第九课 SVD分解
大学里的《线性代数》学过矩阵的加减乘法操作,计算起来也比较简单,比如现有矩阵A和B,取值如下:
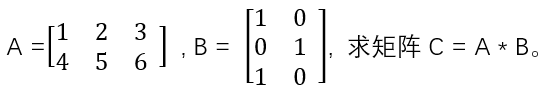
A是2*3的矩阵,B是3*2的矩阵,C很容易求得一个2*2的矩阵:
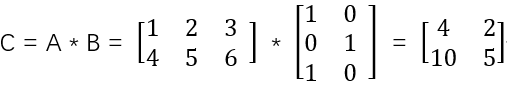
上面的计算过程,相信很多人都会,但现在的问题,如何求矩阵C由哪些矩阵相乘而得?这个问题估计会的人就不多了,其实这是一个矩阵分解的问题,也算是除法在矩阵运算中的体现,奇异值分解就是用来解决这类矩阵分解问题的,本文只探讨奇异值分解的应用,而不谈奇异值分解是如何将矩阵分解出来的,有兴趣的读者可去《线性代数》相关章节查阅。
1、什么是奇异值分解?
奇异值分解的英文全称是Singular Value Decomposition。
现有任一矩阵A,通过奇异值分解后,可求得U、S、V三个矩阵,使得
A = U * S * V
其中,U为A的左奇异矩阵,S为A的奇异值矩阵,V为A的右奇异矩阵。S中存放有矩阵A的s个奇异值,这s个奇异值按数值大小降序排列,奇异值的数值越大,代表其所蕴含的矩阵A中的信息越多,可以这么理解,S中的每个奇异值,分别将矩阵A中所有的数据进行了一次抽取融合成了一个奇异值,S中的前k个较大的奇异值,代表了矩阵A中大部分的信息。
2、奇异值分解的意义
奇异值分解可将一个大的矩阵,分割成3个矩阵U、S、V,这3个矩阵相乘就可还原出原矩阵。
假设Am*n = Um*m * Sm*n * Vn*n,如果取U矩阵的前k列、S矩阵的前k列和前k行、V矩阵的前k行,可得三个新的矩阵:
U’=Um*k, S’=Sk*k, V’=Vk*n (k<=m and k <= n)
那么A’ = U’ * S’ * V’,则A‘是原矩阵A的一个近似矩阵,即A’对原矩阵A的信息进行了压缩,减少了存储空间和提高计算速度,但效果和矩阵A的效果不会差很多。
奇异值分解是一种信息抽取和压缩的技术。
3、奇异值分解接口体验
SkLearn提供了SVD的封装实现,即sklearn.linalg.svd()方法,下面使用这个方法来感受下SVD分解的概念。
首先自定义一个4 * 6的矩阵A。

然后调用np.linalg.svd函数对矩阵A进行svd分解,并将分解后的矩阵内容及形状打印出来观察。

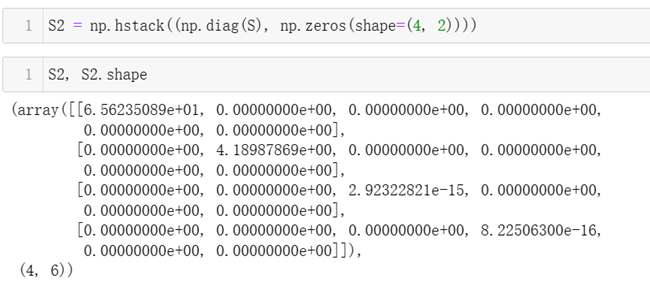
因为S的形状是4 * 1的,即4个奇异值,为实现其与左奇异矩阵U和右奇异矩阵V的连乘,需将S的形状补全为4*6的。先将S变换为4*4的对角阵,对角线的4个元素为对应的4个奇异值,然后将对角阵的列补全为4*6的矩阵S2,即新增2列,列的内容全为0。
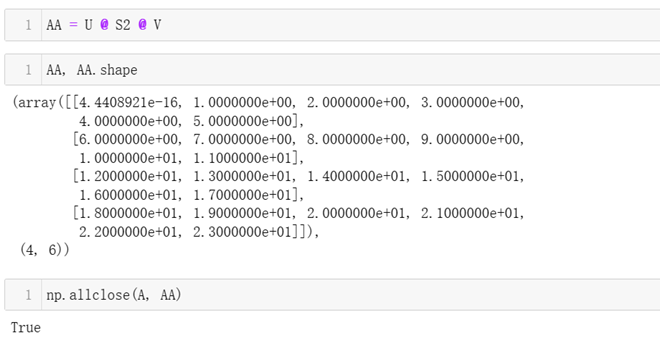
验证U * S2 * V可还原A矩阵,allclose用于验证AA和A是否为相同的矩阵,因为SkLearn里计算的数都为浮点数,很少有2个数绝对相等,即很少有2个相等数,他们的差值为0,在SkLearn里,只要2个数的差值小于1e-6,即认为这2个数相等。
4、奇异值分解的应用
奇异值分解在工程上的应用,可用于提取信息并压缩,提高计算效率。下面以图片处理为例,来介绍SVD的作用。
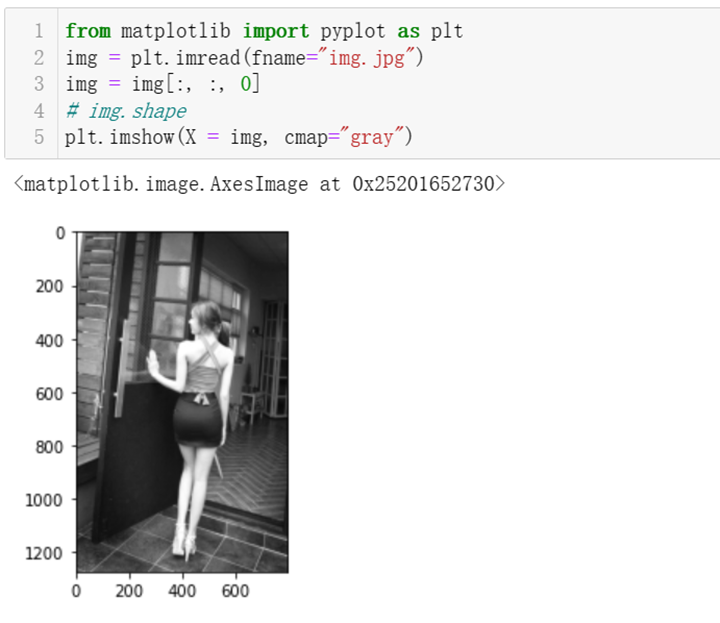
从本地读取一张图片,保持原有图像信息,并采用灰度图的形式来展示图片。
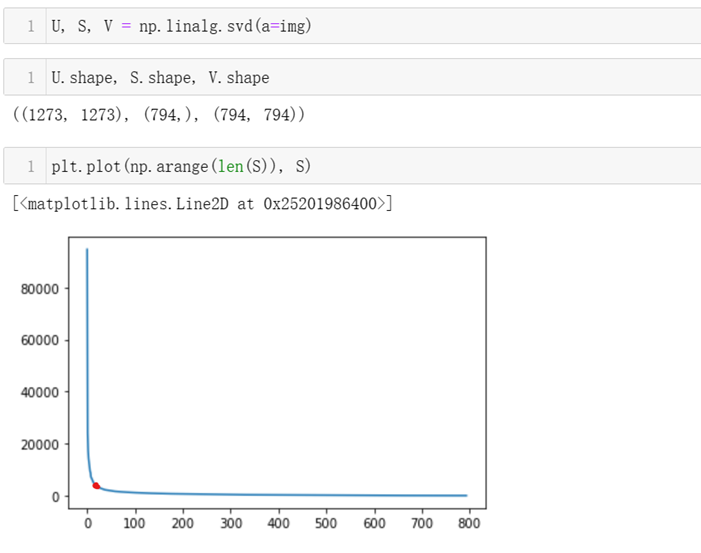
将原图像矩阵进行SVD分解,并将得到的所有奇异值用拆线图绘制出来,拆线图的纵坐标表示奇异值的具体取值,横坐标表示第几个奇异值,因读取的图像大小是1273*794,而奇异值的个数取宽高的最小者,也就是794。从折线图中可看到奇异值的取值快速下降,大约取到第10个奇异值后,剩下的794-10=784个奇异值的大小已经近乎为0了,奇异值的大小代表其所抽取的原矩阵信息量,值越大,所含的信息量越多,从图中可看出,基本前几个奇异值包含了原矩阵绝大部分的信息,剩下的大多数奇异值,基本不包含什么信息。因此,我们可以只取前面几个奇异值,并相应裁减左奇异矩阵U和右奇异矩阵V,然后将裁减后的矩阵相乘,就可得到压缩后的新矩阵。
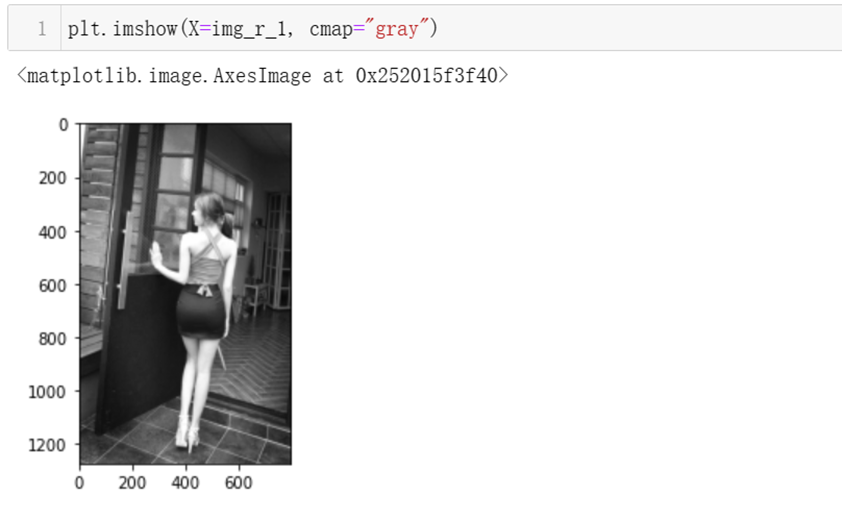
先将奇异值S向量扩充为形状为1273*794的S1矩阵,然后将U * S1 *V还原图像,得到矩阵img_r_1,先调用np.allclose从数值角度检验原图像和还原后的图像是否一样。输出True表示还原后的图像和原图是一样的。

然后,将还原后的图像显示出来,与原图做三观上的对比,基本没发现有什么不同。
取前k=10个奇异值,将求出对应的压缩图像并显示,可看出前10个奇异值包含的信息,把原图的信息基本都展示出来了。

下面取前k=20个奇异值,将求出对应的压缩图像并显示,可看出前20个奇异值包含的信息,比k=10又清晰了一些。

下面取前k=50个奇异值,将求出对应的压缩图像并显示,可看出前20个奇异值包含的信息,比k=20又清晰了很多。

下面取前k=100个奇异值,将求出对应的压缩图像并显示,可看出前20个奇异值包含的信息,基本和原图差不多了。

5、小结
从第4小节的SVD实践效果,可见SVD的信息抽取和压缩效果还是不错的,只要抽取前100个奇异值和裁减对应的左右奇异矩阵信息,就能基本代表原图,压缩率大概为100/794=12.6%。后面要介绍的PCA降维,理论基础就是本节的SVD分解。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号