第七课 随机森林
1、算法概述
随机森林是一种集成学习方法,其理论基础是决策树。
随机森林由随机+森林两个词组成,这两个词非常精确的描述了随机森林算法的本质,随机说明了算法具有一定的随机性,体现在算法在选取数据集时,会随机从行和列两个方向筛选出子样本,比如图1和图2显示了随机森林两棵子树A和B所选取的数据集是不同的,子树A选取了Survived、Sex、Parch、Cabin、Fare五个特征,以及若干行(每行表示一个样本),子树B选取了Passenger、Sex、Cabin、Embarked、Fare五个特征,以及若干和子数A不同的行(样本),子树A和子树B选取的行和列有部分重叠,又有些不重叠的部分,这就保证了子树A和子树B大体是相同的,但又能学到不同的测重点,增加了模型的多样性和泛化能力,这就是算法随机性的内涵; 而森林更好理解,表示算法由很多很多棵子树构成,随机+森林合并起来,就将随机森林算法的核心表现的淋漓尽致。
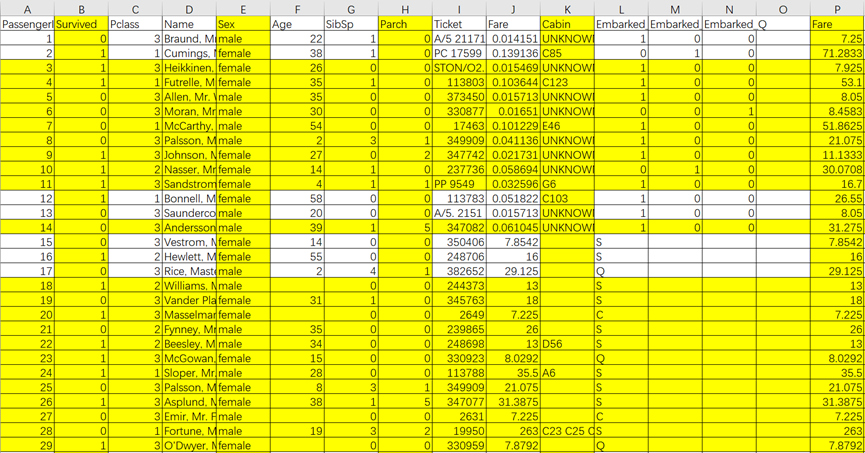
图1子决策树A随机选取的数据集(黄色背景表示被选中)
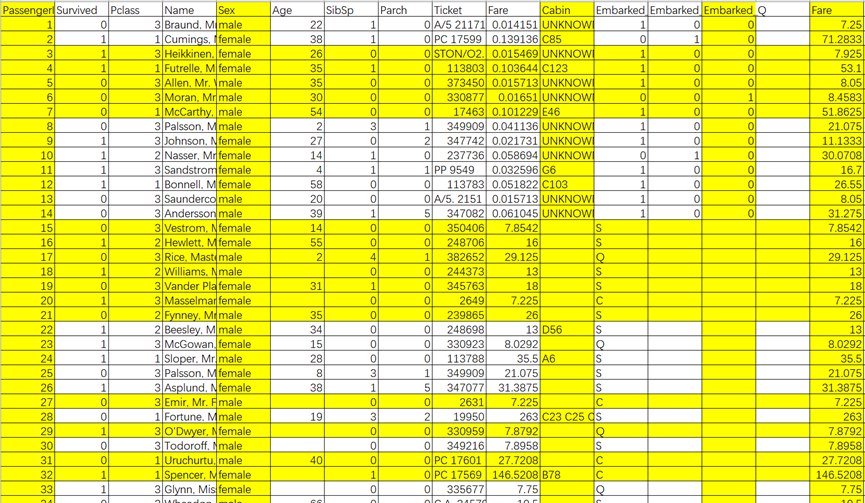
图2子决策树B随机选取的数据集(黄色背景表示被选中)
2、算法原理
将一棵完整的、较复杂的决策树,阉割为多棵弱一点的子决策树,对于分类任务,在推理时,每一棵子决策树都会产生一个推理结果,随机森林算法通过投票机制(Voting),统计哪种推理结果出现次数多,就将该推理结果作为随机森林算法的最终结果输出,而对于回归任务,其训练和推理过程和分类任务基本一致,不同的是在确定推理结果时,其采用的是计算所有子决策树推理结果的平均值,而不是通过投票选出,图3描述了算法的原理及大致流程。

图3随机森林原理图
3、算法应用
以图4中的相亲决策树为例,这棵树在《决策树》章节也曾出现过,下面将会对这棵树进行阉割简化,其变体如图5所示。

图4相亲决策树
这里为了简化和更突出重点,只提供了3种子树类型,实际应用中的子树数目远比这个多,至少在几十上百棵树以上。
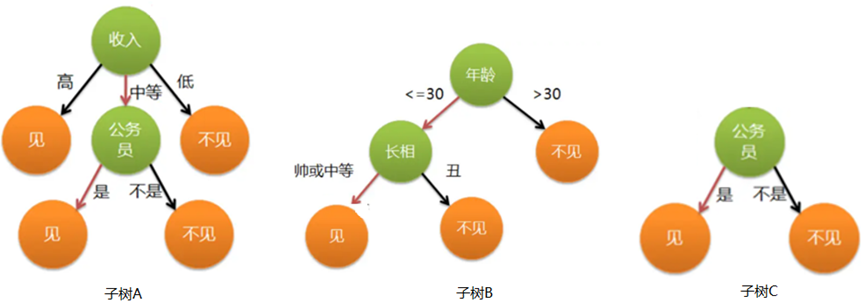
图5相亲决策树的子树集合
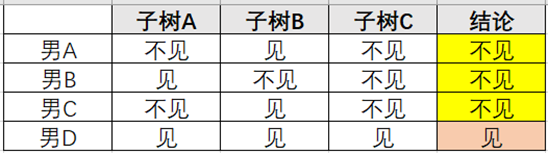
现在有4个相亲候选人对像,条件如表1所示,根据图5中的相亲决策子树集合,女方会得到表2所示的分析数据,最终女方多方面多角度综合权衡考虑,决定同男D见面。
表1 相亲候选人列表
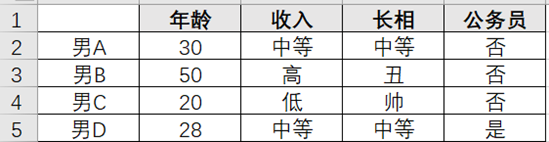
表2 相亲对象决策表
4、随机森林API的使用
SkLearn中封装有随机森林的API,使用方式如下代码:
![]()

代码使用的数据集是自行构造的10分类数据,总共10万个样本,推理准确率达到77%, 推理耗时0.7秒,性能还可以。
4、小结
以上从随机森林的算法核心思想、原理及应用的视角,对随机森林算法进行了较为形象感观地介绍,避免将算法内部复杂的数学公式及算法逻辑干扰读者对随机森林的了解,如果感兴趣内部的详细实现逻辑,读者可在网上搜索相关的资料进一步了解,相信有了本篇的理解基础,后面再去理解算法内部的实现,会更为简单。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号