java集合框架
java集合框架
1.集合框架的由来
1.1什么是集合框架?
集合框架是为表示和操作集合而规定的一种统一的标准的体系结构。任何集合框架都包含三大块内容:对外的接口、接口的实现和对集合运算的算法.
1.2为什么要有集合框架?
其实在java2之前,java是没有完整的集合框架的,只有一些简答的容器类比如Vector类、Stack类,HashTable类等等。容器类就是用来存储数据。这里数据只能是引用类型的数据,当然,一说到存储数据很快我们会想到数组,数组是可以存储相同类型,可以是基本类型,也可以是引用类型。
数组也存在很多的弊端:
- 数组一旦初始化,长度是固定的,不能再改变了。
- 每次使用都得编写操作数组的方法,体现不了java的封装思想。
java把集合框架的类和接口都放在了java.util包中
2.集合体系
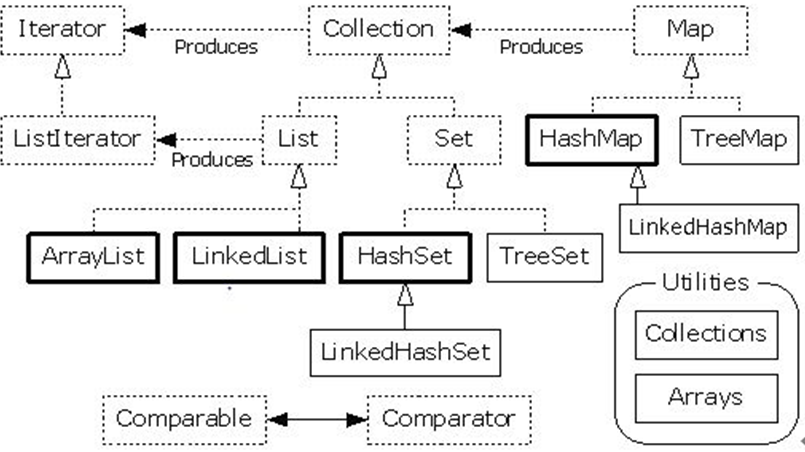
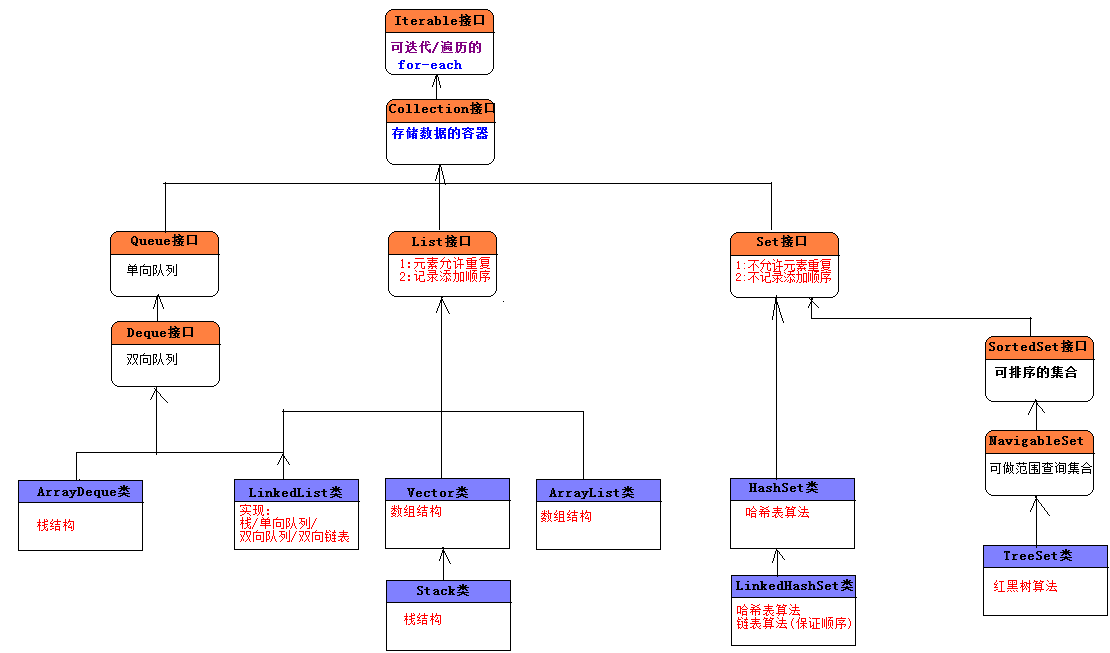
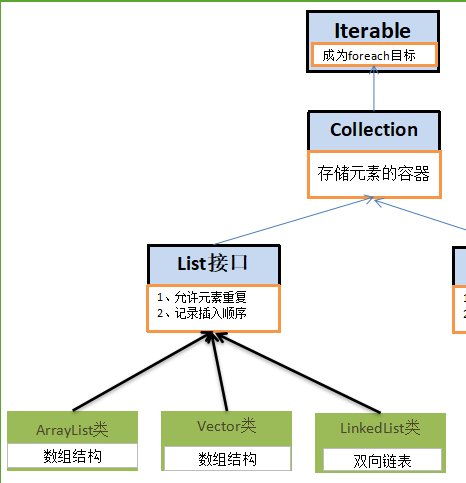
3.List接口
Collection是存储数据的容器。
常用操作方法
增加:
boolean add(Object e) 将指定元素添加到此向量的末尾,等价于addElement方法。
void add(int index, Object element) 在此向量的指定位置插入指定的元素。
boolean addAll(Collection c) :把c集合中的元素添加到当前集合对象中.
删除:
Object remove(int index) :删除指定索引位置的元素,并返回删除之后的元素.
boolean remove(Object o):删除指定的元素.
boolean removeAll(Collection c):从此集合中移除包含在指定 集合c中的所有元素。
boolean retainAll(Collection c):在此集合中仅保留包含在指定 集合c中的元素,求两个集合的交集。
修改:
Object set(int index, Object element) :修改当前集合中指定索引位置的元素.
返回被替换的旧的元素.
查询:
int size() :返回当前集合中存储几个元素.
boolean isEmpty():判断当前集合中元素个数是否为0.
Object get(int index):查询指定索引位置的元素.
Object[] toArray():把集合对象转换为Object数组.
3.1Vector类
集合框架出现之前,有一个容器类就是Vector类,Vector类的底层其实就是一个Object数组 protected Object [] elementData;
Vector类现在已经基本上被ArrayList取代了
3.1.1Vector类的存储原理
- 底层是一个Object类型的数组,所以可以存储任意类型的对象,注意:集合中只能存储对象,不能存储基本类型的数据。但是java5之后支持了自动装箱操作,可以基本类型的值自动装箱为包装类型,但也存储的是对象.
- 集合中存储的对象,都是存储的是对象的引用,并不是对象的本身.如下:
Vector v2 = new Vector();
StringBuilder sb = new StringBuilder("SSSS");
v2.add(sb);//集合类中存储的对象,存储的是对象的引用,并不是存储的值
System.out.println(v2);//SSSS
sb.append(222);
System.out.println(v2);//SSSS222
3.2Stack类
Stack是数据结构的一种,先进先出原则,Stack类继承于Vector类,底层可以用数组存储,也可以用链表来存储,官方建议使用ArrayQueue
Deque 接口及其实现提供了 LIFO 堆栈操作的更完整和更一致的 set,应该优先使用此 set,而非此类。例如:
Deque<Integer> stack = new ArrayDeque<Integer>();
3.3ArrayList类
ArrayList类是Java集合框架出现之后用来取代Vector类的。二者底层原理都是基于数组的算法,一模一样.
区别
-
Vector: 所有的方法都使用了synchronized修饰符. 线程安全但是性能较低. 适用于多线程环境.
-
ArrayList:所有的方法都没有使用synchronized修饰符. 线程不安全但是性能较高.
-
即使以后在多线程环境下,我们也不使用Vector类: ArrayList list = Collections.synchronizedList(new ArrayList(...));
在Java7之前,即使使用new ArrayList创建对象,一个元素都不存储,但是在堆空间依然初始化了长度位10的Object数组,没必要. 从Java7开始优化这个设计,new ArrayList,其实底层创建的使用一个空数组. Object [] elementData = new Object[]{}; 在第一次调用add方法的时候,才会重新去初始化数组.
3.4 LinkedList类
LinkedList类是双向链表,单向链表双向队列和栈 的实现类
优势:无论是链表还是队列,它们都擅长操作头和尾,所以在LinkedList中的大多数方法都是xxFirst()
看API会发现,LinkedList中依然存在get(int index)方法,也就是根据索引来确定存储的值,链表中是没有索引的概念的,之所以有这个方法是因为有了集合框架,让LinkedList作为了List接口的实现,没法发只能来实现这个方法,我们也该少用这个方法
3.5List接口实现类比较
面向接口编程:
接口类型 变量 = new 实现类();List list = new ArrayList();
三者共同的特点(共同遵循的规范):
- 1):允许元素重复.
- 2):记录元素的先后添加顺序.
- Vector类: 底层采用数组结构算法,方法都使用了synchronized修饰,线程安全,但是性能相对于ArrayList较低.
- ArrayList类: 底层采用数组结构算法,方法没有使用synchronized修饰,线程不安全,性能相对于Vector较高.ArrayList现在机会已经取代了Vector,为了保证ArrayList的线程安全,List list = Collections.synchronizedList(new ArrayList(...));
4.Set接口
Set是Collection子接口,模拟了数学上的集的概念。
特点:
- 不允许元素重复
- 不会记录元素的添加顺序
Set判断两个对象是否相等用equals,而不是使用==。也就是说两个对象equals比较返回true,Set集合是不会接受这个两个对象的。
4.1HashSet类
HashSet是Set接口最常用的一个类,底层采用的是哈希表算法
在HashSet中如何判断两个对象相同?
当往集合中添加新的对象,先判断该对象和集合对象中的HashCode值:
- 不等,直接把该对象存储到HashCode 指定的位置
- 相等,在据需判断新的对象和集合中的equals比较
二者缺一不可
每一个存储到hash表中的对象,都得提供hashCode和equals方法,用来判断是否是同一个对象.存储在哈希表中的对象,都应该覆盖equals方法和hashCode方法,并且保证equals相等的时候,hashCode也应该相等.
4.2LinkedHashSet类
顾名思义,底层用的是链表和哈希表算法,链表记录元素的添加顺序,哈希表保证元素不重复。。综合了List接口和Set接口的特点,很强势,但是性能并不高
LinkedHashSet类是HashSet类的子类
4.3TreeSet类
底层采用的是红黑树算法,会对存储的元素默认进行自然排序,从小到大。
- 自然排序
TreeSet调用集合元素的compareTo方法来比较元素的大小关系,然后讲集合元素按照升序排列(从小到大).注意:要求TreeSet集合中元素得实现java.util.Comparable接口.覆盖 public int compareTo(Object o)方法,在该方法中编写比较规则.在该方法中,比较当前对象(this)和参数对象o做比较(严格上说比较的是对象中的数据). this > o: 返回正整数. 1 this < o: 返回负整数. -1 this == o: 返回0. 此时认为两个对象为同一个对象.
- 定制排序
在创建对象的时候,在TreeSet构造器中传递java.lang.Comparator对象.并覆盖public int compare(Object o1, Object o2)再编写比较规则.
package set;
import java.util.*;
/**
* @author 15626
* TreeSet 底层采用的是是红黑树算法,会对存储的 元素进行自然排序(从小到大)
* 要排序当然要保证类型相同,可以使用泛型进行规范
* 排序规则:数字就进行比大小,字符就按照Unicode编码规范来比较(前128位与ASCII编码重复)
*/
public class TreeSetDemo {
public static void main(String []args){
Set<Student> set = new TreeSet<Student>();
set.add(new Student("张三",30));
set.add(new Student("李四",20));
set.add(new Student("王麻子",10));
System.out.println(set);
/**
* 定制排序:在TreeSet构造器中传一个实现Comparator接口类的一个对象,
* 在实现类中覆盖Comparator接口中的public int compare(Ojbect o1,Object o2)方法
* 在方法中可以编写比较规则
*/
//定制排序:根据人名长度进行排序
Set<Student> set2 = new TreeSet<Student>(new NameLengthComparator());
set2.add(new Student("张三李四",30));
set2.add(new Student("李四",20));
set2.add(new Student("王麻子",10));
System.out.println(set2);
}
}
class NameLengthComparator implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
// TODO Auto-generated method stub
if(o1.name.length()>o2.name.length()){
return 1;
}else if(o1.name.length() < o2.name.length()){
return -1;
}else{
return 0; //说明是同一个对象
}
}
}
class Student implements Comparable<Student>{
String name;
int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
/* 自然排序:覆盖Comparable接口中的compareTo方法
* this > o ,返回正整数
* this < o ,返回负整数
* this = o ,返回0 //说明两个对象相同
*
*/
@Override
//自然排序:根据年龄排序
public int compareTo(Student o) {
if(this.age > o.age){
return 1;
}else if(this.age < o.age){
return -1;
}
return 0;
}
}
4.4 Set实现类的比较
共同点:
- 都不允许元素重复
- 都不是线程安全的类
不同:
- HashSet 不保证元素的先后添加顺序.底层采用的是哈希表算法,查询效率极高.
- 判断两个对象是否相等的规则:
- equals比较为true
- hashCode值相同.
- 要求存在在哈希中的对象元素都得覆盖equals和hashCode方法.
- 判断两个对象是否相等的规则:
- LinkedHashSet HashSet的子类,底层也采用的是哈希表算法,但是也使用了链表算法来维持元素的先后添加顺序.
- 判断两个对象是否相等的规则和HashSet相同. 因为需要多使用一个链表俩记录元素的顺序,所以性能相对于HashSet较低.
- TreeSet 不保证元素的先后添加顺序,但是会对集合中的元素做排序操作,底层采用红黑树算法
- 自然排序: 要求在TreeSet集合中的对象必须实现java.lang.Comparable接口,并覆盖compareTo方法.
- 定制排序: 要求在构建TreeSet对象的时候,传入一个比较器对象(必须实现java.lang.Comparator接口). 在比较器中覆盖compare方法,并编写比较规则.
- TreeSet判断元素对象重复的规则: compareTo/compare方法是否返回0.如果返回0,则视为是同一个对象.
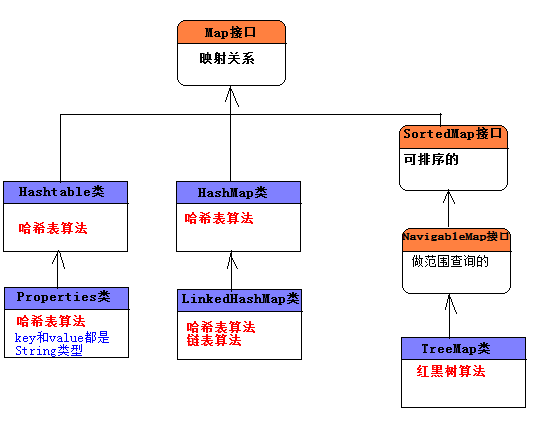
5.Map接口
严格上说,Map并不是集合,而是两个集合之间的映射关系(Map接口并没有继承于Collection接口),然而因为Map可以存储数据(每次存储都应该存储A集合中以一个元素(key),B集合中一个元素(value)),我们还是习惯把Map也称之为集合.
Map接口并没有继承于Collection接口也没有继承于Iterable接口,所以不能直接对Map使用for-each操作.
- 可以把Map中的key看做一个Set集合(不允许重复)
- 可以吧Map中的value看做一个List集合(允许重复)
- 可以把Entry(key-value)键值对看做一个Set集合(不允许重复)
如此以来,可以间接的对Map使用for-each
其实,相同算法的Set底层用的是相同算法的Map. 把Set的集合对象作为Map的key,再使用一个Object常量做为value.
5.1Map的常用方法
void clear()
从此映射中移除所有映射关系(可选操作)。
boolean containsKey(Object key)
如果此映射包含指定键的映射关系,则返回 true。
boolean containsValue(Object value)
如果此映射将一个或多个键映射到指定值,则返回 true。
Set<Map.Entry<K,V>> entrySet()
返回此映射中包含的映射关系的 Set 视图。
boolean equals(Object o)
比较指定的对象与此映射是否相等。
V get(Object key)
返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。
int hashCode()
返回此映射的哈希码值。
boolean isEmpty()
如果此映射未包含键-值映射关系,则返回 true。
Set<K> keySet()
返回此映射中包含的键的 Set 视图。
V put(K key, V value)
将指定的值与此映射中的指定键关联(可选操作)。
void putAll(Map<? extends K,? extends V> m)
从指定映射中将所有映射关系复制到此映射中(可选操作)。
V remove(Object key)
如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。
int size()
返回此映射中的键-值映射关系数。
Collection<V> values()
返回此映射中包含的值的 Collection 视图。
5.2HashMap类
采用哈希表算法, 此时Map中的key不会保证添加的先后顺序,key也不允许重复.
key判断重复的标准是: key1和key2是否equals为true,并且hashCode相等.
5.3TreeMap类
采用红黑树算法,此时Map中的key会按照自然顺序或定制排序进行排序,,key也不允许重复. key判断重复的标准是: compareTo/compare的返回值是否为0.
5.4 LinkedHashMap类
采用链表和哈希表算法,此时Map中的key会保证先后添加的顺序,key不允许重复.
key判断重复的标准和HashMap中的key的标准相同.
5.5 Hashtable类
采用哈希表算法,是HashMap的前身(类似于Vector是ArrayList的前身)
在Java的集合框架之前,表示映射关系就使用Hashtable.
HashMap和TreeMap以及LinkedHashMap都是线程不安全的,但是性能较高。
解决方案: Map m = Collections.synchronizedMap(Map对象);
6.集合工具类
6.1 Arrays类
在Collection接口中有一个方法叫toArray把集合转换为Object数组. 把集合转换为数组: Object[] arr = 集合对象.toArray();
数组也可以转换为集合(List集合): public static
package util;
import java.util.List;
import java.util.ArrayList;
import java.util.Arrays;
/**
* @author 15626
* 集合的工具类 :Arrays,可以把数组转换成集合
*/
public class ArraysDemo {
public static void main(String []args){
//把集合转换成数组
ArrayList<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
list.add("d");
Object [] arr= list.toArray();
for(Object arr1 : arr){
System.out.println(arr1);
}
System.out.println("========================");
//把数组转化成集合
String [] str = new String[]{"A","b","C"};
//返回的是不能改变长度的list对象,因为返回的ArrayList不是java.util.ArrayList包中的对象,而是Arrays类中的内部类对象
List<String> list2 = Arrays.asList(str);
//list2.remove(0);//UnsupportedOperationExceptions
System.out.println(list2);
//基本类型的数据会自动装箱转化为包装类型,这里的1,2,3都自动装箱为Integer类型
List<Integer> list3 = Arrays.asList(1,2,3,4,5);
System.out.println(list3);
//试图把数组直接转化一下,这是直接把数组当做对象,基本类型的数据不能存储到集合中
int [] a = new int[]{1,2,3,4,5};
List<int[]> list4 = Arrays.asList(a);
System.out.println(list4);
}
}
6.2Collections类
HashSet/ArrayList/HashMap都是线程不安全的,在多线程环境下不安全. 在Collections类中有获取线程安全的集合方法:
Set set = Collections.synchronizedSet(new HashSet());
Map map = Collections.synchronizedMap(new HashMap());
List list = Collections.synchronizedList(new ArrayList());
7.泛型
集合框架牵扯到了泛型,这有篇文章对泛型有很详细的解释:https://www.cnblogs.com/coprince/p/8603492.html
8.测试代码
https://github.com/EarthSoar/JavaExamples/tree/master/CollectionsFramework

 浙公网安备 33010602011771号
浙公网安备 33010602011771号