protocol buffer
Google protocol buffer 使用的意义: 在不使用的情况下,通常我们需要完成两个部分,一个是writter一个是reader。writter负责向磁盘写入消息,reader负责读出消息,如果是定长数据且writter和reader都采用c++编写则会比较方便,采用同样的结构体就行。对于不定长数据稍微麻烦一点,需要定义一个个数,然后再按照约定逐个读取。如果reader才用的是java,则需要先将数据存到一个buffer中,然后再根据约定逐个读取字段。每当我们定义一个消息,我们都要去实现一个reader,这非常繁琐。
关键字
- Message : 类似strut
- Required: 必须设置该字段
- optional:不设置该字段使用默认值,默认值可以自己设定也可以系统提供,数值类型为0,布尔类型为false,字符类型为空
- repeated:该字段可能会重复任意次(包括零次)
- = 1:标签数字,表示该字段在序列化之后的二进制数据中的布局位置,不可以重复,1-15在编码时可以得到优化使标签值和类型信息只占一个byte,16-2047将占两个。
- Enum :和c++一样,需要注意的是 枚举值之间的分隔符是分号
- Import :类似python,可以导入别的文件,然后使用里面定义的message
- package:包名对应生成c++文件的命名空间
还有一些option的设置,就是一些命令帮助生成更符合我们要求的目标语言代码,eg:option optimize_for = SPEED; 表示生成代码效率优先。具体用到了在看吧。
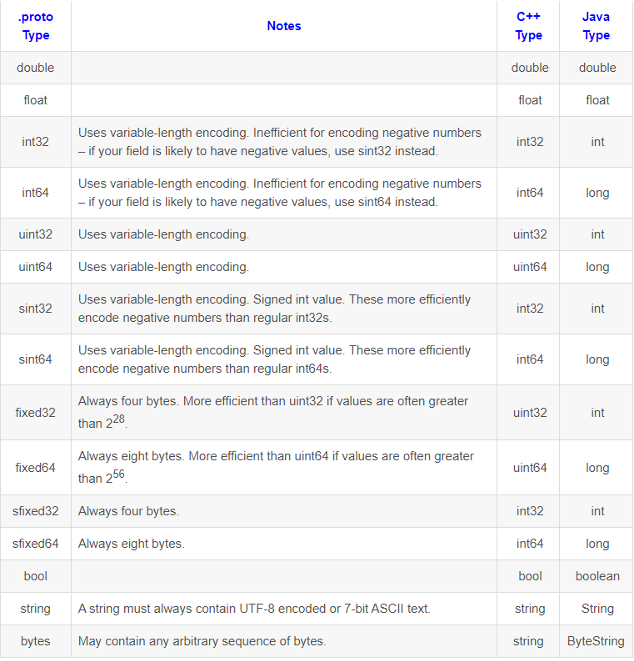
类型对照表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号