运维面经汇总
一
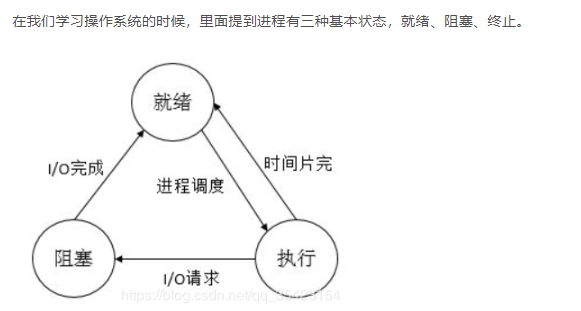
但是在linux中,将状态细分到了六种。
R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。
S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠(interruptible sleep))。
D磁盘休眠状态(Disk sleep):有时候也叫不可中断睡眠状(uninterruptible sleep),在这个状态的进程通常会等待IO的结束。
T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。
X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态
Z僵死状态(Zombies) :进程已经退出了但是资源还没有完全被释放的一种状态。
进程的概念
僵尸进程
这里的有一种特殊的状态值得一提,就是僵死状态
当子进程退出的时候,如果父进程没有读取到子进程的返回值,这时就进入了僵死状态。
这时就处于一个很尴尬的局面,子进程实际上已经退出了,但是父进程认为它还在执行,所以并没有释放它的资源,所以子进程会一直卡在进程表中,等待父进程读取退出状态代码。
TCP拥塞控制
提高网络利用率,降低丢包率,并保证网络资源对每条数据流的公平性,这就是拥塞控制。
拥塞控制包括四部分:慢启动、拥塞避免、快速重传、快速恢复

TCP流量控制
如果发送端发送数据太快,接收端来不及接收,可能会丢失数据。所以流量控制是让发送端不要发送太快,要让接收端来得及接收
流量控制是通过大小可变的滑动窗口实现的。

二
linux启动时我们会看到许多启动信息。
Linux系统的启动过程并不是大家想象中的那么复杂,其过程可以分为5个阶段:
- 内核的引导。【首先是BIOS开机自检,按照BIOS中设置的启动设备(通常是硬盘)来启动。读取/boot】
- 运行 init。【init 程序首先是需要读取配置文件 /etc/inittab。】
- 系统初始化。【调用执行了/etc/rc.d/rc.sysinit】
- 建立终端 。
- 用户登录系统。
我们用crontab -e进入当前用户的工作表编辑,是常见的vim界面。每行是一条命令。
crontab的命令构成为 时间+动作,其时间有分、时、日、月、周五种,操作符有
- * 取值范围内的所有数字
- / 每过多少个数字
- - 从X到Z
- ,散列数字
实例1:每1分钟执行一次myCommand
* * * * * myCommand
实例2:每小时的第3和第15分钟执行
3,15 * * * * myCommand
这个方法的原理就是再执行一次/etc/profile shell脚本

深拷贝,包含对象里面的自对象的拷贝,所以原始对象的改变不会造成深拷贝里任何子元素的改变
copy浅拷贝,没有拷贝子对象,所以原始数据改变,子对象会改变
常用引擎:
InnoDB(重点)
MyISAM
BLACKHOLE(黑洞引擎)
CSV(数据文件可以使用excel打开)
MySQL 整个查询执行过程,总的来说分为 5 个步骤 :
- 客户端向 MySQL 服务器发送一条查询请求
- 服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段
- 服务器进行 SQL解析、预处理、再由优化器生成对应的执行计划
- MySQL 根据执行计划,调用存储引擎的 API来执行查询
- 将结果返回给客户端,同时缓存查询结果
一、Nginx负载均衡算法
1、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务,如果后端某台服务器死机,自动剔除故障系统,使用户访问不受影响。
2、weight(轮询权值)
weight的值越大分配到的访问概率越高,主要用于后端每台服务器性能不均衡的情况下。或者仅仅为在主从的情况下设置不同的权值,达到合理有效的地利用主机资源。
3、ip_hash
每个请求按访问IP的哈希结果分配,使来自同一个IP的访客固定访问一台后端服务器,并且可以有效解决动态网页存在的session共享问题。
4、fair
比 weight、ip_hash更加智能的负载均衡算法,fair算法可以根据页面大小和加载时间长短智能地进行负载均衡,也就是根据后端服务器的响应时间 来分配请求,响应时间短的优先分配。Nginx本身不支持fair,如果需要这种调度算法,则必须安装upstream_fair模块。
5、url_hash
按访问的URL的哈希结果来分配请求,使每个URL定向到一台后端服务器,可以进一步提高后端缓存服务器的效率。Nginx本身不支持url_hash,如果需要这种调度算法,则必须安装Nginx的hash软件包。
正反向解析事两个不同得名称空间,是两颗不同得解析树;
正向:ip---》主机名
反向:主机名---》ip
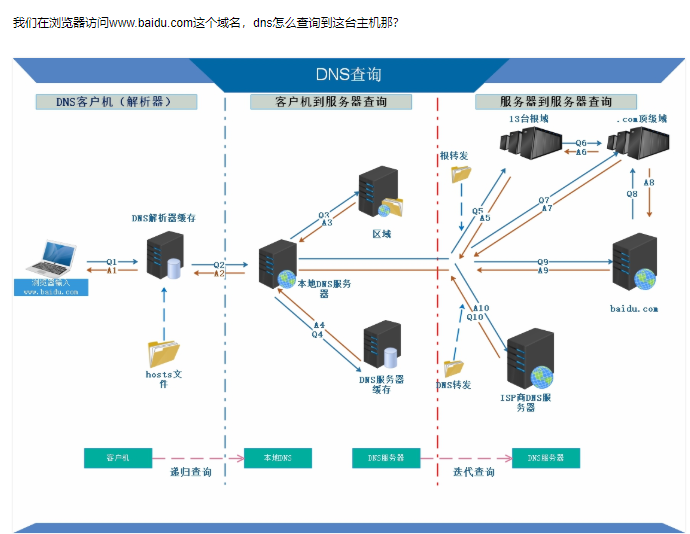
1、在浏览器中输入www.baidu.com域名,操作系统会先检查自己本地的hosts文件是否有这个网址映射关系,如果有,就先调用这个ip地址映射,完成域名解析。
2、如果hosts里没有这个域名的映射,则会查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析。
3、如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/IP参数中设置的首选DNS服务器,在此我们叫它本地DNS服务器,此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析记过给客户端,完成域名解析,此解析具有权威性。
4、如果要查询域名,不由本地DNS服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析,此解析不具有权威性。
5、如果本地DNS服务器本地区域文件与缓存解析都失效,则根据本地DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(baidu.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找baidu.com域服务器,重复上面的动作,进行查询,直至找到www.baidu.com主机。
6、如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把请求转至上上级,以此循环。不管是本地DNS服务器用是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
从上图可以知道,客户端到本地DNS服务器是属于递归查询,而DNS服务器之间的交互查询就是迭代查询
递归查询与迭代查询
递归,只发送一次请求,得到一次准确结果(消耗资源)
迭代,发送多次请求,得到参考结果
三
一面面试官问了好多网络的问题,比如tcp协议,还问我如果不想要一个ip,如何释放,如何重新获取一个ip, 问了linux 的命令和Windows 的dos 命令,之后给我介绍了一下公司的运维结构,然后等二面
二面是系统运维的面试官,又问了tcp 协议,如果服务器100M带宽,客户机10M带宽,服务器向客户机发发数据,为什么速度提不到它该有的带宽,问了redis 的数据类型,python 原类,stp生成树作用,介绍一下它,还有现在企业还需要stp吗?其他的记不太清了
四
1.内存中的堆栈
内存空间在逻辑上分为三部分:代码区、静态数据区和动态数据区,动态数据区又分为栈区和堆区。
代码区:存储方法体的二进制代码。高级调度(作业调度)、中级调度(内存调度)、低级调度(进程调度)控制代码区执行代码的切换。
静态数据区:存储全局变量、静态变量、常量,常量包括final修饰的常量和String常量。系统自动分配和回收。
栈区:存储运行方法的形参、局部变量、返回值。由系统自动分配和回收。
例如 int method(int a){int b;}栈中存储参数a、局部变量b、返回值temp。
堆区:new一个对象的引用或地址存储在栈区,指向该对象存储在堆区中的真实数据。由程序员分配和回收(Java中由JVM虚拟机的垃圾回收机制自动回收)。
例如 Class Student{int num; int age;} main方法中Student stu = new Student();分配堆区空间中存储的该对象的num、age,变量stu存储在栈中,里面的值是对应堆区空间的引用或地址。
2.数据结构中的堆栈
栈:是一种连续存储的数据结构,特点是存储的数据先进后出。
堆:是一棵完全二叉树结构,特点是父节点的值大于(小于)两个子节点的值(分别称为大顶堆和小顶堆)。它常用于管理算法执行过程中的信息,应用场景包括堆排序,优先队列等。
五
建议:
六
项目相关
- 如何防止缓存击穿
- 如何打散热点数据
- xxx有没有设计容错的机制
- xxx有没有使用多线程开发
- 对象存储的实现原理
- 项目中数据库表设计
基础知识
- Docker 原理
- dockerfile 一些配置参数
- docker-compose 一些配置参数
- Linux 下怎么查看进程/CPU/内存的信息
- Linux 下怎么调试 Go 程序
bn面试:
docker - 集群 - 迁移服务器 - django框架
python 开发的集群工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号