爬虫入门;requests
一.爬虫简介
1.什么是爬虫
爬虫是一个模拟浏览器向网站发送请求,获取资源并分析获取有用数据的程序。
2.爬虫的基本流程

#1、发起请求 使用http库向目标站点发起请求,即发送一个Request Request包含:请求头、请求体等 #2、获取响应内容 如果服务器能正常响应,则会得到一个Response Response包含:html,json,图片,视频等 #3、解析内容 解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等 解析json数据:json模块 解析二进制数据:以b的方式写入文件 #4、保存数据 数据库 文件
二.requests


#1、请求方式: 常用的请求方式:GET,POST 其他请求方式:HEAD,PUT,DELETE,OPTHONS ``` ps:用浏览器演示get与post的区别,(用登录演示post) post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz post请求的参数放在请求体内: 可用浏览器查看,存放于form data内 get请求的参数直接放在url后 ``` #2、请求url url全称统一资源定位符,如一个网页文档,一张图片 一个视频等都可以用url唯一来确定 ``` url编码 https://www.baidu.com/s?wd=图片 图片会被编码(看示例代码) ``` ``` 网页的加载过程是: 加载一个网页,通常都是先加载document文档, 在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求 ``` #3、请求头 User-agent:请求头中如果没有user-agent客户端配置, 服务端可能将你当做一个非法用户 host cookies:cookie用来保存登录信息 ``` 一般做爬虫都会加上请求头 ``` #4、请求体 如果是get方式,请求体没有内容 如果是post方式,请求体是format data ``` ps: 1、登录窗口,文件上传等,信息都会被附加到请求体内 2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post ```
一.requests介绍
1.介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3) 2.注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求 3.各种请求方式:常用的就是requests.get()和requests.post() >>> import requests >>> r = requests.get('https://api.github.com/events') >>> r = requests.post('http://httpbin.org/post', data = {'key':'value'}) >>> r = requests.put('http://httpbin.org/put', data = {'key':'value'}) >>> r = requests.delete('http://httpbin.org/delete') >>> r = requests.head('http://httpbin.org/get') >>> r = requests.options('http://httpbin.org/get') #建议在正式学习requests前,先熟悉下HTTP协议 http://www.cnblogs.com/linhaifeng/p/6266327.html
二.requests使用
前提:下载模块
pip3 install requests
1.基于GET请求的使用
1.基本使用
#1.导入模块 import requests #2.发送请求:requests.get('请求地址',其他参数可省略) response=requests.get('http://dig.chouti.com/') #3.获取响应:请求对象.text print(response.text)
2.带参数的GET请求->headers使用
#1.headers作用:主要是将自身伪装成浏览器,一般发送请求的时候都会带着。常见的headers参数和作用如下
Host Referer #大型网站通常都会根据该参数判断请求的来源 User-Agent #客户端 Cookie #Cookie信息虽然包含在请求头里,但requests模块有单独的参数来处理headers={}内就不要放它了
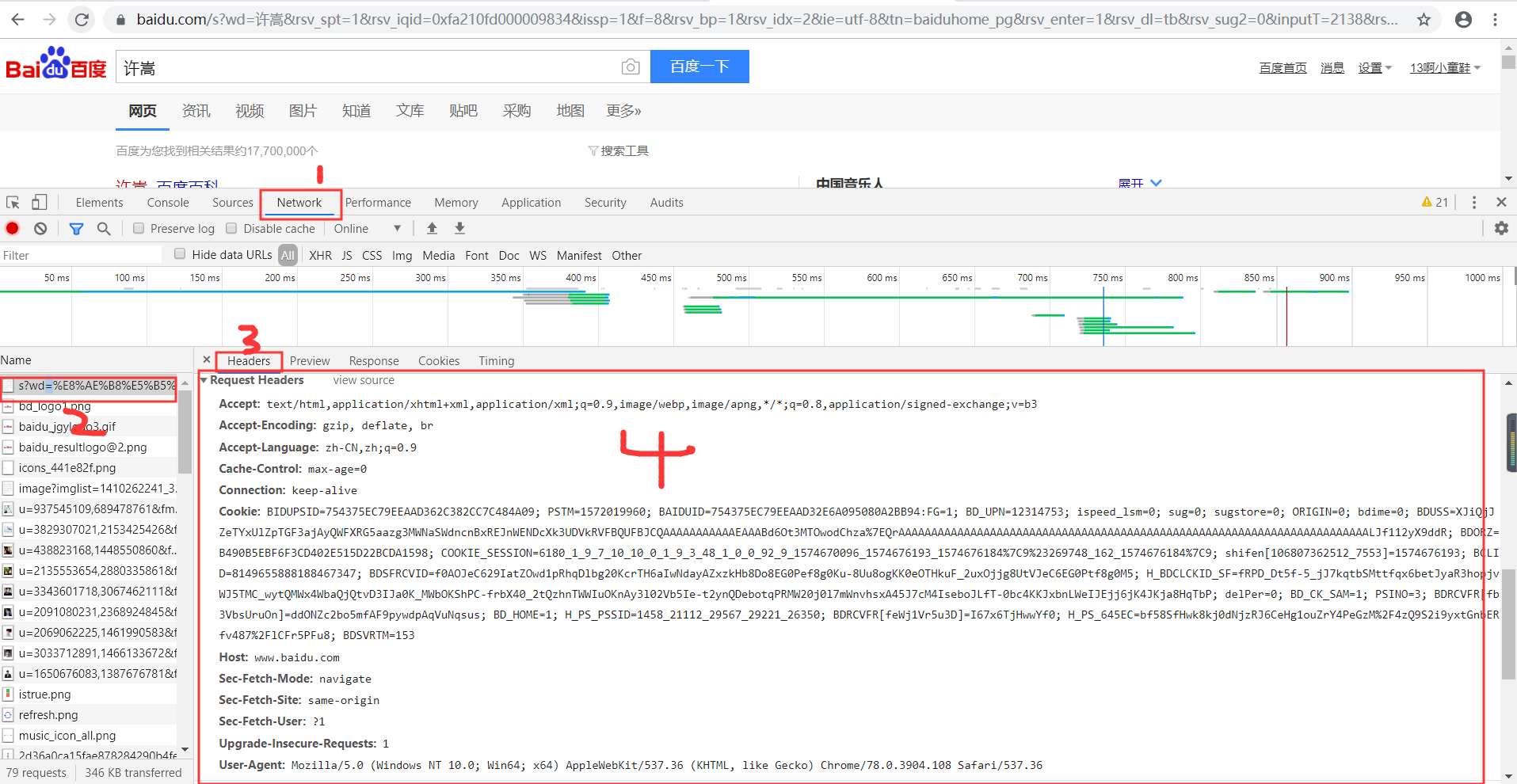
#2.示例:
import requests #自己定制headers headers={ 'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36', } respone=requests.get('https://www.zhihu.com/explore', headers=headers) print(respone.status_code) #200
3.带参数的GET请求->params使用
第一种使用方式手动拼接(不常用,还需自己手动转码)
import requests #如果查询关键词是中文或者有其他特殊符号,则不得不进行url编码 from urllib.parse import urlencode wd='egon老师' encode_res=urlencode({'k':wd},encoding='utf-8') keyword=encode_res.split('=')[1] print(keyword) # 然后拼接成url url='https://www.baidu.com/s?wd=%s&pn=1' %keyword response=requests.get(url, headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36', }) res1=response.text
第二种借用params(常用,会自动转码)
import requests wd='egon老师' pn=1 response=requests.get('https://www.baidu.com/s',
params={'wd':wd, 'pn':pn}, headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1;WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',}
) res2=response.text #验证结果,打开a.html与b.html页面内容一样 with open('a.html','w',encoding='utf-8') as f: f.write(res1) with open('b.html', 'w', encoding='utf-8') as f: f.write(res2)
4.带参数的GET请求->cookies使用
#登录github,然后从浏览器中获取cookies,以后就可以直接拿着cookie登录了,无需输入用户名密码 #用户名:egonlin 邮箱378533872@qq.com 密码lhf@123 import requests Cookies={ 'user_session':'wGMHFJKgDcmRIVvcA14_Wrt_3xaUyJNsBnPbYzEL6L0bHcfc',} response=requests.get('https://github.com/settings/emails',cookies=Cookies) #github对请求头没有什么限制,我们无需定制user-agent,对于其他网站可能还需要定制 print('378533872@qq.com' in response.text) #True
2.基于POST请求使用
介绍
#GET请求 HTTP默认的请求方法就是GET * 没有请求体 * 数据必须在1K之内! * GET请求数据会暴露在浏览器的地址栏中 GET请求常用的操作: 1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求 2. 点击页面上的超链接也一定是GET请求 3. 提交表单时,表单默认使用GET请求,但可以设置为POST #POST请求 (1). 数据不会出现在地址栏中 (2). 数据的大小没有上限 (3). 有请求体 (4). 请求体中如果存在中文,会使用URL编码! #!!!requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
示例
#模拟登录某网站 import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36', 'Referer': 'http://www.aa7a.cn/user.php?&ref=http%3A%2F%2Fwww.aa7a.cn%2F', } res = requests.post('http://www.aa7a.cn/user.php', headers=headers, data={ 'username': '616564099@qq.com', 'password': 'lqz123', 'captcha': 'pnz4', 'remember': 1, 'ref': 'http://www.aa7a.cn/', 'act': 'act_login' } ) #如果登录成功,cookie会存在于res对象中 cookie=res.cookies.get_dict() #向首页发送get请求 res=requests.get('http://www.aa7a.cn/',headers=headers, cookies=cookie, ) if '616564099@qq.com' in res.text: print("登录成功") else: print("没有登录")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号