无监督异常检测算法
1、概述
无监督异常检测方法有重建类、特征类、流模型和教师学生网络这几种,之前了解过重建模型,重建模型大多采用VAE+Diffusion+Transformer类模型,对缺陷特征进行创建,本次总结主要分析特征类的鼻祖模型PatchCore,并找到其论文和源码,了解其工作原理的一些细节。
图1描述了PatchCore模型的原理,出自论文《Towards Total Recall in Industrial Anomaly Detection》,也是网上介绍PatchCore原理文章中,引用率最高的一幅图。
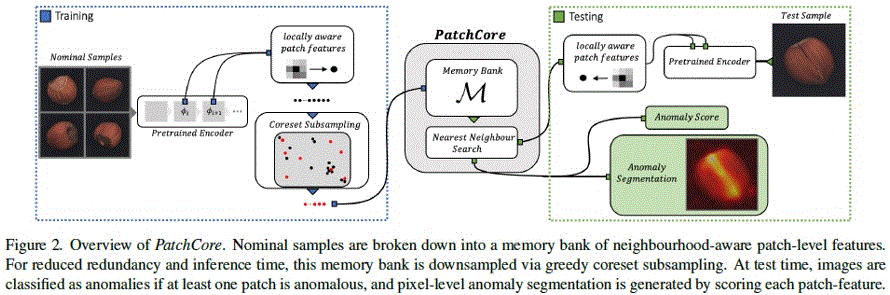
图1 PatchCore模型原理
PatchCore的核心思想是把一幅图像切分为一系列的小块(patch),然后根据一定的计算规则,计算出每个patch的异常值(可以理解为偏离正常图像的程度,偏离越大,异常值越大),然后对每个patch的异常值进行bilinear插值,便可得到原图像每个像素点的异常值,再根据对异常值设定的域值,超过该域值的像素点,便认为是异常点,最终便可得到所有异常像素点。
PatchCore需要提前预处理某场景正样本,便可对某场景的异常值进行检测,换句话说,PatchCore只支持对已知场景进行异常检测,如果输入未知场景的图像,检测效果是未知的,一般效果不会太好,因为PatchCore的原理是学习场景的正样本,然后拿负样本和正样本进行比对,从而找出正负样本不一样的地方,所以如果输入未知场景的负样本,由于没有对应场景的正样本,模型自然也无法知道图像的哪些地方是异常部分。
图2是两个数据异常点分布的样例,非常形象地展示了PatchCore的原理, PatchCore就是把图像中所有像素点的偏离值找出来,偏离值大的便是异常点,绘制为拆线图后,便是图2中展示的图形那样。
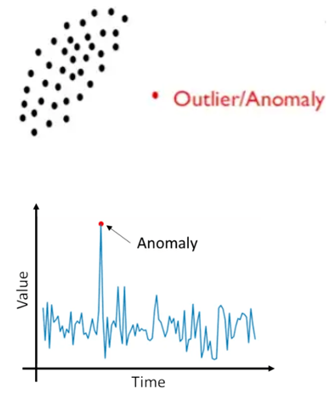
图2 数据异常点分布示例
2、PatchCore原理
PatchCore包含训练和推理两个阶段,下面分别对训练和推理进行叙述。
2.1 PatchCore训练框架
图3为论文中展示的PatchCore训练框架,大体流程为图像先经由Pretrained Encoder进行特征提取,然后PatchCore对Encoder产生的特征层序列,掐头去尾并提取中间特征层,PatchCore将中间特征层通过特征聚合操作融合在一起,以输入原图224*224为例,会输出一张28*28的patch图像,共计28*28=784个patch向量,出于计算效率和存储空间的考虑,PatchCore会从784个patch向量中,提取出若干能代表该图像的特征patch向量,构成 coreset,并存入Memory bank,一种内存向量数据库,至此训练阶段的主流程就走完了。
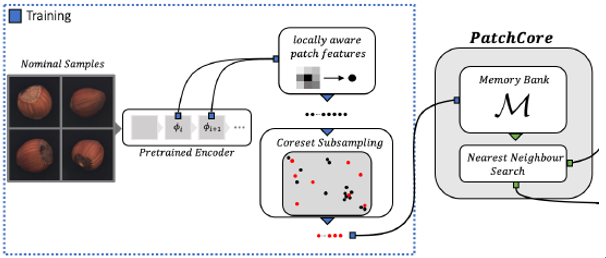
图3 PatchCore训练框架
2.1.1 Pretrained Encoder
Pretrained Encoder是一种预训练模型,通常作为backbone,以辅助PatchCore提取图像特征,可以作为Pretrained Encoder的模型有很多,比如Vgg、Resnet、EfficientNet等都可以,也可以是自定义的模型,只要效果OK就行。
图4为PatchCore特征融合功能流程示意图,1张224*224的图像经由Backbone/Encoder一系列提取特征的操作后,会生成若干层的特征图,PatchCore丢弃第1层和最后一层的特征图,只保留中间若干特征层,因为第1层这类浅层特征层,提取的特征太过局部且通用,而最后一层这类深层特征,又太过倾向于ImageNet数据集特征,非常不通用,而中间特征层感受野大小适中且特征知识也比较通用,所以PatchCore只保留中间特征层作为Patch产生的来源。
之后,PatchCore会对挑选出的若干中间层进行Patch化,每一个特征层Patch化的过程,也是特征融合的过程。
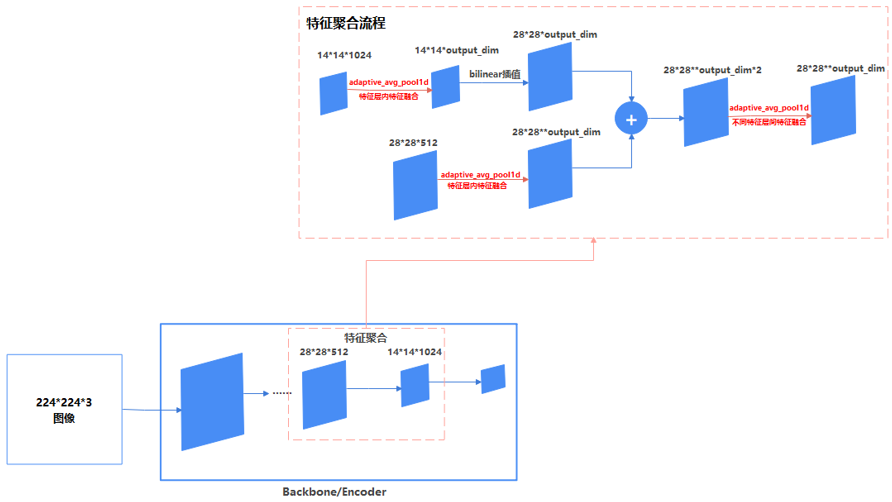
图4 PatchCore特征融合
特征融合体现在2个层面上,第1个层面是特征图内部的特征融合,第2个层面是特征层间的特征融合,且第2个层面的特征融合,是基于第1个层面特征融合的结果上,做了进一步高层抽象的信息融合。
- 特征图内的特征融合
图5描述了特征层内特征融合的完整流程,一张28*28*512的特征图,会经由kernel size为3*3的unfold核逐一抽取[3, 3, 512]区域内的特征,然后flatten为3*3*512的向量,3*3*512的向量进一步做AdaptiveAvgPool的均值化操作,从而将[3, 3, 512]区域内的特征融合为一个3*3*output_dim的向量,最后对3*3*output_dim向量进行fold操作,还原回28*28中的一个特征点,该特征点的深度为output_dim。
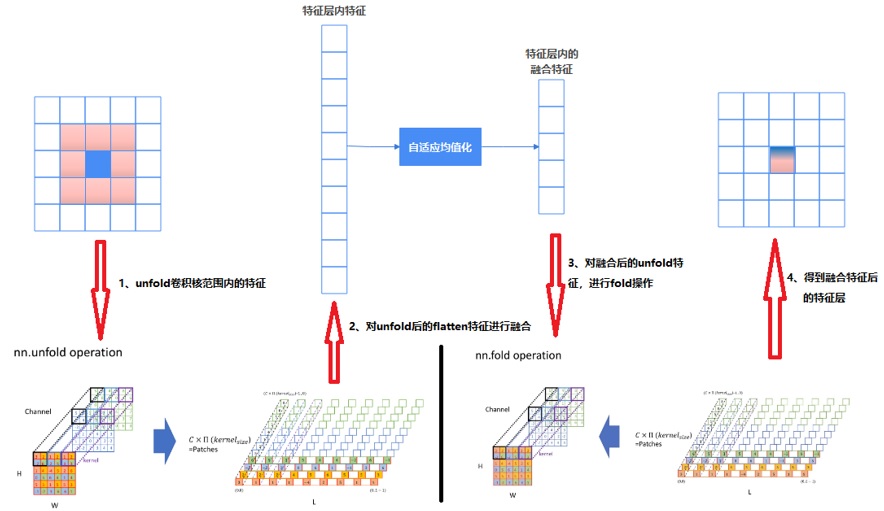
图5 特征层内特征融合全景图
- 特征层间的特征融合
图6描述了特征层间特征融合流程,更深层的中间层,先双向线性插值对齐第一个中间层的尺寸,然后各特征层经concat结合为一个特征层,该特征层再经由AdaptiveAvgPool对所有特征层进行融合,即得到patch特征的最终表达。
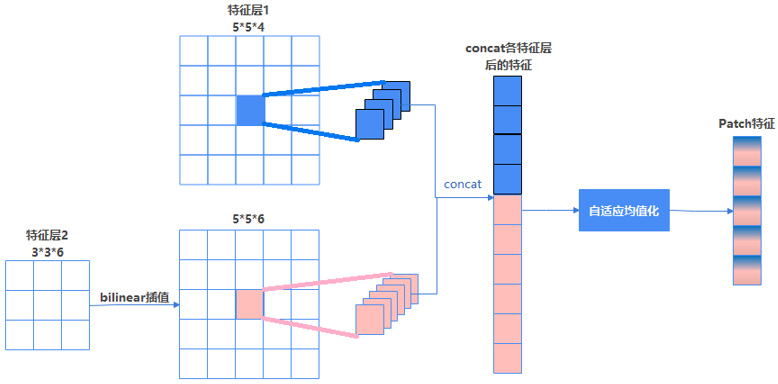
图6 特征层间特征融合
2.1.2 CoreSet降采样
由2.1.1节得到的原始patch特征,其数量是非常多的,由于PatchCore采用KNN算法对图象patch块进行比对,其计算效率其实是非常低下的,虽然PatchCore采用了三方工具Faiss实现的KNN功能及向量匹配工具。
为了提高计算效率和减轻存储负担,PatchCore提出了CoreSet思想,简单说就是从原始的patch特征向量集中,挑选出一定比例(作为超参数)的patch特征向量,用这些挑选出来的部分patch特征向量,代表原来的patch特征向量全集,从而提高了计算效率。
图7展示了均匀分布数据下的CoreSet效果,可见CoreSet均匀分布在整个数据集空间中,贪心算法产生的CoreSet比随机采样效果更好,所谓的贪心即图8中算法流程的min、max操作。
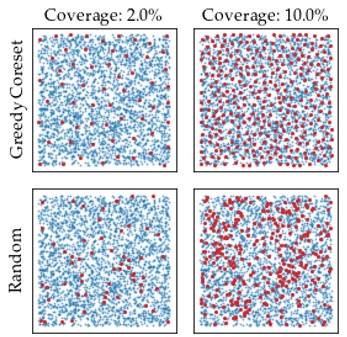
图7 均匀分布数据下的CoreSet效果(红点为CoreSet,蓝点为原始数据集)
图8描述了CoreSet的生成规则,算法中,M代表内存银行,也就是向量数据库,其一开始存储了所有的patch特征向量,Mc代表CoreSet,算法的大致思想:在寻找新的核心集patch特征向量时,先计算M中所有patch特征向量与Mc中所有向量的Euclidean距离,然后在M中每个点到Mc所有距离中,挑选Euclidean距离最小的,再然后对M中每个点到Mc最小距离中,又再挑选出最小距离最大的,其对应的patch特征向量,即为选入CoreSet的patch向量。

图8 CoreSet生成规则
PatchCore计算Euclidean距离的方法有点意思,直接采用公式a2-2ab+b2的矩阵版本,如图9所示。

图9 计算Euclidean距离代码
2.1.3 Memory Bank
Memory Bank字面意思是内存银行,从PatchCore设计思想和代码来看,Memory Bank更像是一种数据库,或者向量数据库,PatchCore采用三方库Faiss提供的Memory Bank及向量检索功能。
2.1.2小节产生的CoreSet(核心集),需持久化保存到Memory Bank,以供测试阶段使用,用于提供正样本的比较基准,让PatchCore知道测试样本距离正样本的偏离值有多大,如果太大,则存在异常点。
至此,训练阶段的主要概念就介绍完了。
2.2 PatchCore测试框架
图10描述了PatchCore测试框架的主要流程,一幅测试图像进来,经由Encoder提取出其patch特征后,经由faiss的KNN搜索功能后,找到每个patch与其距离最近的Memory Bank中的点,该距离作为每个patch的异常值,这些patch异常值中的最大者,即Image Level的异常值,如果异常值超过一定范围,说明图像中真的有异常,然后可通过segment操作,基于patch异常值,做bilinear插值,得到一张和原图尺寸一样的异常分布图像,对该异常分布图像进行域值处理,便可得到分割异常的mask图像。
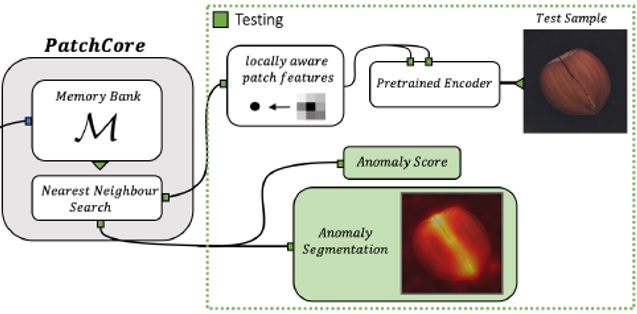
图10 PatchCore测试框架
2.2.1 Image Level异常值
图12为PatchCore推理流程较详细的示例,图像经由Encoder提取特征、特征聚合后,形成形如图11所示的图像Patches,Patch化的步骤也叫作Embedding,比如将[3, 3, 512]区域的特征映射到图11左侧所示的Patches矩阵,方格深度为1024。
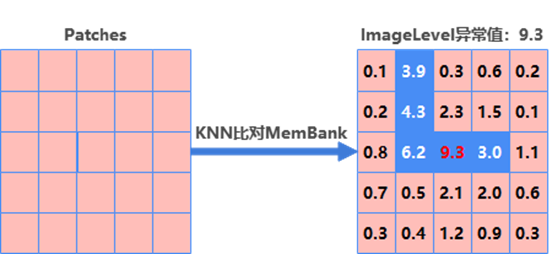
图11 图像Patch化示例
之后将图11的patches与Memory Bank中的向量进行KNN比对,以patch最近的邻居的Euclidean距离作为patch的异常值,便得到每个patch的异常值,所有patch异常值中的最大者,即为Image Level的异常值,图11右侧Patches异常值矩阵,其Image Level的异常值为9.3。
2.2.2 获取异常mask
计算得到测试图片的异常值矩阵后,便可依据异常值矩阵,进行bilinear插值,将矩阵尺寸还原为测试图片的尺寸,从而得到测试图片每一个像素点的异常值,对异常值做过滤处理,便可得到异常mask,完整流程可参照图12所示。
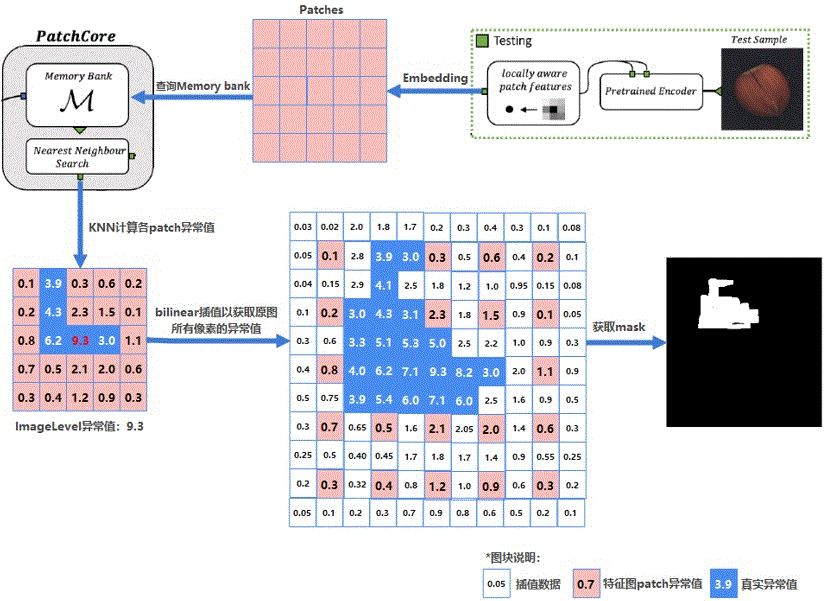
图12 PatchCore推理流程示例
3、特征类异常检测的其他框架
3.1 CFA
CFA在PatchCore的基础上,做了进一步的优化,它认为PatchCore使用Encoder提取的中间层特征,富含Encoder训练数据的特征,但这些数据特征对工业领域还不是非常合适,需要使这些特征在工业数据上做一定的适配训练,使其更适合工业领域的特征提取,这就是域迁移的思想,即图13中的Patch descriptor模块的功能。
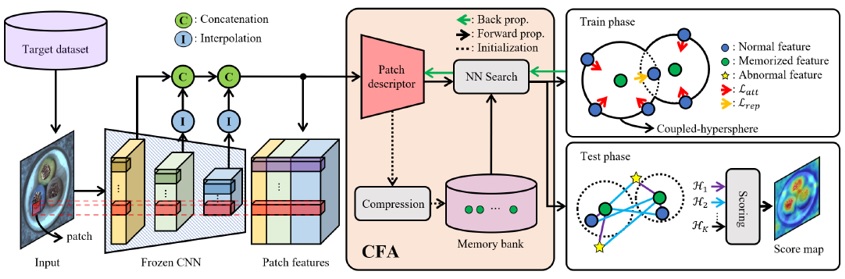
图13 CFA框架
4、总结
异常检测类算法发展到现在,包含重建类、特征类、教师学生蒸馏等方式,特征类算法可以凭借少量具有代表性的正样本的学习,即可对负样本中的所有缺陷做召回,是一种非常值得借鉴的一种思想,在实际使用时,需注意训练样本的采样,采样需尽量覆盖任务的所有场景。

关注更多安卓开发、AI技术、股票分析技术及个股诊断等理财、生活分享等资讯信息,请关注本人公众号(木圭龙的知识小屋)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号