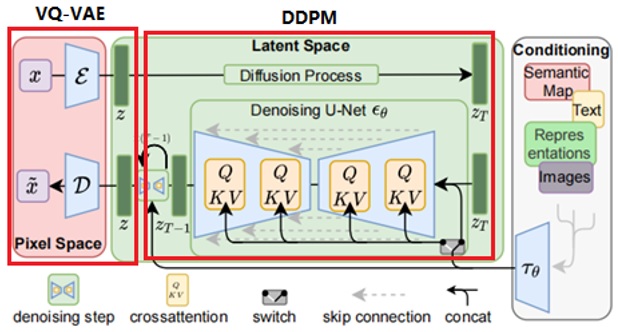
图8 Stable Diffusion原理(LDM)
LDM由Pixel Space、Latent Space和Conditioning三个部分构成,Pixel Space借鉴了VQ-VAE的思想,通过Encoder将输入图像压缩为一个64*64*4的潜空间里的小图像,以减少计算代价,并通过Decoder将潜空间里的小图像还原为原尺寸的大图像; Latent Space大体等同于一个DDPM,用于对潜空间的64*64*4的小图像进行扩散和反向去噪; Conditioning主要是一个多模态处理模块CLIP,对各种图文信息进行抽取,以供图像去噪过程参考如何生成噪声。
可见LDM本质是由技术路线1的DDPM和VQ-VAE融合而成,然后新增一个条件式生成图像模块Conditioning,因此,理解了DDPM和VQ-VAE的概念,理解Stable Diffusion就非常简单。

关注更多安卓开发、AI技术、股票分析技术及个股诊断等理财、生活分享等资讯信息,请关注本人公众号(木圭龙的知识小屋)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号