第三课 特征工程
AI领域的大神们Bengio和Lecun等人在《Gradient-Based Learning Applied to Document Recognition》论文中划定了AI模型的玩耍范式,如下图所示,无论任何模型,在做分类或回归前,都必须有一个数据特征提取(Feature Extraction)的过程,而为了更方便和准确地提取数据特征,在提取特征前,需要对数据集做预处理,也就是对数据做清洗、统一量纲、标准化、归一化、填补缺漏的数据,如果数据特征太多,需要进行降维处理,此外,还应尽可能地观察数据,人为地对某些特征进行映射转换,以最大程度的提高机器学习算法的准确性,以上这一系列的过程,也即所谓特征工程要干的事情。
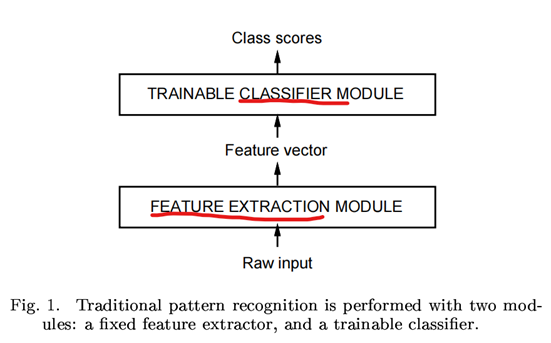
传统机器学习中,特征工程是一个必要且需要大量人工的过程,即强特征工程+弱模型,而在深度学习,对特征工程的要求就降低很多,也不需要人为参与太多,只需将输入数据向量化和标准化后,剩下的特征工程找规律的动作,就交由模型自己学习来完成,这种模式也就是弱特征工程+强模型。
以下以titanic disaster数据集部分数据为例,描述特征工程所需做的事情。
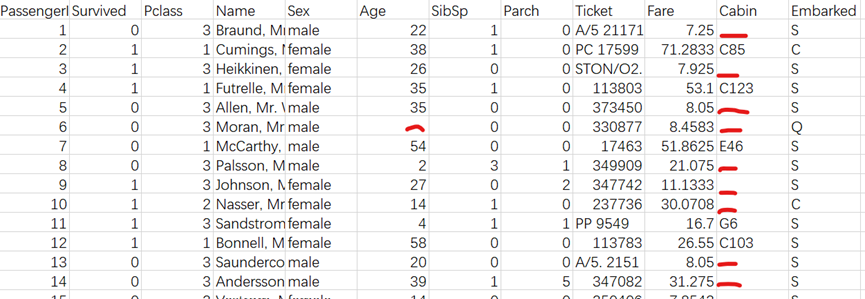
图2 Titanic沉船事故数据集
1、 缺失值处理
一般的策略是不处理、删除缺失数据所在行、采用均值、中位数、众数、同类均值填充。
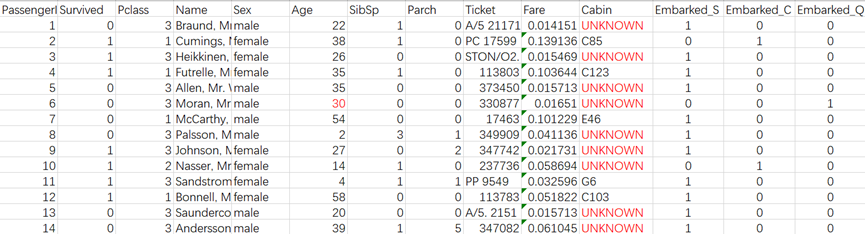
图2中Age、Cabin列的部分数据有缺失,缺失部分已用红色下划线标识。
对于Age中的缺失值,可用该列的平均值进行填充,而Cabin列的缺失值,可引入新的类型UNKOWN进行填充,填充后的数据表如下:
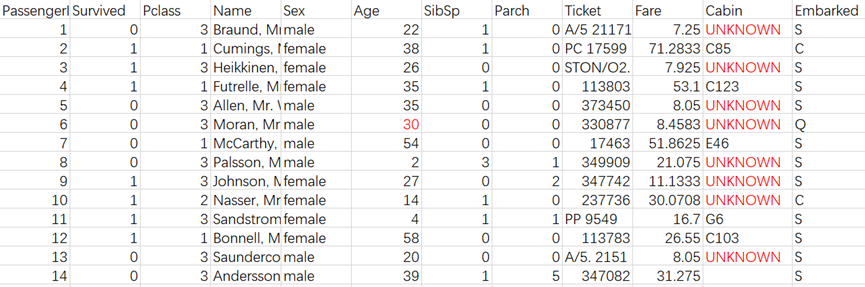
图3缺失值处理后的数据
2、数据转化
以Embark字段为例,其取值类型有S、C、Q三种,但字符无法参与数值计算,需将字符类型转换为数值类型,可使用one-hot编码转换,转换后的数据如下图红框部分所示:
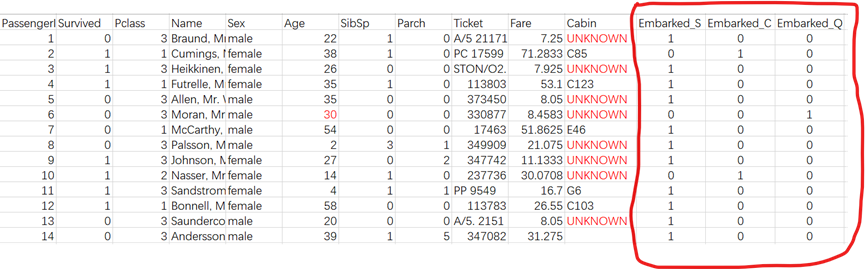
采用one-hot编码是为了规避取值类型间引入不必要的关系,因为各取值类型间本身是无关联的,如果采用S=0, C=1, Q=2的数值转化,则人为地引入了S、C、Q间有大小关联的关系。
其他字段的数据转化以此类推。
3、归一化
Fare字段和PClass字段相比较,其取值明显高于PClass字段,这种情况不利于损失函数快速收敛,需对Fare字段做归一化处理,可通过MinMaxScaler处理,其计算公式为:
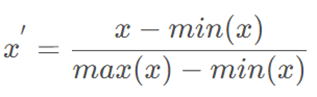
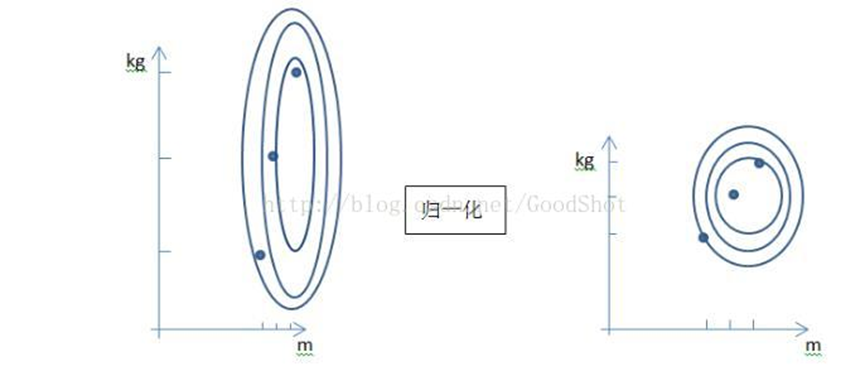
归一化的作用如下图所示,可见归一化后,2个变量间的关系更近似一个圆,这样有利于损失函数的快速收敛。
归一化处理后的数据如下:
除以上的特征处理方法外,还有统一量纲、标准化等常见的数据预处理方法,由于泰坦尼克灾难生还预测数据集中,未用到这两个数据预处理方法,下面只是对统一量纲、标准化在概念上进行简单阐述。
4、统一量纲
一般情况下,拿到的数据集特征属性的取值有些值的量纲是不一样的,所谓的量纲,可理解为数值的单位,比如时间属性,某些样本的时间单位是分钟,而有些样本的时间单位却是秒,对于同一个时间属性字段,出现两种以上不同的数值单位,这对AI计算是不利的,需要将同一字段的所有数值转换为相同单位的值。
5、标准化(Z-Score)
标准化预处理是将某列数据减去其均值,再除以标准差,从而将该列数据拉回标准正态分布的形式,这样做有利于更有效的使用激活函数,加速模型的收敛速度。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号