GraphRAG如何构建知识图谱Knowledge Graph (GraphRAG系列第二篇)
GraphRAG工作的第一步,是将输入的文档集合,按一定的策略拆分成一个一个chunks,然后解析每个chunks,将chunk中所关注的实体(entity)和关系(relation)解析出来,以此构建知识图谱。
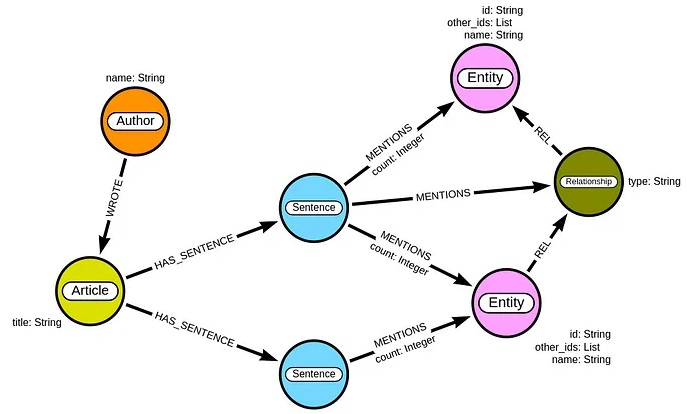
那问题来了,GraphRAG是如何抽取文本中的实体及其间的关系,是像以前NLP任务那样,通过标注文本词性的方式,来训练一个LSTM/GRU网络来实现吗?
其实,GraphRAG的知识图谱构建思想是简单和朴素的,它借助大模型的few shot能力,来提取输入文档中的实体关系,从而建立起知识图谱。GraphRAG的默认实现,是借助OpenAI的ChatGPT,基于默认的prompt模板,来提取关系实体,
考虑到不同文本所属领域不同,使用的语言也不同,所以对于不同的输入文本,需要对prompt模板进行微调(tune)。
GraphRAG的prompt模板有三种类型
- Entity/Relation提取
指示LLM如何提取实体关系的prompt,该prompt源码路径:
http://github.com/microsoft/graphrag/blob/main/graphrag/index/graph/extractors/graph/prompts.py
- 总结Entity/Relation描述
指示LLM如何对每个Entity/Relation的功能进行总结,该prompt源码路径:
http://github.com/microsoft/graphrag/blob/main/graphrag/index/graph/extractors/summarize/prompts.py
- Claim提取
指示LLM如何提取每个Entity的Claim,这个Claim可以理解为Entity或Relation的属性,该prompt源码路径:
http://github.com/microsoft/graphrag/blob/main/graphrag/index/graph/extractors/claims/prompts.py
下面以提取Entity/Relation为例,讲解如何微调prompt。先看下提取Entity/Relation默认prompt内容:
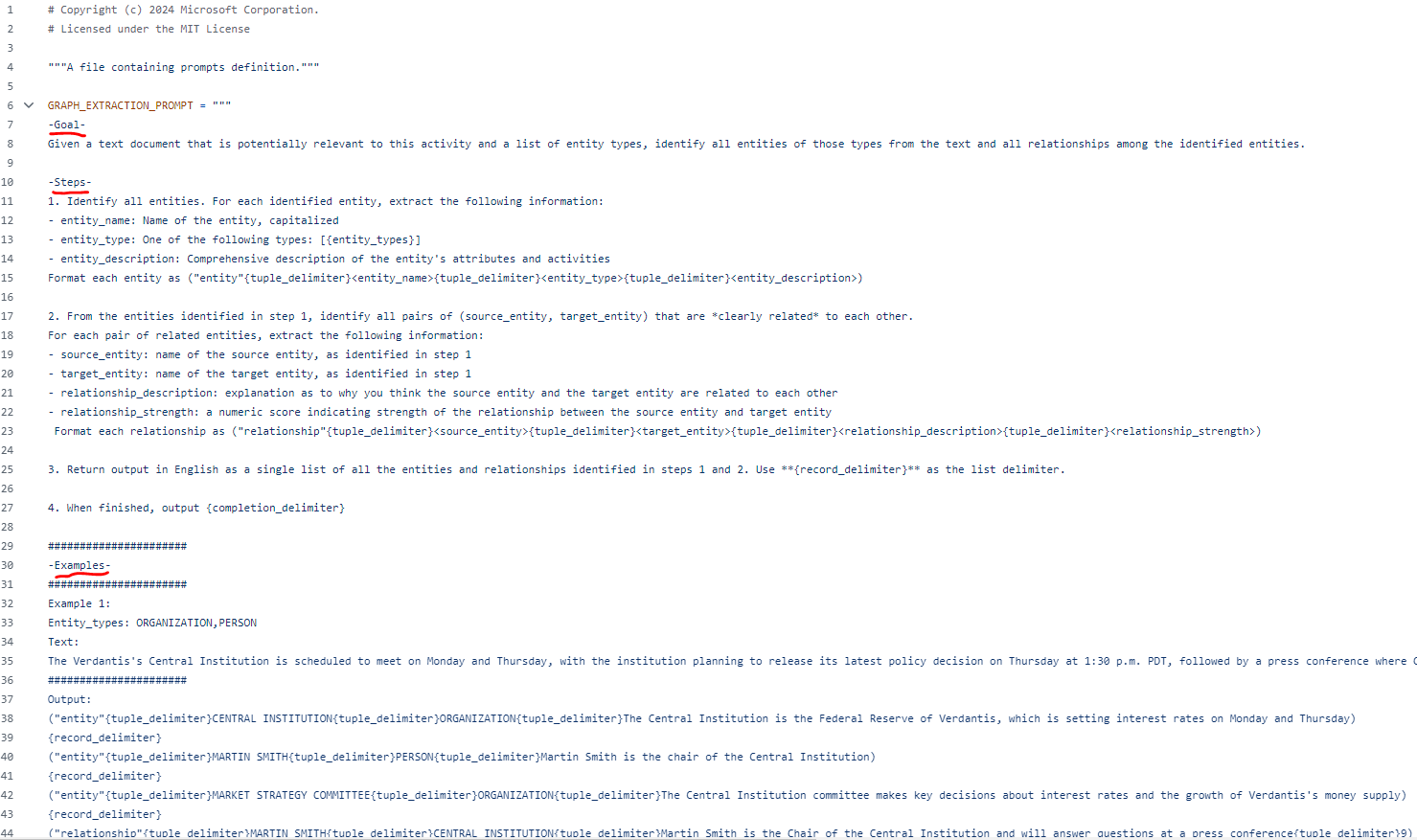
prompt包含Goal、Steps、Examples等几个部分,告诉LLM本次任务的目标是什么,如何达成这个目标,并举了几个例子,这些就是GraphRAG实现对特定文本进行实体抽取的秘密所在。而微调prompt以适应当前任务的方法,就是修改Examples部分,将本次任务领域的实体关系,举些例子写进并替换Examples部分的例子,使得LLM能够识别并提取本次任务关注的实体关系类型。

关注更多安卓开发、AI技术、股票分析技术及个股诊断等理财、生活分享等资讯信息,请关注本人公众号(木圭龙的知识小屋)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号