CNN和RNN的颠覆者?Transformer模型【论文精读随笔】
 transformer是一种基于自注意力机制的深度神经网络模型,通过并行处理和长距离依赖捕捉,显著提升序列建模效率。其多头注意力设计增强特征提取能力,位置编码保留序列顺序信息。在机器翻译、NLP等领域表现卓越,并广泛扩展至视觉、语音等多模态任务。
transformer是一种基于自注意力机制的深度神经网络模型,通过并行处理和长距离依赖捕捉,显著提升序列建模效率。其多头注意力设计增强特征提取能力,位置编码保留序列顺序信息。在机器翻译、NLP等领域表现卓越,并广泛扩展至视觉、语音等多模态任务。
一、技术背景
RNN的困境与卷积的局限
在Transformer提出之前,序列建模(如机器翻译)主要依赖循环神经网络(RNN)和卷积神经网络(CNN)。尽管RNN通过隐藏状态传递信息,但其顺序计算特性(图1左)导致训练无法并行化,且长距离依赖容易因梯度消失而失效。而CNN虽支持并行计算,但感受野扩展需多层堆叠(如空洞卷积),对远距离关系的捕捉效率低下。
注意力机制的崛起
2014年,Bahdanau等人提出注意力机制,允许模型动态关注输入序列的不同部分。但此机制仍与RNN耦合,未彻底解决并行化问题。Transformer的突破在于完全摒弃循环结构,仅通过自注意力(Self-Attention)和多头注意力(Multi-Head Attention)实现序列建模。
二、核心创新:Transformer架构设计
1. 自注意力机制
自注意力通过查询(Query)、键(Key)、值(Value)三元组计算权重,公式如下:
- 缩放因子\(1/\sqrt{d_k}\):防止点积过大导致Softmax梯度消失(图2右)。
- 并行计算:所有位置注意力权重通过矩阵乘法一步生成。
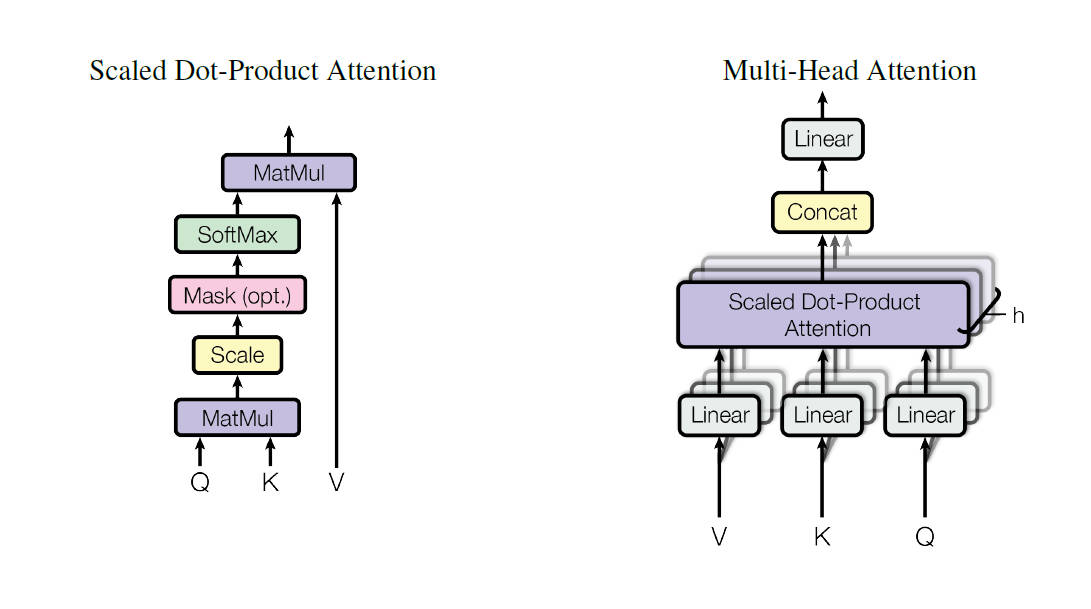
2. 多头注意力(Multi-Head Attention)
多头机制将输入投影到\(h\)个子空间(默认\(h=8\)),独立计算注意力后拼接结果:
每个头可学习不同语义模式(如语法结构、指代关系),如图5所示。
3. 位置编码(Positional Encoding)
由于Transformer无时序感知,需显式注入位置信息。论文采用正弦函数编码:
此设计使模型能通过线性变换捕捉相对位置关系。
4. 编码器-解码器架构
- 编码器:6层堆叠,每层含多头自注意力和前馈网络,残差连接+层归一化。
- 解码器:额外引入掩码多头注意力(防止未来信息泄露),结构如图1。
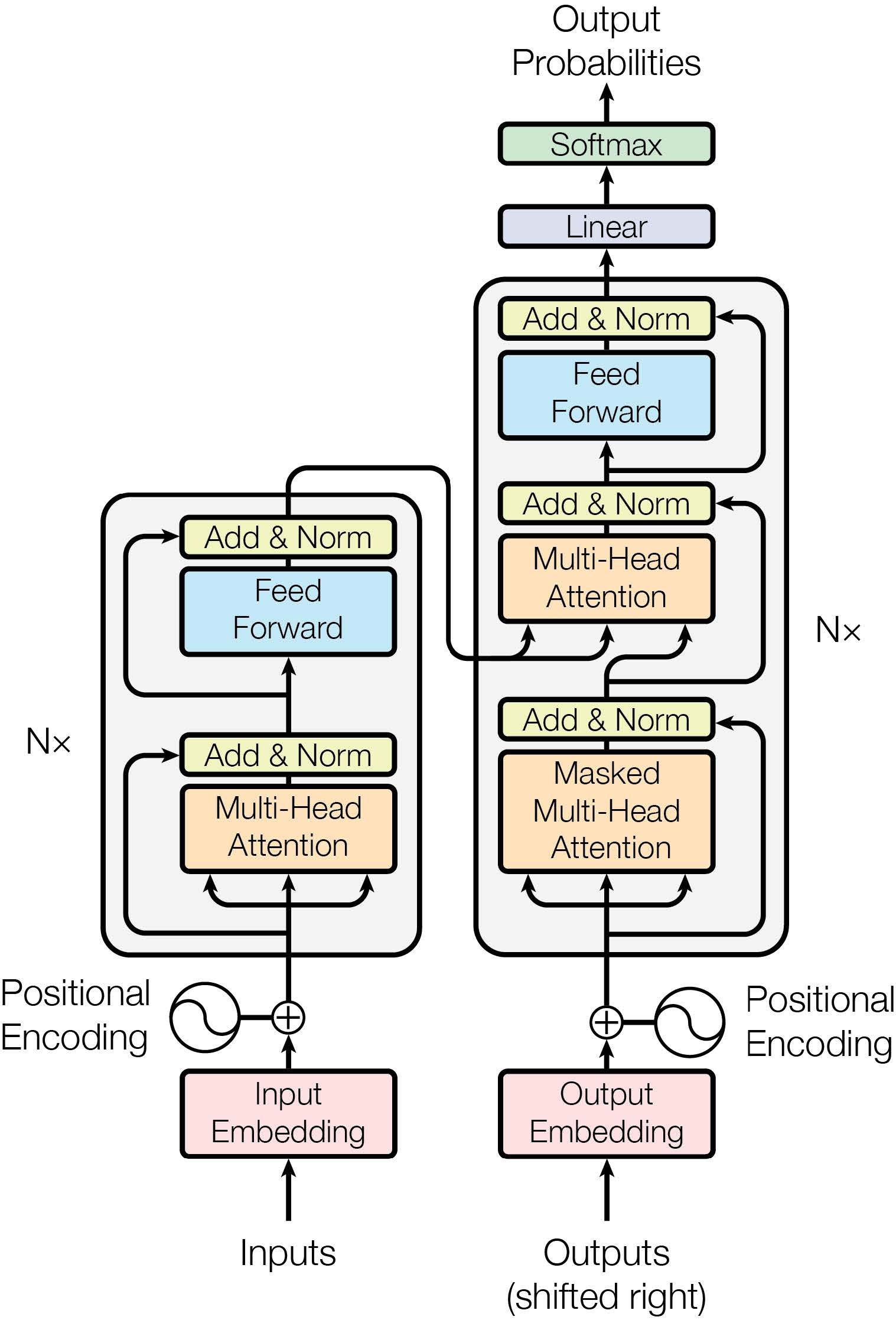
三、实验分析
1. 机器翻译任务
在WMT 2014英德/英法翻译任务中,Transformer大幅超越RNN和CNN模型:
| 模型 | 英德BLEU | 英法BLEU | 训练耗时(GPU Days) |
|---|---|---|---|
| ConvS2S (2017) | 25.16 | 40.46 | 9.6 |
| Transformer (Base) | 27.3 | 38.1 | 0.5 |
| Transformer (Big) | 28.4 | 41.8 | 3.5 |
- 训练效率:Base模型仅需8 GPU训练12小时,比LSTM快10倍。
- 模型容量:Big模型参数量达213M,但通过并行计算仍保持高效。
2. 消融实验(Ablation Study)
通过对比实验验证关键设计(表3):
- 多头数量:8头效果最优,过多或过少均降低性能;
- 位置编码:正弦编码与可学习编码效果相当,但前者支持外推;
- 模型深度:6层编码器-解码器平衡性能与计算成本。
3. 泛化能力:句法分析
在WSJ句法分析任务中,4层Transformer达到91.3 F1值,接近RNN语法分析器(93.3),证明其跨任务通用性。
四、领域影响
1. NLP领域
- 预训练范式:BERT、GPT系列基于Transformer架构,开启大模型时代;
- 长文本处理:后续工作如Longformer、BigBird改进注意力稀疏性;
- 多语言支持:mBERT、XLM-R实现跨语言迁移学习。
2. 跨模态扩展
- 视觉Transformer(ViT):将图像分块为序列输入,媲美CNN;
- 语音处理:Conformer结合CNN与自注意力,提升语音识别精度;
- 多模态融合:CLIP、DALL·E通过Transformer对齐图文语义。
作者注:本文代码实现可参考Hugging Face Transformers库,可视化工具推荐Tensor2Tensor。对位置编码的分析,推荐阅读《Self-Attention with Relative Position Representations》。
本文来自博客园,作者:TfiyuenLau,转载请注明原文链接:https://www.cnblogs.com/tfiyuenlau/p/18723181

 浙公网安备 33010602011771号
浙公网安备 33010602011771号