数据类型及其常用方法 数据类型转换 可变与不可变 值拷贝与深浅拷贝


# 了了解:py2中小整数用int存放,大整数用long # 1.整型 num = -1000000000000000000000000000000000000000000000000 print(num, type(num)) # 2.小数 num = 3.14 print(num, type(num)) # 3.布尔 res = True print(res, type(res), isinstance(res, int)) print(3.14 + True) # 4.复数 num = complex(5, 4) # 5 + 4j print(num + (4 + 5j)) #5. 重点:数字类型直接的相互转化 *****》》整型,浮点型,布尔之间直接相互转换不涉及所谓的四舍五入: a = 10 b = 3.44 c = True d = False print(int(a), int(b), int(c),int(d)) #10 3 1 0 print(float(a), float(b), float(c),float(d)) #10.0 3.44 1.0 0.0 print(bool(a), bool(b), bool(c),bool(d)) #True True True False
1.索引取值:只能取,正向取值从0编号,反向取值从-1编号 msg='hello world' print(msg[4]) # o print(msg[-1]) # d # msg[3]='A' # 报错 2.切片:就是从原符串中切分出一个全新的子字符串 注意:[start_index:end_index:step] 1.包含初始值,不包含结束值,2.步长默认为1,正号正向取,步长为带负号数反向取 3.步长-1:为2个元素之间隔几个,前一个元素索引+步长:为下一个元素 s4 = '123abc呵呵' sub_s = s4[0:6] print(sub_s) # 123abc sub_s = s4[0:6:2] print(sub_s) # 13b sub_s = s4[::-1] print(sub_s) # 呵呵cba321 sub_s = s4[-1:-6:-1] print(sub_s) # 呵呵cba 3.字符串拼接,格式化输出 方式1:‘+’同类型拼接 s2 = '你好' s22 = '帅' print(s2 + s22) #你好帅 方式2:%s:万能占位符 # 如果要拼接其他类型 a = 10 b = "20" c = True # res = "1020True" res = "%s%s%s" % (a, b, c) # 方法1 print(res) res = str(a) + b + str(c) # 方法2 print(res) 方式3:format三种方法:位置,索引,关键字 s8 = 'name:{},age:{}' print(s8.format('Owen', 18)) # 默认按位置:name:Owen,age:18 print('name:{1},age:{1}, height:{1}'.format('Owen', 18)) # 标注位置,一个值可以多次利用:name:18,age:18, height:18 print('name:{n},age:{a}, height:{a}'.format(a=18, n="Zero")) # 指名道姓:name:Zero,age:18, height:18 4.len(字符串):字符串长度 s3 = '12345' ln1 = s3.__len__() print(ln1) #5 ln2 = len(s3) print(ln2) #5 5.成员运算in和not in: 判断一个子字符串是否存在于一个大的字符串中 s5 = '123abc呵呵' ss5 = '12a' print(ss5 in s5) # False print(ss5 not in s5) # True 6.字符串循环(遍历) s6 = '123abc呵呵' for v in s5: print(v)
二.重要方法
1.获取子字符串的索引:字符串.index(目标字符串) s1 = '123abc呵呵' print(s1.index('b')) #4 2.去留白(默认去两端留白,也可以去指定字符)只能除出左右两端 s2 = '***好 * 的 ***' print(s2.strip('*')) #好 * 的 s2 = '***$好 * 的 ***' print(s2.strip('*$')) #好 * 的 拓展: print('*****egon*****'.lstrip('*')) #egon***** print('*****egon*****'.rstrip('*')) #*****egon 3.计算子字符串个数 s3 = '12312312' print(s3.count('123')) #2 4.字符串.isdigit():判断字符串是否是数字:只能判断正整数 s4 = '123' print(s4.isdigit()) #True 5.大小写转换 s5 = "AbC def" print(s5.upper()) # 全大写 ABC DEF print(s5.lower()) # 全小写 abc def # 了了解 print(s5.capitalize()) # 首字母大写Abc def print(s5.title()) # 每个单词首字母大写Abc Def 6.以某某开头或结尾 s6 = 'https://www.baidu.com' r1 = s6.startswith('https:') r2 = s6.startswith('http:') r3 = s6.endswith('com') r4 = s6.endswith('cn') if (r1 or r2) and (r3 or r4): print('合法的链接') else: print('非合法的链接') 7.替换(后者替换前者) s7 = 'egon say: he is da shuai b,egon!egon!egon!' new_s7 = s7.replace('egon', 'Liu某') # 默认替换所有:Liu某 say: he is da shuai b,Liu某!Liu某!Liu某! print(new_s7) new_s7 = s7.replace('egon', 'Liu某', 1) # 替换一次:Liu某 say: he is da shuai b,egon!egon!egon! print(new_s7)
三.了解方法
1. find | rfind:查找子字符串索引,无结果返回-1 2. lstrip:去左留白 3. rstrip:去右留白 4. center | ljust | rjust | zfill:按位填充 语法:center(所占位数, '填充符号') 5. expandtabs:规定\t所占空格数 6. captialize | title | swapcase:首字母大写 | 单词首字母大写 | 大小写反转 7. isdigit | isdecimal | isnumeric:数字判断 8. isalnum | isalpha:是否由字母数字组成 | 由字母组成 9. isidentifier:是否是合法标识符 10. islower | isupper:是否全小 | 大写 11. isspace:是否是空白字符 12. istitle:是否为单词首字母大写格式
四.字符串与列表的相互转换
#1.split,rsplit msg='get|a.txt|333331231' print(msg.split('|',1)) #['get', 'a.txt|333331231'] print(msg.rsplit('|',1)) #['get|a.txt', '333331231'] #2.join msg='get|a.txt|333331231' l=msg.split('|') print(l) #['get', 'a.txt', '333331231'] src_msg='|'.join(l) print(src_msg) #get|a.txt|333331231
一.增删改查
增: #1.尾增:列表.append(值) ls1=['egon','lxx','yxx'] ls1.append(44444) ls1.append(55555) print(ls1) # ['egon', 'lxx', 'yxx', 44444, 55555] #2.往指定索引前插入值:列表.insert(索引,值) ls2=['egon','lxx','yxx'] ls2.insert(0,11111) print(ls2) # [11111, 'egon', 'lxx', 'yxx'] ls2.insert(2,2222222) print(ls2) # [11111, 'egon', 2222222, 'lxx', 'yxx'] #3. 整体增加,添加到末尾:列表.extend(列表或元组) ls3 = ['jason','nick'] ls3.extend(['tank','sean']) # ls3.extend(('tank','sean')) #元组也可以 print(ls3) # ['jason', 'nick', 'tank', 'sean'] 删: # 方式1通用的:del 列表[删除值得索引] ls1=['egon','lxx','yxx'] del ls1[1] # 通用的 print(ls1) #['egon', 'yxx'] # 方式2删除指定的值:列表.remove(要删除的值) ls2=['egon','lxx','yxx'] res=ls2.remove('lxx') # 指定要删除的值,返回是None print(ls2,res) #['egon', 'yxx'] None # 方式3末尾删和指定索引删:默认末尾删:列表.pop() 指定索引删:列表.pop(索引) ls3=['egon','lxx','yxx'] res1=ls3.pop() # 默认是从末尾删除,返回删除的那个值 print(ls3,res1) # ['egon', 'lxx'] yxx ls4=['egon','lxx','yxx'] res2=ls4.pop(0) # 指定索引删 print(ls4,res2) # ['lxx', 'yxx'] egon # 方式4清空 ls4=['egon','lxx','yxx'] ls4.clear() print(ls4) # [] 改 #列表[索引] = 要改的值 ls = [1,2,3] ls[1] = 66666 print(ls) # [1, 66666, 3] 查 #列表[索引] ls = [1, 2, 3] print(ls[1]) # 2
二.其他方法
1.列表运算: 得到的是新list s2 = [1, 2, 3] print(s2 + s2) #[1, 2, 3, 1, 2, 3] print(s2 * 2) #[1, 2, 3, 1, 2, 3] print(s2) #[1, 2, 3] 2.list的长度:len(列表)求列表中的个数 s3 = [3, 4, 1, 2, 5] print(len(s3)) #5 3.切片与字符串的相似:[start_index:end_index:step]》》1.包含初始值,不包含结束值,2.步长为正号正向取,步长为带符号数反向取 s4 = [3, 4, 1, 2, 5] new_s4 = s4[::-1] print(new_s4) #[5, 2, 1, 4, 3] new_s4 = s4[1:4:] print(new_s4) #[4, 1, 2] new_s4 = s4[-2:-5:-1] print(new_s4) #[2, 1, 4] 4.成员运算:in|not in》》注意成员类型例: s5 = [3, 4, '1', 2, 5] print('1' in s5) #True print(1 in s5) #False print(5 not in s5) #False 5.循环 for v in s5: print(v, type(v)) #结果 3 <class 'int'> 4 <class 'int'> 1 <class 'str'> 2 <class 'int'> 5 <class 'int'> # 只打印数字类型的数据 for v in s5: if isinstance(v, int): print(v, end=' ') # 3 4 2 5
字典
一.增删改查
1.增:字典名[key] = 值 => key已存在就是修改值,不存在就是新增值 dic = {'a': 1, 'b': 2} dic['c'] = 3 print(dic) #{'a': 1, 'b': 2, 'c': 3} 2.删 dic = {'a': 1, 'b': 2} 方式1通用:del[key] del dic['a'] print(dic) #{'b': 2} del dic['xxx'] ##key不存在则报错 方式2删除指定key的value并返还删除的value和列表的相似:字典名.pop(k) res = dic.pop('a') print(dic,res) #{'b': 2} 1 方式3从dic末尾删除,返还(key, value)形成的元组:字典名.popitem() res = dic.popitem() print(dic, res) #{'a': 1} ('b', 2) 方式4清空:字典名.clear() dic.clear() 3.改 dic = {'a': 1, 'b': 2} 方式1: dic['b'] = 3 print(dic) #{'a': 1, 'b': 3} 方式2: dic = {'a': 1, 'c': 2} d = {'a': 10, 'b': 20} dic.update(d) print(dic) # {'a': 10, 'c': 2, 'b': 20} 方式3 带默认值的新增: 新增key,key已有,啥事不干,没有添加key,值就是第二个参数 dic.setdefault('z', 100) print(dic) 查: dic = {'a': 1, 'b': 2} 方式1:字典名[key] print(dic['c']) # 只能查找已有的key,没有崩溃 # 有默认值的查询:有key取出对应value,没有返还默认值,默认值可以自定义 print(dic.get('d', 'http://www.baidu.com'))
二.其他方法
1.字典的循环:直接循环,就是循环得到key dic = {'a': 1, 'b': 2} for k in dic: print(k) 2.循环键:字典名.keys() print(dic.keys()) #dict_keys(['a', 'b']) for k in dic.keys(): print(k) # a,b 3.循环values print(dic.values()) #dict_values([1, 2]) for v in dic.values(): print(v) #1,2 4.#同时循环key和value (key, value):字典名.items() print(dic.items()) #dict_items([('a', 1), ('b', 2)]) # a, b = (1, 2) # print(a, b) for res in dic.items(): print(res) # ('a', 1) ('b', 2) # 重点 for k, v in dic.items(): print(k, v) #a 1,b 2
三.字典定义
# 空字典 d1 = {} d2 = dict() # 用map映射创建字典 d3 = dict({'a': 1, 'b': 1}) print(d3) # {'a': 1, 'b': 1} # 用关键字赋值方式 d4 = dict(name='Bob', age=18) # 参数=左侧的名字就是合法的变量名,都会被转化为字符串形式的key print(d4) #{'name': 'Bob', 'age': 18} # 创建有多个key值采用默认值的方式: 默认值不写默认None,也可以自定义 d5 = {}.fromkeys('abc', 0) print(d5) # {'a': 0, 'b': 0, 'c': 0}
元组:可以理解为不可变的列表 # 1.值可以为任意类型 # 2.可以存放多个值 - 可以进行成员运算 # 3.可以存放重复的值 - 可以计算成员出现的次数 # 4.有序存储 - 可以通过索引取值,可以切片
一.元组常用操作
1.索引取值 t1 = (1,2,3,'a','b') print(t1[1], type(t1[1])) #2 <class 'int'> print(t1[-3]) #3 2.运算(拼接) print((1, 2) + (2, 3))# (1, 2, 2, 3) 3.长度 print(len(t1)) 4.切片 print((2, 1, 3)[::-1]) 5.成员运算 print(True in t1) print(False in t1) # False == 0, t1中如果有0或False,该结果都是True 6.for循环 for obj in t1: print(obj, end=" ") 7. print(t1.count(0)) # 对象0在元组中出现的次数 print(t1.index(0, 4, len(t1))) # 对象0,在区间4~末尾第一次出现的索引
# 空集合:不能用{},因为用来标示空字典 s = set() print(s, type(s)) # 概念: # 1.set为可变类型 - 可增可删 # 2.set为去重存储 - set中不能存放重复数据 # 3.set为无序存储 - 不能索引取值 # 4.set为单列容器 - 没有取值的key # 总结:set不能取值 # 增 s.add('1') s.add('2') s.add('1') print(s) s.update({'2', '3'}) print(s) # 删 # res = s.pop() # print(res) # s.remove('1') # print(s) s.clear() print(s) # set运算 # 交集:两个都有 & py = {'a', 'b', 'c', 'egon'} lx = {'x', 'y', 'z', 'egon'} print(py & lx) print(py.intersection(lx)) # 合集:两个的合体 | print(py | lx) print(py.union(lx)) # 对称交集:抛出共有的办法的合体 ^ print(py ^ lx) print(py.symmetric_difference(lx)) # 差集:独有的 print(py - lx) print(py.difference(lx)) # 比较:前提一定是包含关系 s1 = {'1', '2'} s2 = {'2'} print(s1 < s2)
1.字符串转化为数字类型
res = int('10')
print(res)
res = int('-3')
print(res)
res = float('.15')
print(res)
res = float('-.15')
print(res)
res = float('-3.15')
print(res)
#注意:需要判断所有能被转换为数字类型的字符串,并转化
2.数字转化字符串
print(str(10))
3.字符串与列表相互转换 ******
s = 'abc123呵呵'
print(list(s)) # ['a', 'b', 'c', '1', '2', '3', '呵', '呵'] 没有对应的 str(ls)
ls = ['a', 'b', 'c', '1', '2', '3', '呵', '呵']
n_s = ''.join(ls)
print(n_s) # 'abc123呵呵'
# s1 = 'a b c 1 2 3 呵 呵'
# res = s1.split() # 默认按空格拆
s1 = 'a b c 1 2 3 呵 呵'
res = s1.split()
print(res)
# 必须掌握
s2 = 'ie=UTF-8&wd=你好帅'
res = s2.split('&')
print(res) # ['ie=UTF-8', 'wd=你好帅']
ls2 = ['ie=UTF-8', 'wd=你好帅']
n_s2 = '@'.join(ls2)
print(n_s2) # ie=UTF-8@wd=你好帅
# 4.需求:"ie=UTF-8&wd=你好帅" => [('ie', 'UTF-8'), ('wd', '你好帅')]
res = []
s4 = "ie=UTF-8&wd=你好帅"
ls4 = s4.split('&') # ['ie=UTF-8', 'wd=你好帅']
for ele in ls4: # v = ie=UTF-8 | wd=你好帅
k, v = ele.split('=') # k: ie v: UTF-8
res.append((k, v))
print(res)
# 5.需求:"ie=UTF-8&wd=你好帅" => {'ie': 'UTF-8', 'wd': '你好帅'}
res = {}
s5 = "ie=UTF-8&wd=你好帅"
ls5 = s5.split('&') # ['ie=UTF-8', 'wd=你好帅']
for ele in ls5: # v = ie=UTF-8 | wd=你好帅
k, v = ele.split('=') # k: ie v: UTF-8
res[k] = v
print(res)
# 6.需求:[('ie', 'UTF-8'), ('wd', '你好帅')] => {'ie': 'UTF-8', 'wd': '你好帅'}
res = {}
ls6 = [('ie', 'UTF-8'), ('wd', '你好帅')]
for k, v in ls6:
res[k] = v
print(res)
# 7.list与tuple、set直接相互转化 - 直接 类型()
# 8.需求:将汉字转化为数字
# 将 壹、贰、叁、肆、伍、陆、柒、捌、玖、拾、佰、仟
# 转化为 1、2、3、4、5、6、7、8、9、10、100、100
# 作业:壹仟捌佰玖拾叁 => 1893
num_map = {
'壹': 1,
'贰': 2,
'仟': 1000
}
ls8 = ['贰', '壹', '仟']
res = []
for v in ls8:
num = num_map[v] # 通过key去映射表拿到对应的值,完成 '贰' => 2
res.append(num)
print(res)
可变类型:值改变的情况下,id不变 如:列表,字典,集合
不可变类型:值改变的情况下,id也跟着改变
1、可变类型
值改变,id不变,证明改的是原值,证明原值是可以被修改的。
可变类型有:list、dict
验证#
list
# 修改前
li = ['aaa', 'bbb', 'ccc']
print(li) # ['aaa', 'bbb', 'ccc']
print(id(li)) # 1534124489600
# 修改后
li[0] = 'AAA'
print(li) # ['AAA', 'bbb', 'ccc']
print(id(li)) # 1534124489600
dict
这里争对了字典的补充,原先我们说{}号内用逗号隔开key:value的形式,key唯一,通常(99%的情况下,字典的key都是字符串)为字符串类型(因为字符串具有描述性),值可以是任意类型。
之前所说的key通常为字符串类型,完整的说字典的key必须是不可变类型,下面用了4种不可变类型举例(int,float,bool,str):
# 修改前
dic = {100: 'int', 'AAA': 'str', True: 'bool', 3.14: 'float'}
print(dic) # {100: 'int', 'AAA': 'str', True: 'bool', 3.14: 'float'}
print(id(dic)) # 1443792249408
# 修改后
dic[100] = 'int-100'
print(dic) # {100: 'int-100', 'AAA': 'str', True: 'bool', 3.14: 'float'}
print(id(dic)) # 1443792249408
2、不可变类型#
值改变了,id也变了,证明是产生新的值,压根没有改变原值。
不可变类型有:int、float、str
验证#
int
# 修改前
x = 10
print(id(x)) # 140715012507584
# 修改后,下面使用了变量赋值、以及增量赋值2种修改方式
x = 20
print(id(x)) # 140715012507904
x += 20
print(id(x)) # 140715012508544
float
# 修改前
x = 10.3
print(id(x)) # 1818265421872
x = 20.3
# 修改后,下面使用了变量赋值、以及增量赋值2种修改方式
print(id(x)) # 1818264232976
x += 20.3
print(id(x)) # 1818265422256
str
# 修改前
x = 'aaa'
print(id(x)) # 1614906980528
# 修改后
x = 'AAA'
print(id(x)) # 1614906972400
bool
# 修改前
x = True
print(id(x)) # 140715012228944
# 修改后
x = False
print(id(x)) # 140715012228976
总结:#
int、float、str、bool都被设计成了不可分割的整体,不能够被改变
3、可变类型与不可变类型的值修改的底层原理#
可变类型#
可变类型,像list这种容器类型,修改的是容器里面的值,而并不是对容器本身的修改,对容器本身的修改,id肯定会变化。我们所知列表是索引取值,容器中是有索引映射值得内存地址,当我们修改值时,修改得其实是值得内存地址,容器类型本身得内存地址并不会发生变化,所以id查看修改后的内容时,该列表对于于内存中得id编号并不会发生改变。
不可变类型#
不可变类型,像int整型,举个例子:先age=18,后age=19,前者值18的内存空间对于变量名age,当执行到后者age=19时,会开辟一个新的内存空间(这里忽略python解释器自带的小整数池的这种优化机制),把值19放到堆区,栈区中age映射到值19的内存地址的位置,这个时候就与值18的内存地址映射关系断开,而值19这个新开辟出来的内存地址当然于值18的内存地址不一样,所以说查看id时,id编号一定是不一致的,在这个过程中原值18并没有改变,这就是不可变类型。
import copy
# 值拷贝:应用场景最多
ls = [1, 'abc', [10]]
ls1 = ls # ls1直接将ls中存放的地址拿过来
# ls内部的值发生任何变化,ls1都会随之变化
ls2 = ls.copy() # 新开辟列表空间,但列表中的地址都是直接从ls列表中拿来
# ls内部的可变类型值发生改变,ls2会随之变化
ls3 = copy.deepcopy(ls) # 新开辟列表空间,ls列表中的不可变类型的地址直接拿过来,但是可变类型的地址一定重新开辟空间
# ls内部的所有类型的值发生改变,ls3都不会随之变化
一、为什么要有深浅拷贝
- 当涉及到容器类型的修改操作时,想要保留原来的数据和修改后的数据,这个时候就需要深浅拷贝。
二、赋值操作

source_list = ['aaaa', 1111, ['bbbb', 2222]]
new_list = source_list
# 观察1:源列表与新列表都是指向同一内存地址
print('-------------------------观察1---------------------------')
print(id(source_list), id(new_list)) # 2119311293696 2119311293696
# 修改不可变类型
source_list[0] = 'AAAA'
# 修改可变类型中的值
source_list[-1][-1] = 3333
# 观察2:只要有一个人的列表中的索引所对应的值的内存地址改变,则都改变
print('-------------------------观察2---------------------------')
print(id(source_list), id(new_list)) # 2119311293696 2119311293696
print(id(source_list[0]), id(new_list[0])) # 2119312019888 2119312019888
print(id(source_list[-1][-1]), id(new_list[-1][-1])) # 2119311395248 2119311395248
# 总结:
"""
赋值操作列表与新列表都是指向同一内存地址,2个列表中,只要有一个人的列表中的索引所对应的值的内存地址改变,则都改变
"""
- 结论:赋值操作是把源列表容器的内存地址完完整整的多绑定一份交给新列表。
三、浅拷贝#
-
用法:list.copy()
-
观察1:对源列表copy以后,产生的新列表内存地址发生了改变,不再是同一个列表。而新列表与源列表中的可变不可变类型的值在没修改之前都是指向同一个值。

- 观察2:对源列表中不可变类型的值进行修改以后,对于不可变类型的值,都是产生新值,让源列表的索引指向新的内存地址,并不会影响新列表。
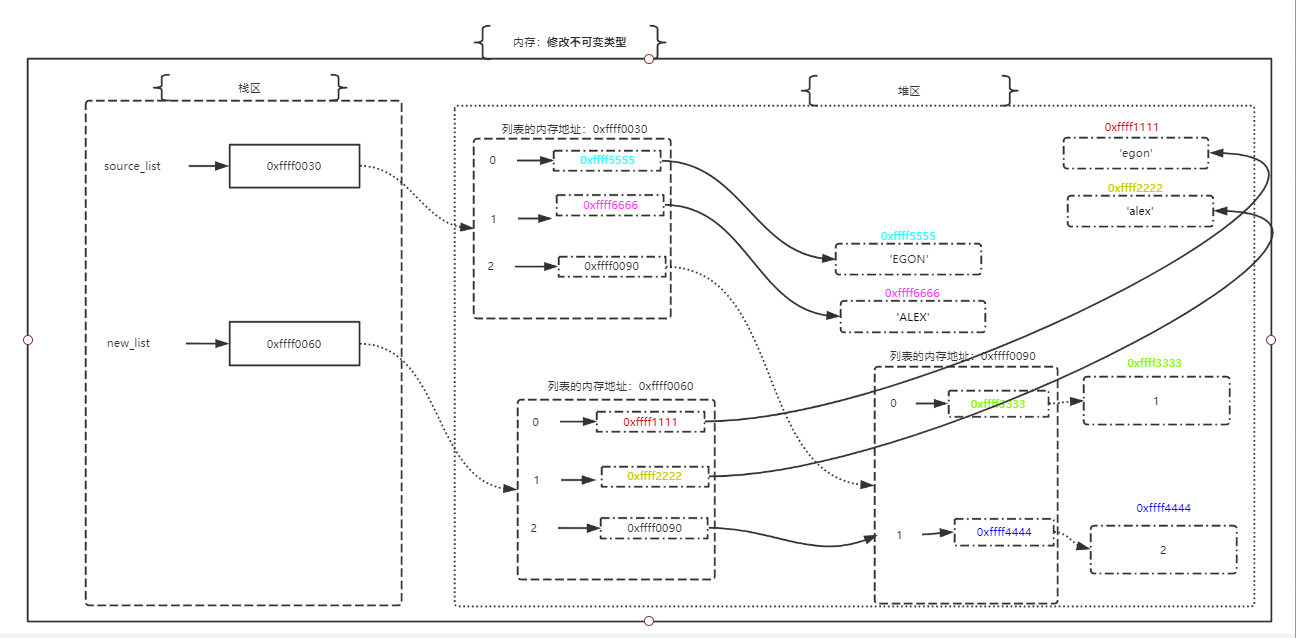
- 观察3:对源列表中可变类型的值进行修改以后,对于可变类型,我们可以改变类型中包含的值,但这个可变容器本身内存地址不变。即新列表的索引仍然指向原来的内存地址,于是新列表也跟着受影响。

- 代码示例
source_list = ['egon', 'alex', [1, 2]]
new_list = source_list.copy()
# 观察1:对源列表copy以后,产生的新列表内存地址发生了改变,不再是同一个列表。而新列表与源列表中的可变不可变类型的值在没修改之前都是指向同一个值。
print('-------------------------观察1---------------------------')
print(new_list) # ['egon', 'alex', [1, 2]]
print(id(source_list), id(new_list))
print(id(source_list[0]), id(source_list[1]), id(source_list[2]))
print(id(new_list[0]), id(new_list[1]), id(new_list[2]))
# 观察2:对源列表中不可变类型的值进行修改以后,对于不可变类型的值,都是产生新值,让源列表的索引指向新的内存地址,并不会影响新列表。
print('-------------------------观察2---------------------------')
source_list[0] = 'EGON'
source_list[1] = 'ALEX'
print(source_list) # ['EGON', 'ALEX', [1, 2]]
print(id(source_list[0]), id(source_list[1]), id(source_list[2]))
print(id(new_list[0]), id(new_list[1]), id(new_list[2]))
# 观察3:对源列表中可变类型的值进行修改以后,对于可变类型,我们可以改变类型中包含的值,但这个可变容器本身内存地址不变。即新列表的索引仍然指向原来的内存地址,于是新列表也跟着受影响。
print('-------------------------观察3---------------------------')
print(id(source_list[2]), id(source_list[2][0]), id(source_list[2][1]))
print(id(new_list[2]), id(new_list[2][0]), id(new_list[2][1]))
source_list[-1][0] = 111
source_list[-1][1] = 222
print(new_list)
print(source_list) # ['EGON', 'ALEX', [1, 2]]
print(id(source_list[2]), id(source_list[2][0]), id(source_list[2][1]))
print(id(new_list[2]), id(new_list[2][0]), id(new_list[2][1]))
# 总结
"""
1、对源列表copy以后,产生的新列表内存地址发生了改变,不再是同一个列表。而新列表与源列表中的可变不可变类型的值在没修改之前都是指向同一个值。
2、对源列表中不可变类型的值进行修改以后,对于不可变类型的值,都是产生新值,让源列表的索引指向新的内存地址,并不会影响新列表。
3、对源列表中可变类型的值进行修改以后,对于可变类型,我们可以改变类型中包含的值,但这个可变容器本身内存地址不变。即新列表的索引仍然指向原来的内存地址,于是新列表也跟着受影响。
"""
# 引申:综合观察2与观察3可以得出,想要copy得到新的列表与源列表的改操作完全独立开,必须有一种可以区分开可变类型与不可变类型的copy机制,这就是深copy。
- 结论:把源列表第一层的内存地址不加区分的完全copy给一份新列表。(这里区分指的是可变,不可变类型的区分)
四、深拷贝#
- 深拷贝对容器类型中的每一层得数据加以区分,对可变不可变类型区分对待。
- 争对不可变类型,拷贝以后任然还是用原来值的内存地址(省空间),但是当值一改,这时会开辟新的内存空间产生新的值,并与之绑定,于此同时两者之间互不影响。
- 争对可变类型,拷贝以后会开辟新得容器地址,在这个新的容器地址中,再次区分可变不可变类型。如果是不可变类型任然用原来值得内存地址(省空间),但是当值一改,这时又会开辟新的内存空间产生新的值,并与之绑定。如果是可变类型则又会开辟新得容器地址,再次对容器中得可变不可变类型进行判断、区分,以此类推。
- 用法:第一步:import copy 第二步:copy.deepcopy(list)
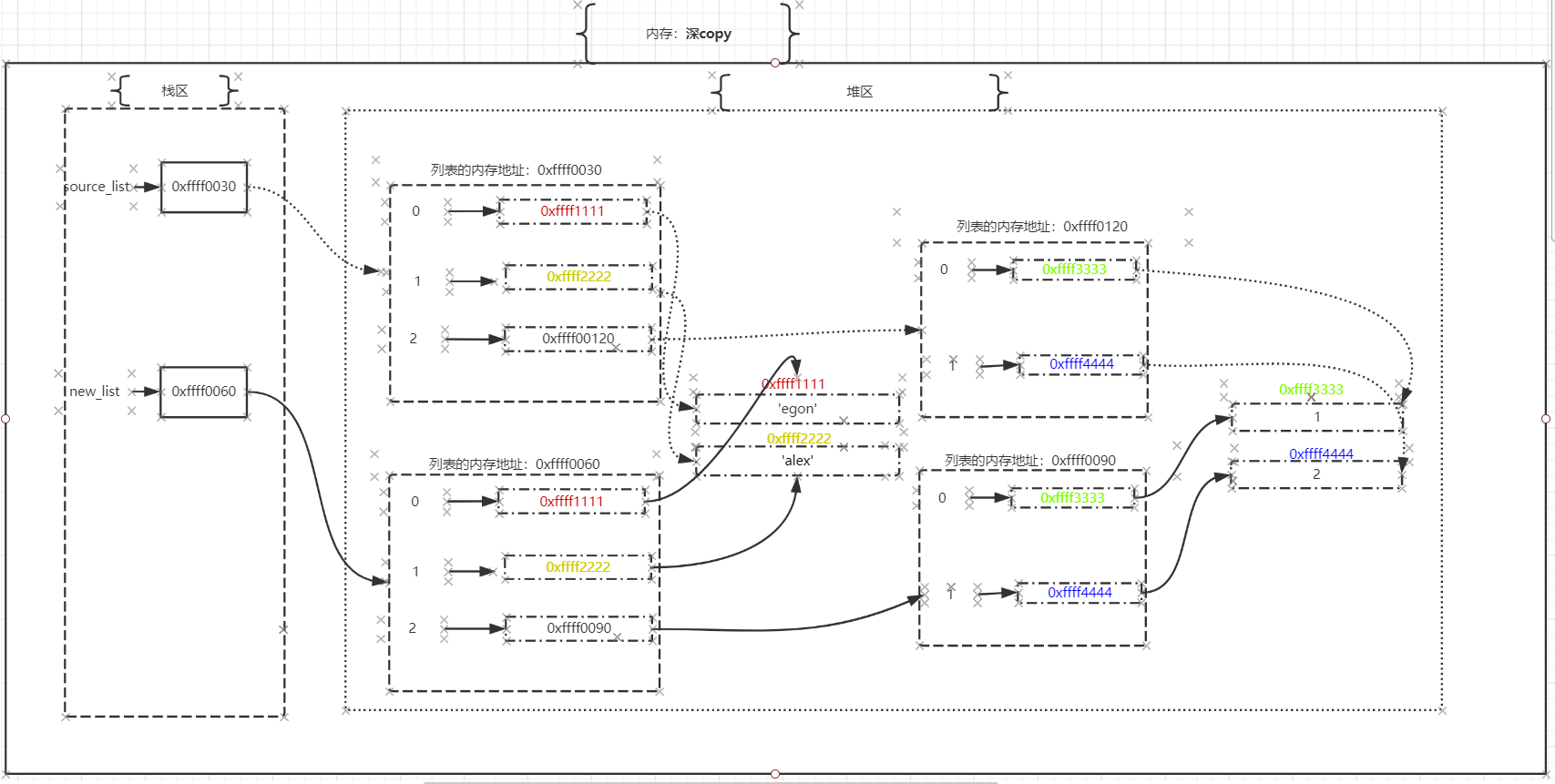
- 观察1:
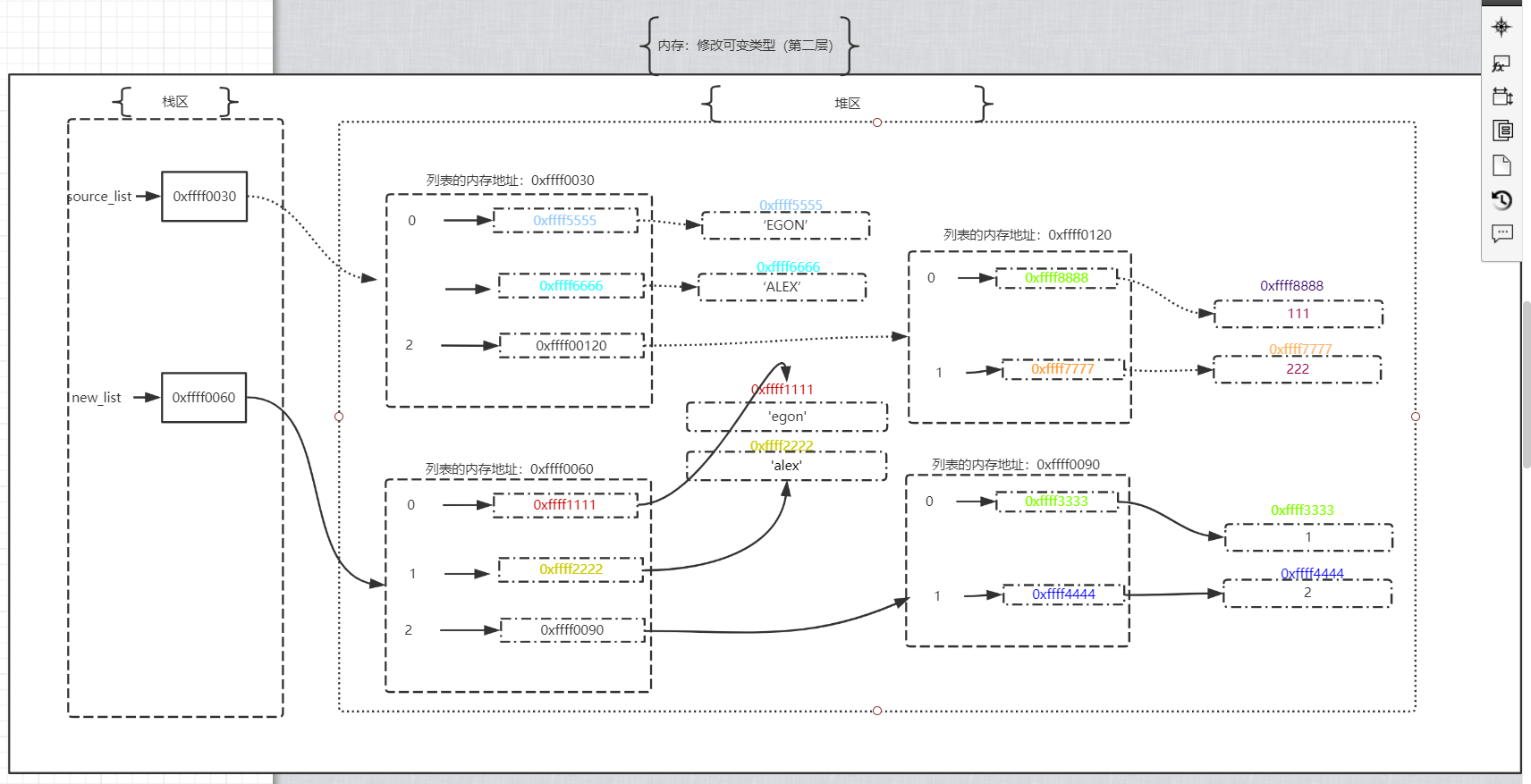
- 观察2:

- 观察3:
- 代码示例
import copy
source_list = ['egon', 'alex', [1, 2]]
new_list = copy.deepcopy(source_list)
print(new_list)
print(id(source_list), id(new_list))
print('------------查看容器第一层------------')
print(' 不可变 不可变 可变')
print(id(source_list[0]), id(source_list[1]), id(source_list[2]))
print(id(new_list[0]), id(new_list[1]), id(new_list[2]))
print('------------查看容器第二层------------')
print(id(source_list[2][0]), id(source_list[2][1]))
print(id(new_list[2][0]), id(new_list[2][1]))
# 修改容器第一层的值:修改不可变类型
source_list[0] = 'EOGN'
source_list[1] = 'ALEX'
# 修改容器第二层的值:修改可变类型
source_list[2][0] = 111
source_list[2][1] = 222
print('------修改以后,修改源列表,新列表所有值不会一起受影响-------')
print(source_list)
print(new_list)
- 结论:把两个列表完完整整独立开,并且只争对该操作而不是读操作。
深浅使用总结#
- 使用浅copy:如果你想对容器类型进行修改操作时,想保留原来的数据和修改后的数据,这时只有容器类型的第一层全是不可变类型,这个时候就用浅copy。
- 使用深copy:如果你想对容器类型进行修改操作时,想保留原来的数据和修改后的数据,且你想让两个列表完完全全独立开,这个时候就用深copy。
作者: 给你家马桶唱疏通
出处:https://www.cnblogs.com/yang1333/articles/12451969.html
版权:本文采用「署名-非商业性使用-相同方式共享 4.0 国际」知识共享许可协议进行许可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
退出 订阅评论 我的博客
[Ctrl+Enter快捷键提交]