大模型导论
1、模型为什么越大,性能和泛化越好?
在AI领域,对需要解决的业务问题,将其视为满足一定条件的数据分布,先通过特征工程的方式,从业务问题中拆解出有哪些特征,然后通过分层采样的方式,均匀抽取出一定量的样本,每个样本包含业务问题所对应的特征,以此形成训练集,之后便可选择模型进行训练。假设某个业务问题,它的预测目标为一个简单的数值,而模型特征个数从0到N不等,那便可以用平面可视化的方式,展示模型复杂度对预测效果的影响,参见图1,图1中每个蓝圈表示训练集中的一个样本点,红色曲线表示模型预测值形成的曲线,绿色曲线表示其真实分布曲线,M表示模型有多少个参数。
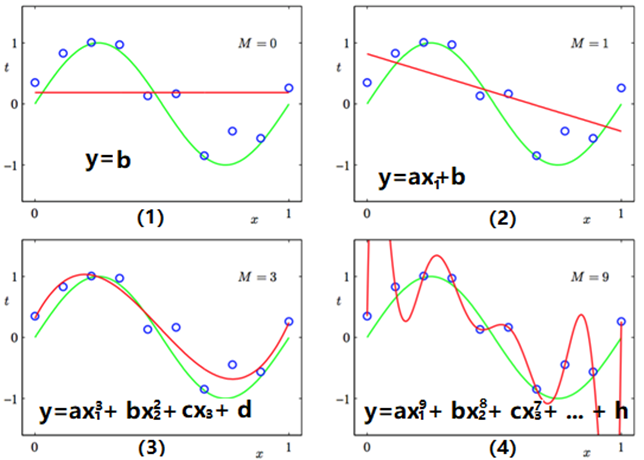
图1 不同复杂度曲线拟合效果对比
图1中右上角的M,表示模型有几个参数,而模型采用的是多项式曲线,形如式1:
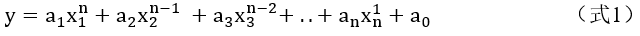
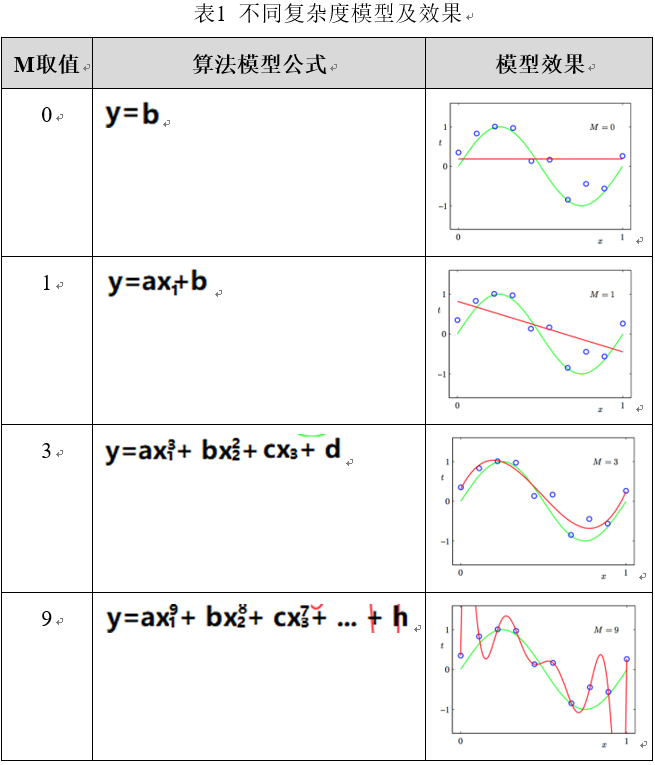
表1阐述了M取值不同时,从式1派生出的不同模型公式及其拟合效果,可见M=0或1时,由于模型过于简单,产生欠拟合状态,而M=3时,模型基本可以较好拟合训练样本所有的点,而M=9时,则严重过拟合。
从图1中可看出一种趋势,模型参数越多,模型表达特征的能力越强,其能拟合的曲线可越复杂,这一点也是大模型效果好的基本原因,因为大模型含有Billion级以上的参数数量,其表征能力是非常非常之强大,理论上能拟合宇宙中的万事万物,因为宇宙万物定律本质皆数学,皆可近似抽象为一个数学模型,哪怕中国传统的风水学、相命学等玄学无不如此,区别在于模型复杂程度不同。
当然,模型也不是越大越好,模型好坏在于模型复杂度和任务复杂度的匹配,一般来说,简单任务用简单模型,复杂任务则用复杂模型。而对于复杂任务,也不一定只能用复杂模型,如果复杂任务可拆解为数个简单任务,那也可以用数个简单模型解决数个简单任务,然后在流程上进行组合编排即可,这就回归到ImageModelFlow流程编排的范畴。
2、大模型的分层结构
大模型体系可分为三层:通用大模型层、行业大模型层和细分场景大模型层。
基于世界上各种各样的通用知识,训练出通用大模型,然后基于行业通用知识,对通用大模型进行微调,训练出行业大模型,之后便针对行业细分场景,结合行业某个垂直领域的专业知识,训练出针对某个细分场景解决方案的细分场景大模型。
除了通用大模型会从0到1构建一个通用大模型,也可基于开源通用大模型微调,行业大模型、细分场景大模型,只需基于其上层大模型微调即可。
2.1 通用大模型层
通用大模型,其用于训练的数据皆为通用知识和经验,好比一个学生十几年寒窗苦读,经过小学、中学、大学、硕士、博士几个阶段,学习和积累了大量的人类社会中的常见通用知识,对通用知识和经验是比较了解的。
当今大模型主流底座是Transformer,不同流派采用的Transformer组件也有所不同。基础大模型通常采用多任务且无监督方式来进行训练,因为大模型参数量巨大,Billion级起步,且复杂度非常高,所需的训练数据相应也非常大,否则就分分钟欠拟合状态,所以不能只靠人工标注的有监督训练,有限的成本预算是cover不住的。
通用大模型包含NLP通用大模型、CV通用大模型和多模态通用大模型,NLP通用大模型一般采用MLM(Masked Language Model)方式进行预训练,而CV通用大模型可采用强监督学习(Supervised Learning)、对比式自监督学习(Contrastive Language-Image Learning)、图文对比式学习(Image-only (Non-) Contrastive Learning)和生成式自监督学习(Masked Image Model)。
Supervised Learning强监督学习就不用说了,Masked Image Modeling和BERT的MLM子任务类似,而Contrastive Language-Image Pre-training图文对照学习,因被Stable Diffusion的Latent Diffusion Model采用以进行图文多模态信息抽取,似乎其知名度是其中最高的。
2.1.1 Contrastive Language-Image Pre-training
Contrastive Language-Image Pre-training为图文对照学习,简称CLIP,是一种文生图模型,也可输入文本查询相关的图像,因之前学习Stable Diffusion原理和源码时,发现其LDM潜空间模型会引用CLIP抽取多模态的限制条件描述,在去噪过程中通过注意力计算,获取预测当前时间步噪声所需的条件约束信息,以此有条件地生成相应的图像。
图2描述了CLIP预训练的原理,以及Zero Shot对未知数据集进行图像分类的原理。
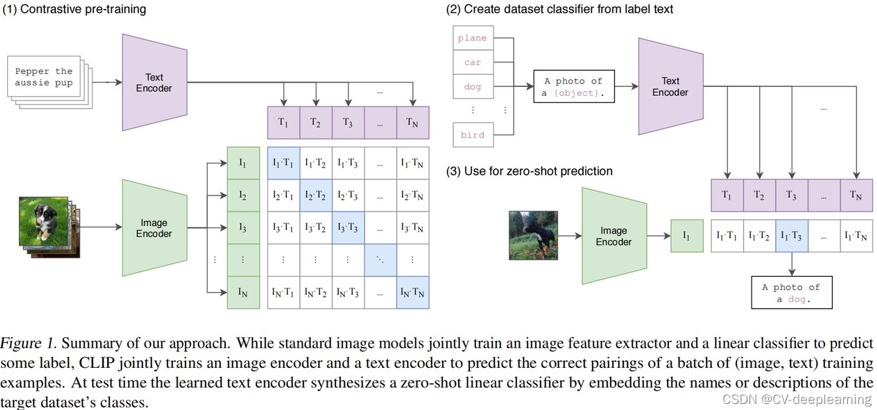
图2 CLIP原理(来源于网络)
- CLIP预训练
CLIP预训练需要大量的图文对样本,每个样本包含一张图片和一段对该图片的文本描述,预训练时,图片经Image Encoder转换为一组向量Ii,而图片对应的文本经Text Encoder转换为一组向量Ti,一个批次的图文对经Image Encoder和Text Encoder编码转换,便可得到(I0, T0)、(I1, T1)、…、(Ibatch_size-1, Tbatch_size-1)个元组,把这些元组看成一个个二维坐标点,便可组成一个图4中左图的对照矩阵,I为纵坐标,T为横坐标,只有对照矩阵对角线上的点才是正样本,其他位置的均为负样本,所以在构建损失函数时,尽量最大化对角线上Ii * Ti的值,同时最小化其他位置Ii * Tj的值即可。
- CLIP Zero Shot分类图片
有了CLIP预训练模型,其他的下游任务就非常好办了,比如要对图像进行分类,哪怕这些分类是预训练时完全没见过的分类,都是没问题的,CLIP这种Zero Shot的神奇能力,关键在于其Text Encoder和Image Decoder,在预训练时,Text Encoder已经阅文本“无数”,而Image Decoder也阅“图片”无数,所以在陌生文本和图片来了之后,它们两个都能提取出图片或文本的特征,本质是一种Embedding信息。所以,对于图片分类任务,将不同的分类标签通过prompt组成N句话,N句话经过Text Encoder转换为N个文本Embedding向量,然后将分类图片输入Image Encoder,得到图片的Embedding向量,N个文本Embedding向量与图片Embedding向量求相似度,相似度最高的即为对应的分类。
- CLIP引发的多模态思考
从本人研究的感悟看,多模态数据,无论图片、文本、语音数据等,无论其原始数据结构是如何表达的,在多模态里,针对不同种类的数据,会分别建立不同种类的Encoder,比如Image Encoder、Text Encoder等,这些不同种类Encoder的目的或功能只有一个,将不同模态的数据Embedding到同一个高维稠密空间,在这个高维稠密空间里,表征相同含义的向量,它们的相似度或距离就越近,好比NLP中的开源Word2Vec,不同的字、词或token间,如果其语义是相近的,经word2vec映射到Embedding空间后,其间的向量相似度是非常高的,且语义越相近,向量间相似度越高,反之亦然。
更扩展一点说,比如图片和语音虽然数据表现方式不一样,但它们的含义都表示【雨天的海边】,那边经过多模态的不同Encoder进行Embedding后,在高维稠密的Embedding空间内,图片和语音的Embedding向量距离就越近或相似,而无论两个向量它们原来是什么样的表达方式,只要它们的语义或含义是相似的,两个向量间的距离就越近,这一点也为大模型后续的计算奠定了坚实的基础。
多模态是今后AI领域重点方向之一,因为AI产品的发展,会逐步从一次只能接收一种模态的数据,发展为同时接收图片、语音、文本等其他模态的数据,使AI智能体就像人一样,同时能接收视觉、听觉、触觉、味觉、嗅觉的人类五个感官的数据,然后像人一样同时处理五感数据,定会有不一样的效果。
后面会对BLIP、BLIP v2、LLava等多模态模型做点研究,跟进这块技术的发展。
2.1.2 Masked Image Modeling
Masked Image Modeling训练方式,比较类似于BERT的MLM子任务,先将预训练图片通过Vit拆分为多个patch,然后随机将这些patch擦去(masked),然后让模型预测这些masked的patch,是一种无监督的预训练方式,省去了大量标注所需的成本。
2.2 行业大模型
行业大模型,基于通用大模型和行业数据微调而来,因为通用大模型只具有通识能力,对某个行业具体的知识还有所欠缺,所以需要补充些许行业具体知识,再微调训练下即可,好比一个人经过十几年寒窗苦读,大学毕业后,只学到了通用的基础知识,如果要进入社会工作,还需要再补充一些社会上的知识和行业专业技能,AI在这点上和人的经历也是相通的。
2.2.1 大模型微调技术
图3展示了当今大模型主流的微调技术,Lora、Prefix Tuning、P-Tuning/v2等,此外,LangChain在一定程度上,也可视为一种微调手段。
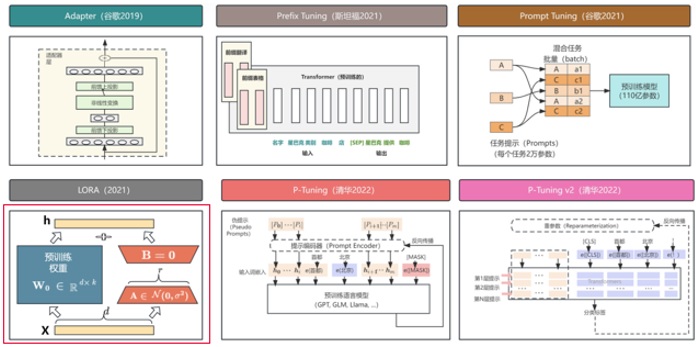
图3 大模型主流微调技术(来源于网络)
1)LoRA微调
LoRA是Low Rank Adaptation的简写,中文名为低秩分解,图4描述了LoRA微调原理。
任何一个深度学习模型,其构成的基本单元包括可训练参数、不可训练且用于持久化存储模型状态的buffer等,微调LLM时只考虑可训练参数,每个可训练参数都会对应一个权重矩阵W,图6中间左侧的W即表示某个可训练参数的权重矩阵,其维度为d*d。
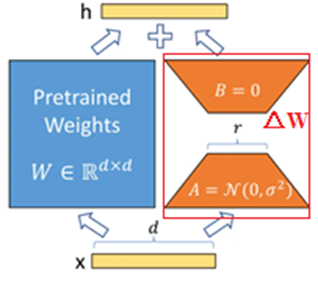
图4 LoRA微调原理(来源于网络)
LoRA微调LLM的思想,是冻结所有可训练参数的权重矩阵W,同时在W旁侧,并行引入一个新的参数调节矩阵ΔW,微调时只调整ΔW的权重值,即新的知识保存在ΔW中,经微调后输出的LLM,其可训练参数的权重矩阵值由W +ΔW共同决定。因为保留了原始大模型的权重,也学到了新的知识,W +ΔW操作使新旧知识通过加法操作进行融合,所以既改进了大模型,也很大程度上避免知识遗忘的问题,而知识遗忘在Prefix Tuning和P-Tuning/v2上却是很明显的,尤其在训练轮次较多的情况下,更为明显。
在具体操作上,Lora引入两个低秩矩阵A和B,构成一条旁路,秩就是线性代数中矩阵的秩,是一种压缩矩阵的做法,减少了很多矩阵参数。A和B矩阵的秩都为r,A矩阵的维度是d*r,B矩阵的维度是r*d,A矩阵相当于一个Encoder,B矩阵相当于Decoder,Encoder对新知识数据进行提炼和内化,Decoder用于生成适用于原始大模型的知识表达。
A*B的维度为d*d,与原始权重W维度相同,可直接矩阵相加进行新旧知识融合。
其实Lora原理就是一个公式:

清华智谱ChatGLM3-6b源码中提供的微调方式就是LoRA,Lora还有一些变体QLoRA等。
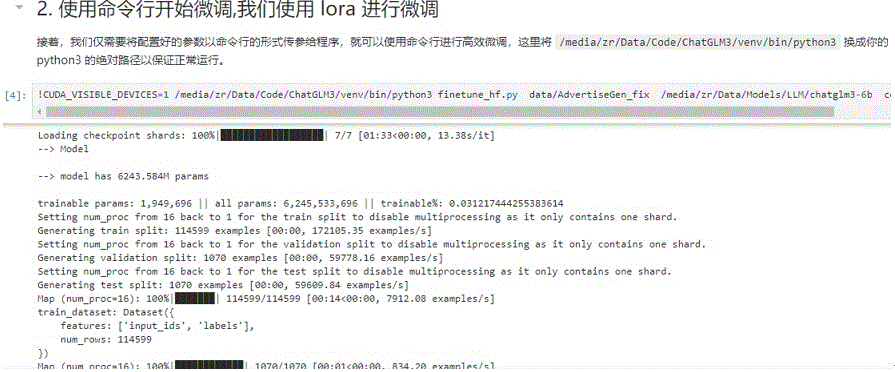
图5 ChatGLM3-6b模型微调demo
2) Prefix Tuning
Prefix Tuning是一种加前缀的微调方法,在模型的每一层加入一定数量的前缀token,如图6所示。在Prefix Tuning刚提出时,只在Embedding层添加前缀token,后面发现任务变得复杂后,Embedding层的prefix token表现力不够,所以拓展到每层都添加。微调时,会冻结除prefix token外的其他参数,仅更新prefix token,由于是迭代梯度下降修改模型参数参数,所以此种方式容易产生知识遗忘的问题。
个人理解这种微调方式,是引入一些prefix token,相当于预留字段,专门保存新数据集的特有知识信息,然后通过相当于向量拼接(Concat)的方式进行信息融合,达到微调的目的,因为每次迭代会冲掉参数原有的信息,所以迭代次数多了后,会有比较明显的原有模型知识遗忘问题。
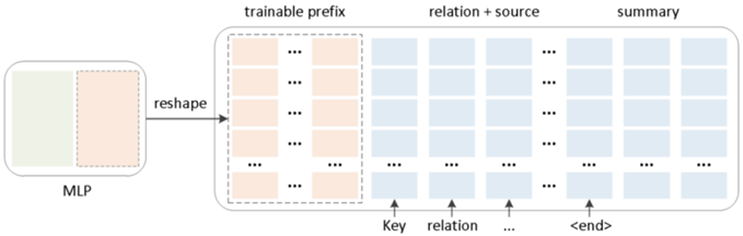
图6 Prefix Tuning原理示意
3) P-Tuning v1/ v2
目前的大模型,都依赖于提供给它的Prompt文本质量,好的Prompt文本,会最大程度发挥大模型的能力,不好的Prompt文本,则无法发挥大模型应有的能力,甚至还会把大模型的缺陷短板给暴露出来。因此,Prompt Engineering(提示词工程)就被提出来了,研发和管理Prompt Template也成为大模型工作的一部分。
提示词工程盛行的现象,和搜索引擎刚刚出来时有点像,早期的搜索引擎还不成熟,对搜索关键字的内容和组织方式也有偏好倾向,然后出现了各种如何组织搜索关键字的tip工程,如今的提示词工程也应该是这种tip工程,随着大模型技术的不断完善,对语义的把握越来越强,提示词工程应该会慢慢退出历史舞台,届时人们随意输入Prompt内容,都能得到期望的结果。
个人感觉造成大模型要靠Prompt Engineering来最大化其能力输出的局面,可能和大模型的结构、训练数据的组成结构、训练方式有关,相对于特定的模型结构、数据结构、训练方式,大模型学到了模型-数据-任务间的一种或几种关联关系,这些特定的关联模式和逻辑,需要特定的Prompt才能完全触发和命中,而不同厂家和品牌的大模型,模型结构、数据结构和训练方式肯定多少不一样,这也说明了为什么不同品牌的大模型,其Prompt Template都不太一样。
如果用过大模型,可能会发现相同含义但不同表达的话语,大模型输出的内容不太一样,质量也参差不齐,比如图7所示,“DataFrame是什么”、“什么是DataFrame”2个不同话术,产生的结果也有明显不同,而P-Tuning就是要解决的问题,就是语义相近的Prompt,尽量产生相近似的输出,至少不要产生互相矛盾的结果。
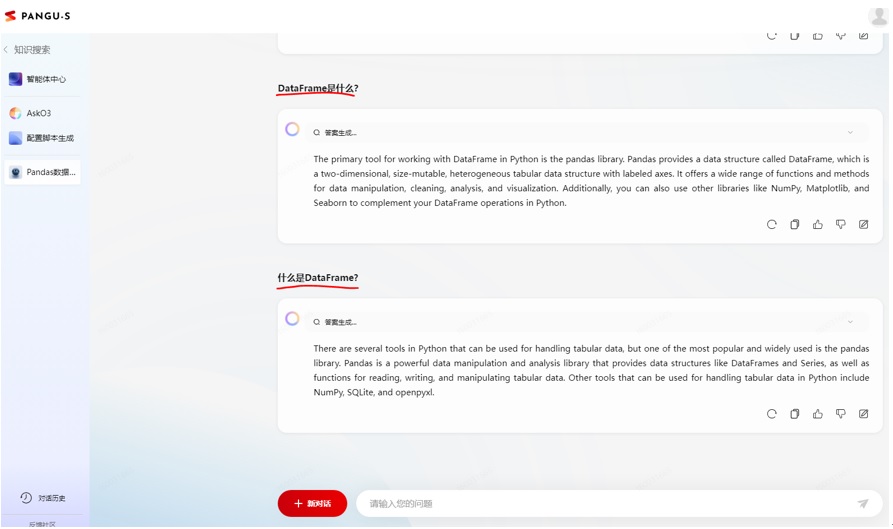
图7 不同话术的效果
图8描述了P-tuning的技术原理,相较于普通的训练方式,P-Tuning在Embedding层之前,引入了一个Prompt Encoder,而在Prompt前后加了一些伪Prompt,Prompt+伪Prompt一起传给Prompt Encoder,Prompt Encoder会在Prompt中挑选出重要的字/词作为anchor输出,其他位置hi的输出为不具特定含义的隐层,输出给Embedding,再到LLM进行训练,然后输出结果反向传播。
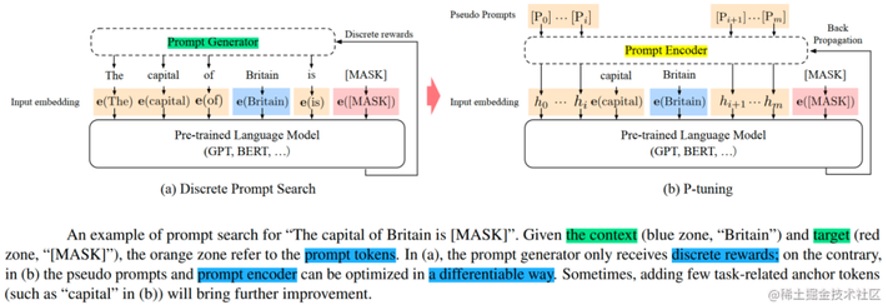
图8 P-tuning原理
P-Tuning v2在P-Tuning的基础上,在transformer每一个Attention Block的Embedding层均做微调,P-Tuning只在第一个Attention Block进行微调,因此v2版本的P-Tuning的表征能力和效果,比v1版本强一些。
4) LangChain
LangChain是一个大模型应用开发框架,用于简化大模型的应用开发,包含Models、Chains、Prompts、Memory、Indexes和Agents六大组件,这里只是强调LangChain相当于微调的功能部分,其他的提示词模板、向量数据库、文档加载器、链、Agents等功能,暂不做说明。
图9描述了LangChain扩展LLM模型能力的原理,首要工作是构建行业知识向量库,即将大模型不具务的行业知识,经由LangChain Loader组件加载进内存,然后通过Text Splitter拆分为一个个Chunk,一个个Chunk经过Embedding组件映射进特征向量空间,然后将Embedding后的chunk向量存入向量数据库,向量数据库可使用VectorStore、Pinecone或Faiss等。值得注意的是,语义相似的chunk,经Embedding后得到向量,其相似度则比较高,反之则比较低,这是后续文本聚类、搜索、推荐等任务的理论基础。
然后就可以基于行业知识向量库,进行知识问答,即用户提问了一个Query,经由Embedding组件将Query映射到特征向量空间,然后将Query的Embedding向量,交由向量数据库匹配最相似的top k个上下文chunk段,匹配策略就是相似度计算和KNN搜索,然后将这些匹配得到的chunk段文本和query文本,基于PromptTemplate构建提示词,提示词再传给LLM,即可完成一轮对话。
可见LangChain方案在一定程度上,不需要finetune LLM,就可使LLM迁移到新的数据集上,知识问答类或类似NLP任务,都可以如此实现。

图9 LangChain扩展LLM模型能力
2.3 细分场景大模型
细分场景大模型,直接基于行业大模型孵化出来,所需数据量和微调成本都很少,可很快地训练出来,这应该是日常工作中,接触最多的一类大模型,也是大模型三层架构中模型数量最多的一层。细分场景大模型层中有众多不同功能的大模型,便组成了一个工具库,面对不同的实际场景,从工具库中挑选合适好用的大模型,往往是比较关键的,如果工具库中的大模型都不满足要求,必要时还是需要收集场景数据,训练新的场景大模型,并添加至工具库。
现实中的场景问题,一般都比较复杂,不太是一个模型就能完全解决的,需要将复杂问题进行拆解,得到一系列简单问题,每个简单问题用适合该问题的模型来解决,最后将多个模型的输出结果进行组装运算,得到最终的计算结果。
3、大模型底层基座
如今众多的大模型,它们的模型底座是Transformer,Pytorch框架已经提供了官方实现的Transformer框架,使得大模型的构建开发更加方便,也更加标准化一点。
3.1 Transformer模型结构
图10描述了Transformer架构简图,Transformer为一种Encoder-Decoder框架,模型左侧为Encoder,模型右侧为Decoder,Encoder和Decoder可以包含多个层,上一层的输入来自下层的输出。
Encoder每一层为一个Encoder Block,每个Block内部均会计算输入向量的Self Attention,Self Attention的感受野是双向的,即一个文本序列,某个时间步的注意力可以兼顾前文和后文的信息,注意力的计算如图14中Dot Attention所示那样。
由于Attention计算时,将当前batch的所有样本一次性输入给Transformer,所以Transformer可以将batch批次所有样本(T, B, C)的C维度等分为h段,每一段可独立执行Dot Attention的计算,因此可以将Attention的计算挪到GPU,大为提高了NLP任务的处理效率,是一个里程碑式的存在,在此之前的NLP任务,处理的数据都是时序数据,而时序特征作为NLP任务最为重要的特征,同时因为时序的存在,操作必须是串行操作,所以无法利用GPU的并行高速计算能力,使得NLP任务一度训练和推理速度比较慢,而这一瓶颈被Transformer引入的位置编码(Position Embedding)巧秒解决,位置编码对每个位置的Token Embedding加上一个各自不同的数值,以区分不同的位置,这样即使文本序列中有多个相同的字或词,但因各自人位置编码不同,以此区别同一文本在不同位置,其表达的含义是不同的,从而完美替代时序特征,也就是说无需按时间顺序串行一个字一个字地处理序列数据。
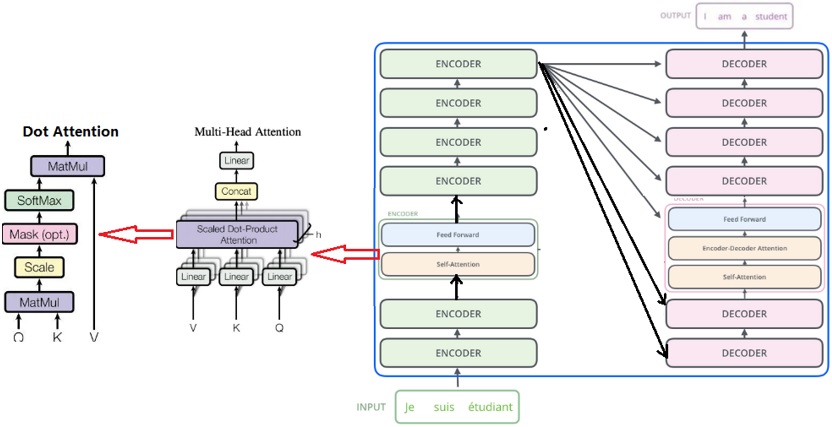
图10 Transformer架构简图
更本质一点说,Transformer的本质就是Attention的计算,性能瓶颈也在于Attention计算,对于大模型训练和推理来说,由于参数量Billion级别起步,Attention计算耗费的性能占比是最大的,而实际上Attention计算存在比较多的冗余,在DDPM开启了进入AIGC时代的可能,但也由于高分辨率图像带来的巨量Attention计算,甚至使得普通消费级显卡无法承受推理过程中的Attention计算开销,所以XFormer带来了Cross Attention,使得Attention的计算速度和存储效率有了质的提高,将Attention计算的时间复杂度从O(N2D)降低为O(ND2),N为时间步数,D为每个时间步的特征维度。
3.2 XFormer
图11描述了XFormer模型结构,其中最关键的部件为XFA(Cross Feature Attention),用于替代传统的Attention计算框架,XFA有两个改进点:1)去掉了softmax的计算; 2)将K矩阵拆分为上下文分数矩阵Kc和特征要素分数矩阵Kf。
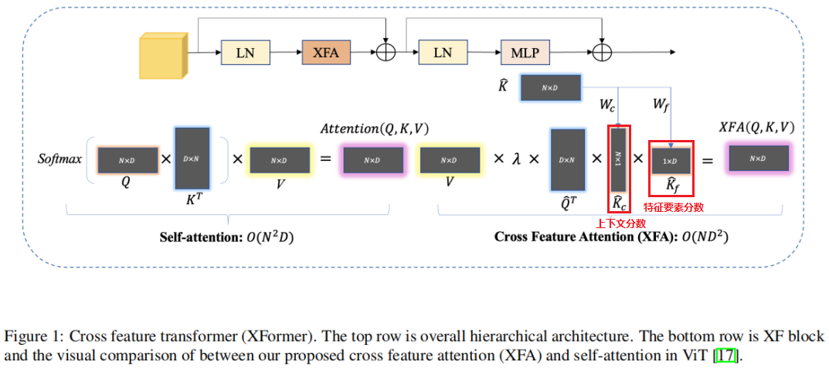
图11 XFormer结构(来源于网络)
- 替代昂贵的softmax
Softmax带有指数运算,其计算代价是比较大的,XFA对Q和K做了近似softmax替换:
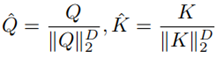
即用向量(T, B, C)中C通道的维度值D,对向量进行L2正则化,L2正则化后的向量值,近似于归一化的效果,从而近似代替Softmax,提高计算效率。
- 将K矩阵拆分为Kc和Kf
K矩阵维度为(T, C),Kc的维度为(T, 1),Kf的维度为(1, C),Kc*Kf的维度为(T, C),因此Kc和Kf从矩阵计算上看,可以替代原来的矩阵K,但Kc和Kf两个矩阵的参数之和,比矩阵K小很多,这样就提高了计算和存储效率,这点是MobileNet的核心思想在XFormer中的应用。
XFA完整的计算公式如下:
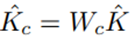
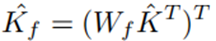
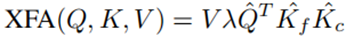
Kc为查询上下文分数,通俗一点理解,其表示VQT中哪些位置的元素比较重要,然后保留VQT中重要的元素,去除不重要的元素。而Kf表示查询特征要素分数,表示VQT所有元素的C维度中的哪些特征值比较重要,然后保留比较重要的特征值,去除不重要的特征值,可见Kc和K相当于指示器,告诉模型只计算哪些位置的Attention,其他位置的Attention置0即可。

关注更多安卓开发、AI技术、股票分析技术及个股诊断等理财、生活分享等资讯信息,请关注本人公众号(木圭龙的知识小屋)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号