物体检测、图像分割技术概述
物体检测、图像分割是CV领域的两大任务,尤其是物体检测,其在各个领域和AI比赛中,更是占有举足轻重的位置。
1、概述
图1描述了起源于图像分类的主要计算机视觉类任务。
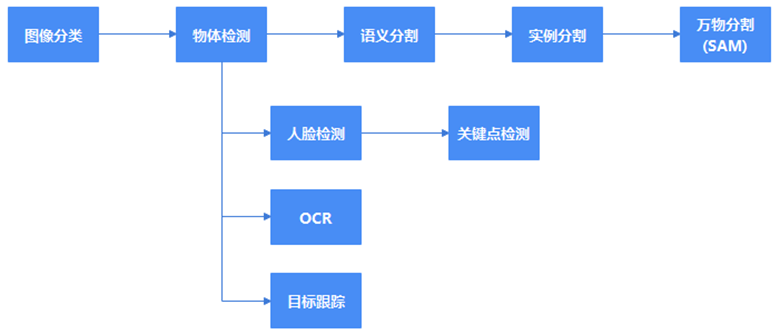
图1 发源于图像分类的计算机视觉任务
为什么如此划分?因为在更早的时候,AI圈还停留在机器学习的时代,那时候的算法只有KNN、决策树、朴素贝叶斯和SVM等,外加AI界的设计模式:集成学习,搞出了一些组合式算法,比如随机森林、XGBoost等,这些算法大多只能对结构化(一张二维表)的数据进行处理,而对图像、音频、视频类的数据,往往不太胜任,要么是计算精度不够,要么就是计算速度太慢,对于那个时代的王者SVM算法,其计算速度是其致命的硬伤,无法规避,导致今天其已经很少使用,只留下了算法思想的价值。
加上算力和算据的极大限制,因此早期机器学习类的算法,大多只能对图像类任务进行较为简单的处理,比如输入一张较小的图像,将其用决策树或SVM等进行分类,然后用模式匹配等算法,找找图像里有没物体。
进入到互联网时代后,尤其是移动互联网时代,算据规模接近天文数字,英伟达显卡提供了充足的算力,深度学习的出现,正所谓天时、地利、人和三者合一,将时代推进到了AI变革的时代,图像分类任务就成了最基本的视觉类任务,在一张图像被成功分类后,自然而然就想进一步知道图像中某个物体的具体位置在哪,这个物体的类别是什么,这时候物体检测任务就呼之欲出了,而有了物体检测任务,又想更进一步将物体内容同背景区隔开,这个就是分割任务。
分割任务又分为语义分割和实例分割,语义分割是不同类别的物体,用不同的颜色区分,相同类别的物体,用同一颜色,即语义分割,只区分不同物体的类别。而实例分割,无论物体间的类别是否相同,都将它们视为不同的,用不同颜色标识。Meta更是打着分割万物的旗号,推出了SAM模型,这种模型不再是简单的语义分割、实例分割和全景分割,而是这几种任务的结合体。
在所有的计算机视觉任务中,物体检测是很核心的,也是很基础的任务,从物体检测派生出了图像分割、人脸检测、OCR和物体跟踪这些任务。
2、物体检测
物体检测算法有基于锚框和不基于锚框两种,Faster RCNN、SSD、YOLO这些都是基于锚框的物体检测算法,而DLTR、FCOS这些算法是不基于锚框的。
2.1 物体检测套路
不论哪种物体检测算法,其套路不外乎切、提、分三部曲,区别在于这三个步骤的执行顺序,以及如何切、如何提、如何分,不同的检测框架,其具体的切/提/分策略是不同的。
- 切
即切图,将原图中的某一部分切出来,进行该区域内的物体检测,至于具体切哪个位置,以及切图宽高大小,不同的物体检测算法不一样。切这个动作,其最终目的是构建图像金字塔,是提取多尺度特征的一个必要手段。
- 提
即提取特征,对原图或切下来的子图,采用CNN、Attention等进行特征提取。
- 分
即分类或回归,对原图或切下来的子图,分类其内所预测物体的类别,或回归其内所预测物体的偏移量。
2.2 基于anchor的物体检测算法
基于anchor的物体检测算法众多,本文以MTCNN和SSD为例,简要介绍一下。
2.2.1 MTCNN
MTCNN是一种人脸检测框架,本质上也是一种物体检测框架,稍加修改,也可用于其他物体检测任务,而MTCNN也是一种基于anchor的检测框架,相较于SSD、YOLO,其anchor种类比较单一,只有一种正方形的anchor,因为人脸都是类方形的,所以其逻辑和功耗相较SSD、YOLO就简洁许多。
MTCNN的核心思想是三个臭皮匠,顶得一个讲诸葛亮,即用三个简单模型(P-Net、 R-net、O-net)的串行联接,代替一个复杂的模型,通过实践验证,其效果还不错,即使性能上比复杂的单一模型稍差点,但效果也还不错,而且MTCNN模型非常简单,对存储、算力、功耗的要求极低,这是其他模型所不能比拟的。
其工作流程简要概括为切、提、分,即先从原图切下子图,然后对子图提取特征,最后基于提取的子图特征,预测子图中的物体分类及位置,如图2所示,MTCNN将原图按几种不同的比例进行压缩,再将压缩后的图片传给MTCNN的P-Net进行滑窗(CNN卷积核)处理,这就实现了多尺度特征的提取。
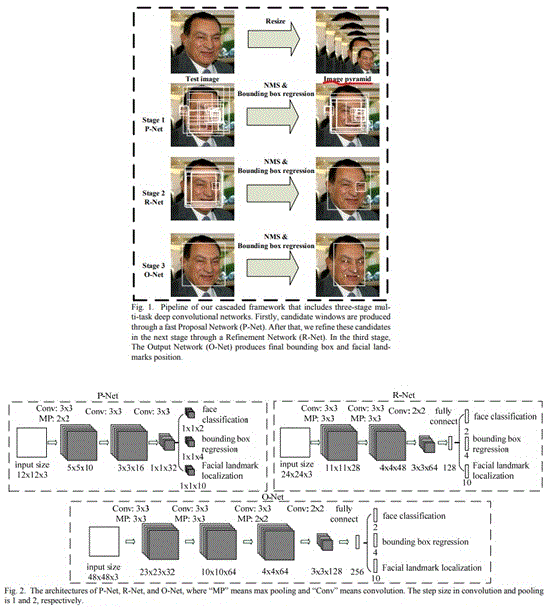
图2 MTCNN工作原理
2.2.2 SSD
SSD英文全称Single Shot MultiBox Detect,是一种单阶段多任务的通用物体检测框架。
SSD的工作流程是提、切、分,即上来先一顿猛如虎的提特征的操作,提取出不同层次的图像特征,然后基于这些不同深度的图像特征,将原图划分为大小不同的8732多个子图,图像特征深度越浅的,其感受野越小,对应原图的子区域范围越小,越能检测小的物体,反之则越大。每个特征图会相应地将原图像均分(切图)为特征图宽高乘积(宽*高)个子图,再然后会对这些子图预测其内包含的物体及其位置偏移。
SSD原理如图3所示,图中红框表示SSD通过特征图金字塔的方式,构建了对图像多尺度特征的提取,即每个特征图对应原图的一个切分粒度,比如8*8的feature map,将原图近似平均地划分为8*8=64个子图,然后SSD对这64个子图进行物体检测,其他层级的特征图工作方式以此类推。
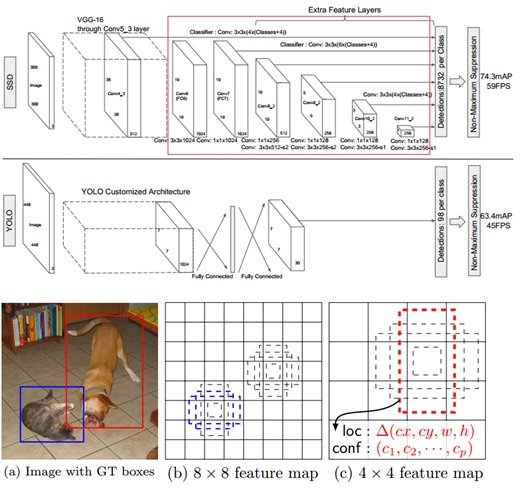
图3 SSD原理图
2.2.2.1 SSD多尺度特征
SSD的多尺度特征提取,基于不同层次的特征图实现,图3中一张300*300的图像,先经SSD backbone各CNN层次的卷积计算,再依次通过6层自定义卷积层,依次得到38*38、19*19、10*10、5*5、3*3、1*1共计6张特征图,这6张图用来对原图进行不同scale尺寸的子图切割,以38*38特征图为例,其将原图300*300大小的图像,近似均匀地切分为38*38=1444个子图,每个子图大小约为(300/38, 300/38)的大小而这1444个子图从上到下、从左到右地排布在原图上,在此基础上,SSD对每个子图设计了高矮胖瘦各不相同的4个anchor,然后SSD就对每一个anchor预测其内是否有物体,以及物体是哪个分类,以及物体位置相对于子图的偏移。
所以,特征图越大,其能分辨的特征越局部,而特征图越小,其能分辨的特征就越全局,对于小物体检测,需要增加尺寸大的特征图数量,减少尺寸小的特征图数量。
2.2.2.2 SSD anchor
SSD提出了8732个大小不一的anchor,兼顾大小不同、高矮胖瘦不同的物体检测,如图4所示。
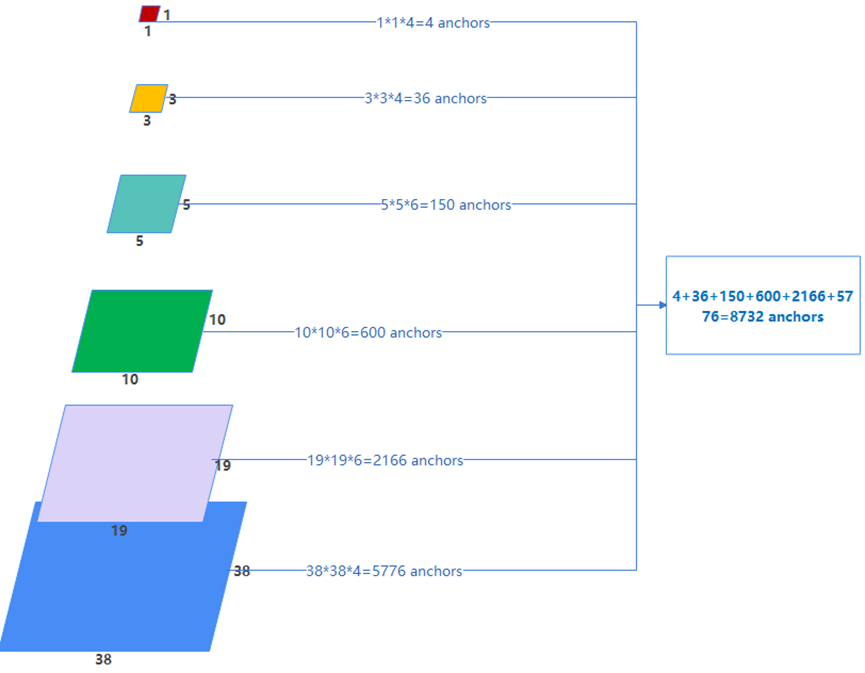
图4 SSD锚框分布
2.2.2.3 SSD损失函数
SSD损失函数包含2个部分,一部分是物体类别预测损失的交叉熵Loss1,一部分是预测物体位置偏移的损失Loss2。
- 物体类别预测的Loss1损失
这类损失,采用的是交叉熵计算,采用了一个trick,用于平衡正负样本不均衡的问题,即对每张图像,正样本为n,则对应选取3n的负样本,也即正样本的权重为1。
对于正负样本不均衡的问题,也可借鉴Focus Loss的思路,给正负样本的loss,分别设置一个权重,以减轻样本不均衡带来的问题。
- 物体位置偏移预测的Loss2损失
SSD采用的是L1SmoothLoss,L1SmoothLoss是对L1损失函数的改进,将0附近的点变得可导且光滑,更容易使模型训练收敛,如图5所示。
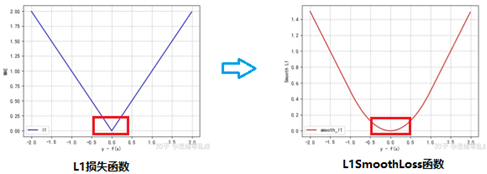
图5 L1损失、L1SmoothLoss效果对比
2.2 无anchor的物体检测算法
此类物体检测算法,规避了因引入anchor而带来的额外的庞大计算开销,实际运行效果也还不错,代表算法有DETR、FCOS、Yolov8等。
2.3.1 DETR算法
DETR算法全称为Detection Transformer,是一种基于Transformer的物体检测框架,先通过传统CNN提取图像特征为一个Contextual Vector,经位置编码后,利用Transformer encoder对Contextual Vector进行特征提取,然后使用Transformer decoder结合object queries生成式地输出目标物体的位置和物体类别,算法原理如图6所示。
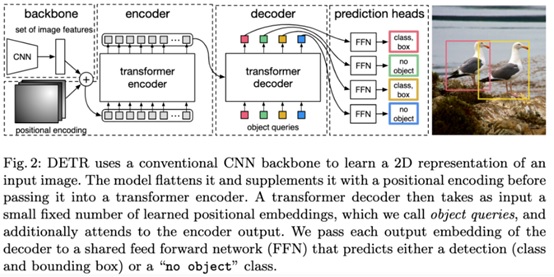
图6 DETR算法原理
DETR算法的缺点是训练慢、所需的数据规模也比较大,在小物体检测上表现还有所欠缺,但其优点是算法架构灵活,很容易地应用于全景分割,在较大物体的检测上效果不错。
2.3.2 FCOS算法
FCOS算法是基于anchor-based算法衍生出的一种anchor-free算法,图7描述了FCOS算法原理。
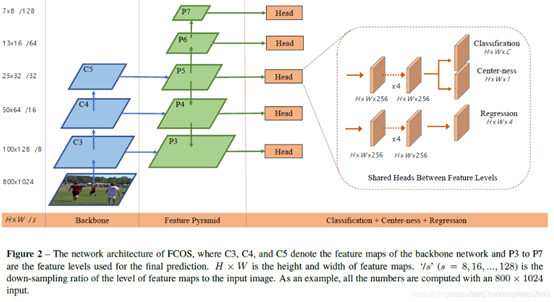
图7 FCOS算法原理
从算法原理图上看,FCOS同SSD、YOLO差异似乎不是太大,至少在特征提取、多尺度这块,三者差异不大,都是通过特征图实现多尺度,以及通过提取局部区域感受野的特征,作为后续物体类别、位置偏移的预测提供依据。
FCOS与SSD、YOLO的不同,在于对特征图上点的处理,SSD会基于特征图的每个点,设定一些anchor,然后做后续GT框的分配和预测后的NMS处理等等,而FCOS对于特征图点的处理,是将其映射回原图中的一个点,如果这个点恰好在某个GT框的内部,则该特征图点对应子块在原图中的位置,则为一个正样本。之后FCOS基于每个特征图的每个特征点,通过Head分支预测其对应块的物体类别、center_ness、l、t、r、b,center_ness是一个权重项,用来抑制预测目标同GT框中心点相距很远,从而使预测质量低下的情况。
3、图像分割
图像分割是基于物体检测任务,自然而然派生出来的任务,物体检测本质上还是一种粒度较为粗糙的检测任务,只是对物体所在位置画了一个检测方框,而物体本身面积可能在该检测框内所占面积还不到1/10。
图像分割是一种精度要求较高的任务,本质是像素级的分类任务,即对图像中的每个像素进行分类,经典框架有UNet,以及后续的Deeplab、Yolact等。
UNet框架采用的是一种Encoder-Decoder,如图8所示,UNet的左半边是不断CNN及降采样的过程,这个过程是Encoder的编码过程,而UNet的右半边,是不断转置CNN和上采样的过程,这个过程是Decoder的解码过程,编码过程和解码过程会有shortcut短接的数据连接,以使用上采样时可以访问原始的低层特征。
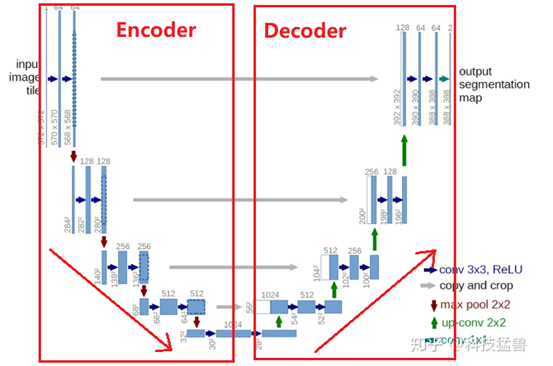
图8 UNet架构
UNet框架虽然简单,但其应用价值非常重要,后面扩散模型Stable Diffusion Model(LDM)等很多地方都会用到。
4、总结
计算机视觉类的常见任务有图像分类、物体检测和图像分割,这些任务已经派生出了非常多的经典框架,可根据任务的实际情况,酌情使用。

关注更多安卓开发、AI技术、股票分析技术及个股诊断等理财、生活分享等资讯信息,请关注本人公众号(木圭龙的知识小屋)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号