ViT, Transformer架构出圈到cv
 Vision Transformer(ViT)通过采用自注意力机制处理图像块,革新了图像识别方法,展现了在大规模数据集上超越传统卷积神经网络的潜力。
Vision Transformer(ViT)通过采用自注意力机制处理图像块,革新了图像识别方法,展现了在大规模数据集上超越传统卷积神经网络的潜力。
一、技术背景
视觉识别的挑战与机遇
在Vision Transformer(ViT)提出之前,卷积神经网络(CNNs),如ResNet和VGG,主导了视觉识别领域。然而,随着Transformer在自然语言处理领域的成功,研究者开始探索其在图像识别中的潜力。ViT借鉴了Transformer的核心理念——自注意力机制,以全新的视角重新定义了图像识别任务。
数据集大小的重要性
为了评估ViT在不同规模数据集上的表现,研究团队在三个不同大小的数据集上进行了实验:ImageNet、ImageNet-21k以及JFT-300M。结果显示,较大的数据集对ViT性能的提升至关重要。特别是在JFT-300M上预训练时,大型ViT模型的表现显著优于小型模型,并且超过了基于ResNet的模型。
二、核心创新
自注意力机制的应用
ViT的核心是将图像分割成固定大小的块(patch),然后像文本序列一样处理这些块。每个块通过线性嵌入映射到一个向量空间,再加上位置嵌入后输入到标准Transformer编码器中。这种设计使得模型能够学习到全局依赖关系,而不是局限于局部信息,这是传统CNN所不具备的能力。
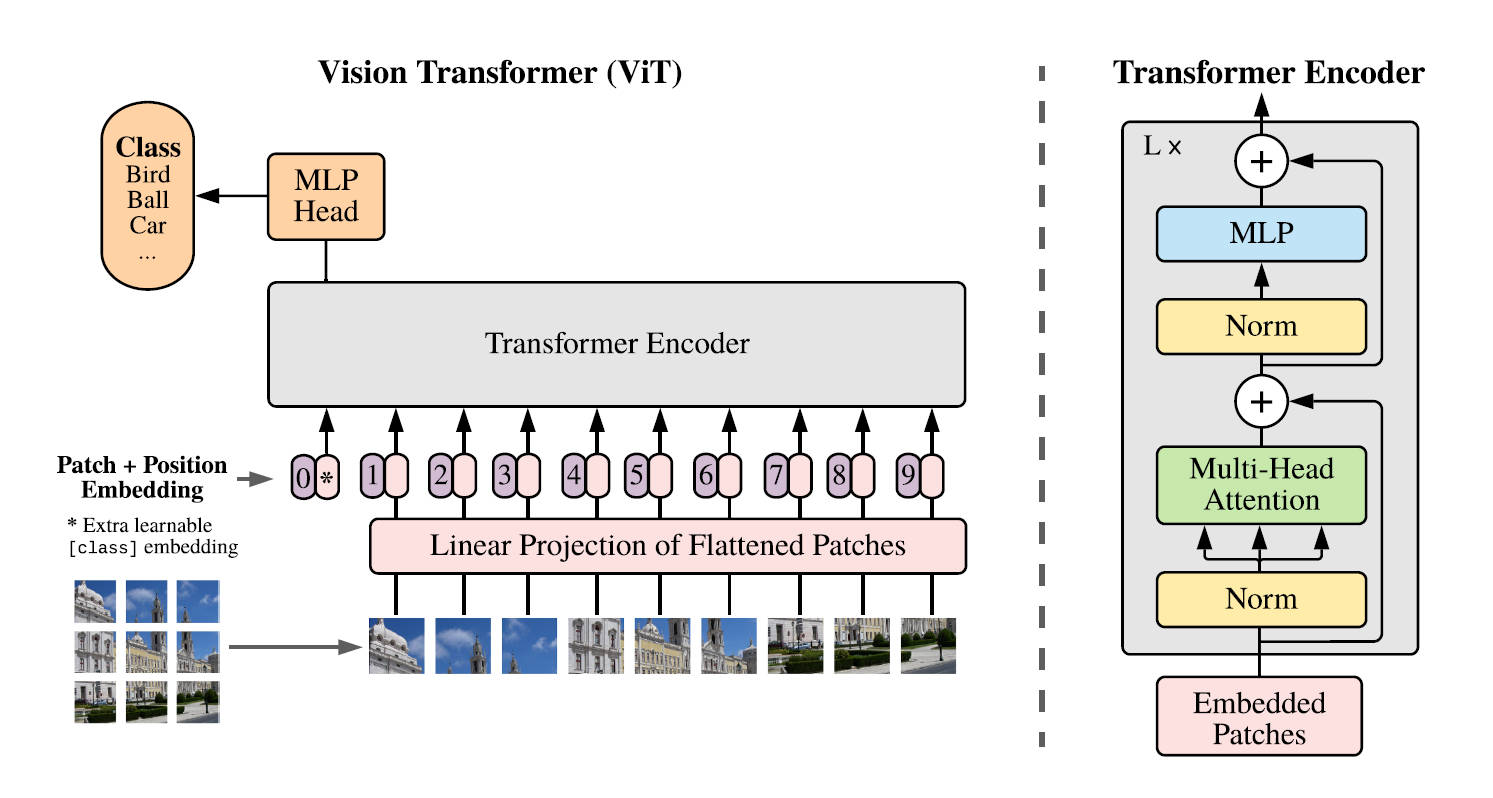
模型配置与超参数选择
ViT有几种不同的变体,包括ViT-B/16, ViT-L/16, 和 ViT-H/14等,分别对应基础(Base)、大(Large)和超大(Huge)版本。它们之间的主要区别在于模型深度和隐藏层维度。此外,对于不同大小的数据集,研究人员调整了学习率、权重衰减等超参数,以优化模型性能。
二、实验设计分析
ImageNet上的表现
根据实验结果,在ImageNet上,ViT-B/16达到了81.072%的Top-1准确率,而ViT-L/16和ViT-H/14则分别达到了79.662%和88.552%。值得注意的是,当使用更大的数据集进行预训练时,这些模型的性能得到了进一步提升,尤其是ViT-H/14在ObjectNet基准测试中实现了61.7%的Top-1准确率。
| 模型 | Top-1准确率 (%) | Top-5准确率 (%) | 参数量 (百万) |
|---|---|---|---|
| ResNet50 | 80.858 | 95.434 | 25.6 |
| ViT-B/16 | 81.072 | 95.318 | 86.6 |
| ViT-L/16 | 79.662 | 94.638 | 304.3 |
| ViT-H/14 | 88.552 | 98.694 | 633.5 |
小样本学习能力
在小样本学习(few-shot learning)设置下,ViT同样表现出色。相比于传统的ResNet模型,ViT不仅能在少量标注数据的情况下快速适应新任务,而且随着训练样本数量的增加,其性能优势更加明显。
四、领域影响
学术界与工业界的反响
ViT的成功激发了大量后续研究工作,包括但不限于改进的ViT变种,如DeiT(Data-efficient image Transformers),以及将其应用于其他视觉任务,例如目标检测和语义分割。同时,ViT也被广泛应用于工业界,成为许多计算机视觉系统的重要组成部分。
对未来研究方向的影响
ViT展示了非卷积结构在图像识别中的巨大潜力,推动了更多关于如何更好地结合自注意力机制与传统卷积操作的研究。此外,ViT还促使研究者重新思考模型架构设计的基本原则,强调了数据规模在训练高效视觉模型中的重要性。
作者注:本文引用的所有图表均来自原论文,具体实现细节可以参考PyTorch官方文档。
本文来自博客园,作者:TfiyuenLau,转载请注明原文链接:https://www.cnblogs.com/tfiyuenlau/p/18727902


{kind=link}
{kind=link}
{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律