bert 编程入门| bert 瘦身技巧
这个是bert台湾博主的讲解
https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html
这个是代码讲解:
https://blog.csdn.net/cpluss/article/details/88418176
这里是自动追踪tensor的变化:
https://github.com/cool-RR/PySnooper
代码在最后面
前面是代码细节的内容讲解
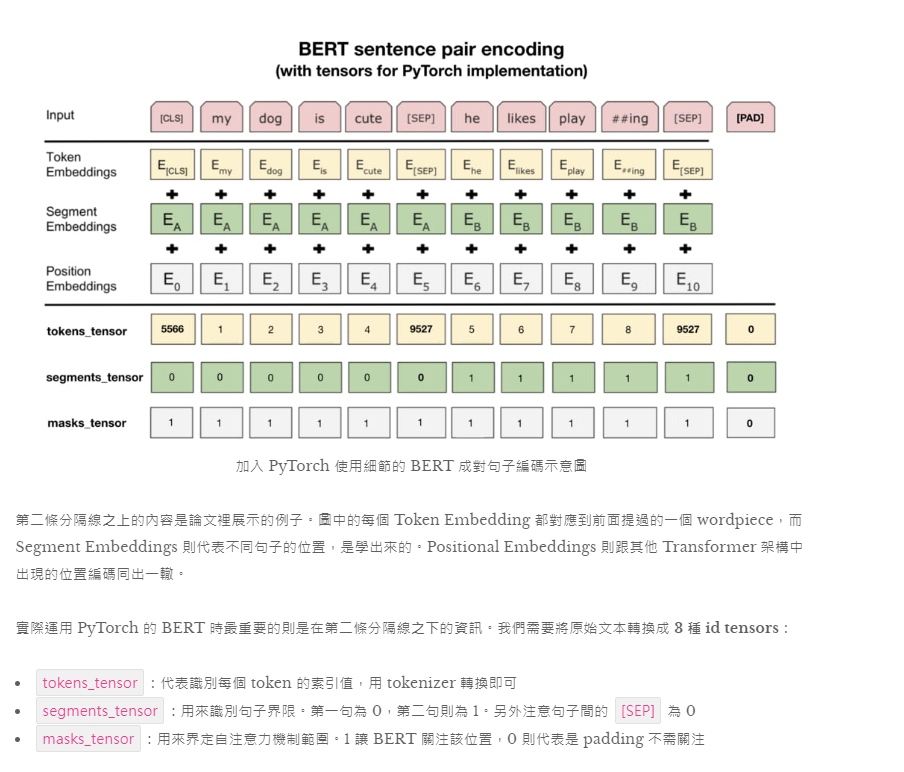
## 前綴的 tokens 即為 wordpieces
以詞彙 fragment 來說,其可以被拆成 frag 與 ##ment 兩個 pieces,而一個 word 也可以獨自形成一個 wordpiece。wordpieces 可以由蒐集大量文本並找出其中常見的 pattern 取得。
除了一般的 wordpieces 以外,BERT 裡頭有 5 個特殊 tokens 各司其職:
[CLS]:在做分類任務時其最後一層的 repr. 會被視為整個輸入序列的 repr.[SEP]:有兩個句子的文本會被串接成一個輸入序列,並在兩句之間插入這個 token 以做區隔[UNK]:沒出現在 BERT 字典裡頭的字會被這個 token 取代[PAD]:zero padding 遮罩,將長度不一的輸入序列補齊方便做 batch 運算[MASK]:未知遮罩,僅在預訓練階段會用到
這樣的 word repr. 就是近年十分盛行的 contextual word representation 概念。跟以往沒有蘊含上下文資訊的 Word2Vec、GloVe 等無語境的詞嵌入向量有很大的差異。用稍微學術一點的說法就是:
Contextual word repr. 讓同 word type 的 word token 在不同語境下有不同的表示方式;而傳統的詞向量無論上下文,都會讓同 type 的 word token 的 repr. 相同。
直覺上 contextual word representation 比較能反映人類語言的真實情況,
fine tune BERT 來解決新的下游任務有 5 個簡單步驟:
為了讓 GPU 平行運算我們需要將 batch 裡的每個輸入序列都補上 zero padding 以保證它們長度一致
BertPooler层详细解释
#由上面的讲解可知,pooler层的输入是transformer最后一层的输出,[batch_size, seq_length, hidden_size]
#取出每一句的第一个单词,做全连接和激活。得到的输出可以用来分类等下游任务(即将每个句子的第一个单词的表示作为整个句子的表示)
为什么用layer-norm
1)layer normalization 有助于得到一个球体空间中符合0均值1方差高斯分布的 embedding, batch normalization不具备这个功能。
2) layer normalization可以对transformer学习过程中由于多词条embedding累加可能带来的“尺度”问题施加约束,相当于对表达每个词一词多义的空间施加了约束,有效降低模型方差。batch normalization也不具备这个功能。
瘦身技巧总结:
博客链接: https://zhuanlan.zhihu.com/p/86900556

加多一个结构减枝:
layerdrop:
https://github.com/pytorch/fairseq/tree/master/examples/layerdrop
下面是知识蒸馏的专业解释:
链接:https://www.zhihu.com/question/50519680/answer/136406661
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
给没用过该方法的朋友简单介绍:
这是一种深层神经网络的训练方法。
一、什么是distillation (或者用Hinton的话说,dark knowledge)(论文Distilling the Knowledge in a Neural Network)
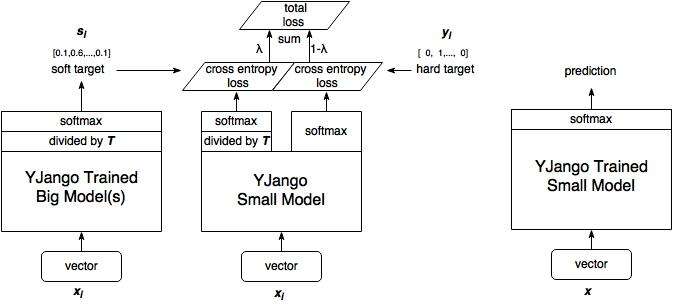 1、训练大模型:先用hard target,也就是正常的label训练大模型。
1、训练大模型:先用hard target,也就是正常的label训练大模型。2、计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output。
3、训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
4、预测时,将训练好的小模型按常规方式(右图)使用。
二、什么是generalized distillation(privileged information和distillation的结合)(论文:Unifying distillation and privileged information)
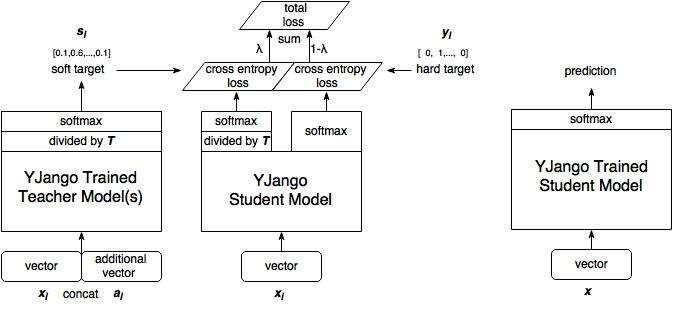
三、为何要软化,为何好用的初步解释
由于我发过基于generalized distillation的application论文(Articulatory and spectrum features integration using generalized distillation framework),这里先给一个我用过的ppt的一页。(ppt其中提到的论文是Recurrent Neural Network Training with Dark Knowledge Transfer)

信息量:
hard target 包含的信息量(信息熵)很低,
soft target包含的信息量大,拥有不同类之间关系的信息(比如同时分类驴和马的时候,尽管某张图片是马,但是soft target就不会像hard target 那样只有马的index处的值为1,其余为0,而是在驴的部分也会有概率。)
软化:
问题是像左图的红色0.001这部分,在cross entropy的loss function中对于权重的更新贡献微乎其微,这样就起不到作用。把soft target软化(整体除以一个数值后再softmax),就可以达到右侧绿色的0.1这个数值。
这张ppt是一般的解释。如果想了解更深刻的话,请看深层神经网络 · 超智能体关于深层为什么比浅层有效的解释,从中找到为什么要one hot vector编码,然而接着往下看。
四、进一步解释
我假设你已经看完了深层神经网络 · 超智能体关于深层为什么比浅层有效的解释,并找到了为什么要one hot vector编码。
那你应该看到了很多关于学习的关键。拿其中两句来说:学习是将变体拆成因素附带关系的过程;变体(variation)越少,拟合难度越低,熵越低。
在神经网络的隐藏层中可以通过加入更多隐藏层节点来拟合变体,降低熵和拟合难度。
然而有两个瓶颈,就是输入层和输出层是由数据限制的。输入层的瓶颈也可以来靠稀疏表示来弥补一些(是神经网络之外的额外一层)。而输出层的瓶颈就可以靠soft target来弥补。
原因在于即便是输出层也是有变体的。如何消除这一层的变体?举个例子,如果要分类10个不同物体的图片,完全可以只输出一个节点,用一维输出来表示。得到1就是第一个物体,得到9就是第9个物体。但是这样做的话,输出层的这一个节点就有10个变体,会使建模时的熵增加。但是若用10个节点来分别表示,那么每个节点就只有一个可能的取值(也就是没有变体),熵就可以降到最低。可是问题又来了,如何确保这10个类就是所有变体?该问题是和caffe 每个样本对应多个label?的问题是类似的,并没有把所有变体都摊开。
如何解决这种分类问题:
五分类问题
样本1: 2,3(样本1属于第二类和第三类)
样本2: 1,3,4(样本2属于第一类,第三类和第四类)
既属于第二类又属于第三类的样本就和既像驴又像马的样本图片一样。
一种解决方式是重新编码,比如把属于2,3类的数据对应一个新的label(该label表示既是2又是3)。
把所有变体全部摊开,比如有n个类,输出层的节点个数会变成2^n-1(-1是排除哪一类都不是的情况)。
soft target也有类似的功效,就是
soft target是加入了关于想要拟合的mapping的prior knowledge,降低了神经网络的搜索空间,从而获得了泛化(generalization)能力。
加入prior knowledge也是设计神经网络的核心。
五、实验现象
soft target的作用在于generalization。同dropout、L2 regularization、pre-train有相同作用。
这其实也是我要在知乎Live深层学习入门误区想要分享内容的一部分。
简单说
dropout是阻碍神经网络学习过多训练集pattern的方法
L2 regularization是强制让神经网络的所有节点均摊变体的方法。
pretrain和soft target的方式比较接近,是加入prior knowledge,降低搜索空间的方法。
1,Recurrent Neural Network Training with Dark Knowledge Transfer中还测试了用pretrain soft target的方式来加入prior knowledge,效果还比distillation的方式好一点点(毕竟distillation会过分限制网络权重的更新走向)
2,我才投的期刊论文有做过两者的比较。当没有pretrain的时候用distillation,效果会提升。但是当已经应用了pretrain后还用distillation,效果基本不变(有稍微稍微的变差)
3,Distilling the Knowledge in a Neural Network我记得好像并没有提到是否有用dropout和L2也来训练small model。我的实验结果是:
如果用了dropout和L2,同样feature vector的soft target来训练的distillation不会给小模型什么提升(往往不如不用。有额外feature vector的soft target的会提升)。
如果不用dropout和L2,而单用distillation,那么就会达到dropout和L2类似的泛化能力,些许不如dropout。
也就是说dropout和L2还有pretrain还有distillation其实对网络都有相同功效。是有提升上限的。Unifying distillation and privileged information论文是没有用dropout和L2,我看过他的实验代码。如果用了dropout和L2,提升不会像图表显示的那么大。
4,你注意Hinton的实验结果所显示提升也是十分有限。压缩网络的前提是神经网络中的节点是由冗余的,而关于压缩神经网络的研究,我建议是从每层中权重W的分析入手。有很多关于这方面的论文。
BERT 蒸馏示例
这里列出几个 BERT 蒸馏例子。
最完美实现上述经典方法对 BERT 蒸馏的是 HuggingFace 前段时间放出的 DistilBERT,将 BERT-base 从 12 层蒸馏到 6 层 BERT 模型。当然除了上述方法,还用了些其他技巧,比如用老师模型参数初始化学生模型,更多细节可看 HuggingFace 的博客和论文,都非常棒。
博客:Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT
论文:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
代码:https://github.com/huggingface/transformers/tree/master/examples/distillation
神经元剪枝:
https://blog.rasa.com/pruning-bert-to-accelerate-inference/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号