02 2025 档案
摘要: Vision Transformer(ViT)通过采用自注意力机制处理图像块,革新了图像识别方法,展现了在大规模数据集上超越传统卷积神经网络的潜力。
阅读全文
Vision Transformer(ViT)通过采用自注意力机制处理图像块,革新了图像识别方法,展现了在大规模数据集上超越传统卷积神经网络的潜力。
阅读全文
Vision Transformer(ViT)通过采用自注意力机制处理图像块,革新了图像识别方法,展现了在大规模数据集上超越传统卷积神经网络的潜力。
阅读全文
摘要: transformer是一种基于自注意力机制的深度神经网络模型,通过并行处理和长距离依赖捕捉,显著提升序列建模效率。其多头注意力设计增强特征提取能力,位置编码保留序列顺序信息。在机器翻译、NLP等领域表现卓越,并广泛扩展至视觉、语音等多模态任务。
阅读全文
transformer是一种基于自注意力机制的深度神经网络模型,通过并行处理和长距离依赖捕捉,显著提升序列建模效率。其多头注意力设计增强特征提取能力,位置编码保留序列顺序信息。在机器翻译、NLP等领域表现卓越,并广泛扩展至视觉、语音等多模态任务。
阅读全文
transformer是一种基于自注意力机制的深度神经网络模型,通过并行处理和长距离依赖捕捉,显著提升序列建模效率。其多头注意力设计增强特征提取能力,位置编码保留序列顺序信息。在机器翻译、NLP等领域表现卓越,并广泛扩展至视觉、语音等多模态任务。
阅读全文
摘要: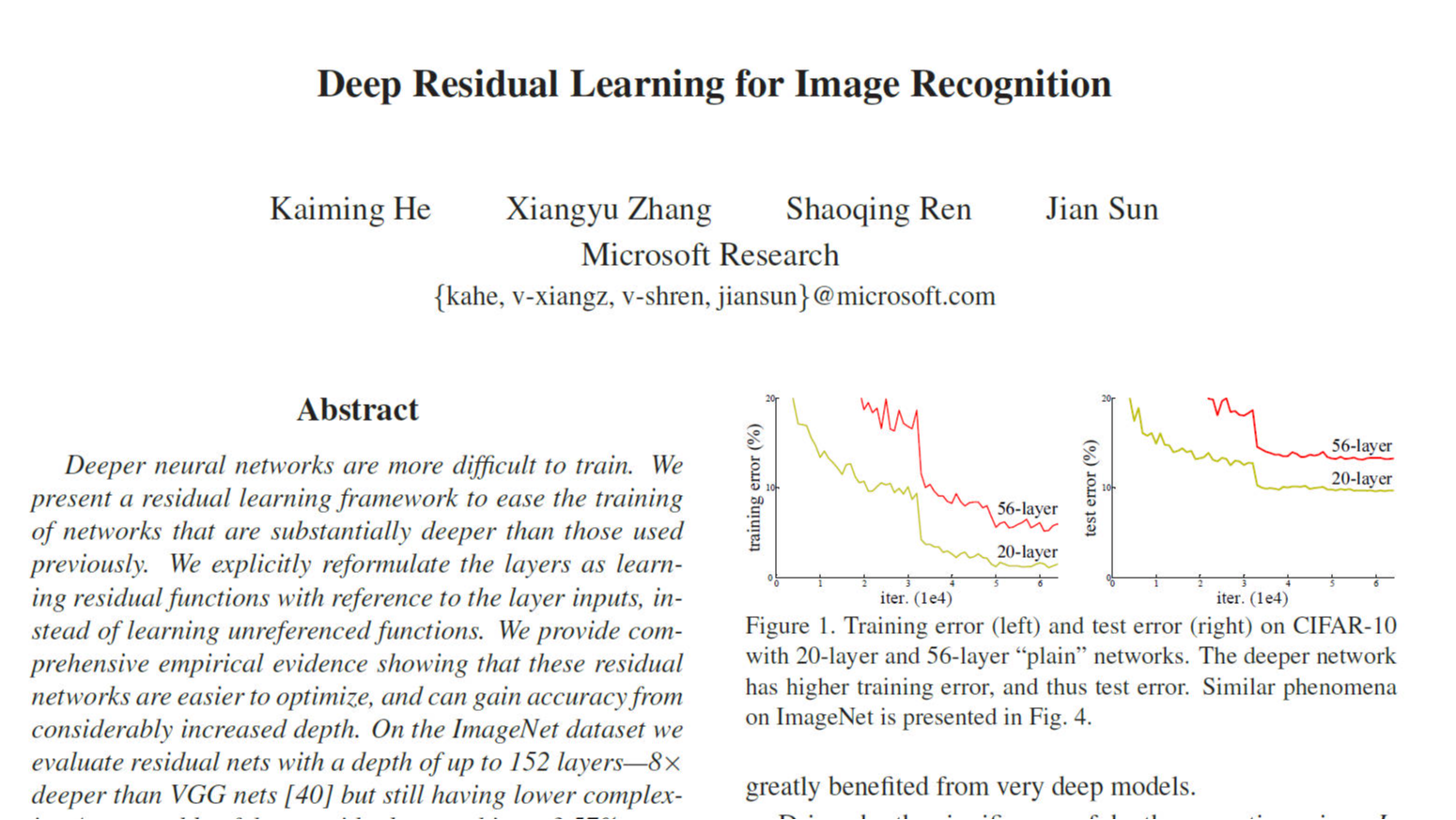 ResNet(残差网络)通过引入残差学习框架,解决了深度神经网络中的退化问题,使得训练数百层的网络成为可能。通过残差块的结构化设计,ResNet在ImageNet和CIFAR-10数据集上取得了显著性能提升,并推动了计算机视觉领域的范式转变。
阅读全文
ResNet(残差网络)通过引入残差学习框架,解决了深度神经网络中的退化问题,使得训练数百层的网络成为可能。通过残差块的结构化设计,ResNet在ImageNet和CIFAR-10数据集上取得了显著性能提升,并推动了计算机视觉领域的范式转变。
阅读全文
ResNet(残差网络)通过引入残差学习框架,解决了深度神经网络中的退化问题,使得训练数百层的网络成为可能。通过残差块的结构化设计,ResNet在ImageNet和CIFAR-10数据集上取得了显著性能提升,并推动了计算机视觉领域的范式转变。
阅读全文

{kind=link}
{kind=link}
{kind=link}
{kind=link}