基于WSL搭建大数据离线数仓伪分布式开发环境
 本文产生于MediMind项目大数据离线数仓的构建需求,用以记录在单机WSL下部署一个由Hadoop、Hive、Spark组成的离线数据仓库开发环境。
本文产生于MediMind项目大数据离线数仓的构建需求,用以记录在单机WSL下部署一个由Hadoop、Hive、Spark组成的离线数据仓库开发环境。
搭建WSL离线数仓伪分布式开发环境
本文产生于MediMind项目大数据离线数仓的构建需求,用以记录在单机WSL下部署一个由Hadoop、Hive、Spark组成的离线数据仓库开发环境。
一、部署前言
Ⅰ、数仓概述
数据仓库(Data Warehouse)是为企业提供数据支持,以协助企业制定决策、改进业务流程和提高产品质量等方面的工具。
数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。
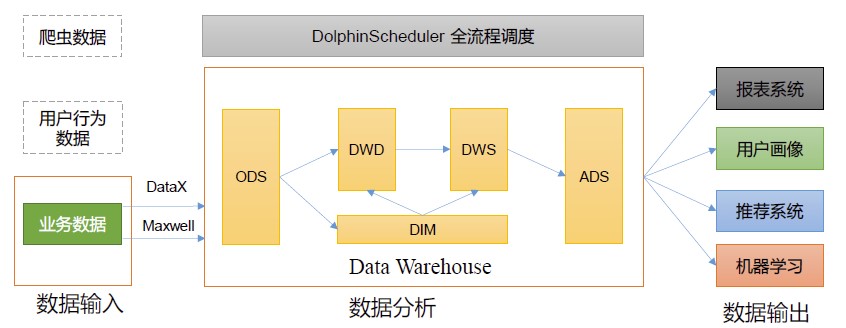
它可以接收多种类型的输入数据,如业务数据、日志数据和爬虫数据等。在本项目中,主要对产生的业务数据(诊断记录、病历等)进行统计和分析。
Ⅱ、技术选型
技术选型主要考虑因素:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算。
下列技术框架为当前大数据领域主流的各类技术,其中粗体表示本项目采用的技术:
- 数据采集传输:Flume,DataX,RabbitMQ,Canal,Kafka,Maxwell,Flink-CDC,Sqoop,Logstash
- 数据存储:MySQL,HDFS,HBase,Redis,MongoDB
- 数据计算:Hive,Spark,Tez,Flink,Storm
- 数据可视化:Echarts,Superset,QuickBI,DataV
- 任务调度:Airflow,DolphinScheduler,Azkaban,Oozie
- 数据查询:Presto,Kylin,Impala,Druid,ClickHouse,Doris
- 集群监控:Zabbix,Prometheus
- 元数据管理:Atlas
- 权限管理:Ranger,Sentry
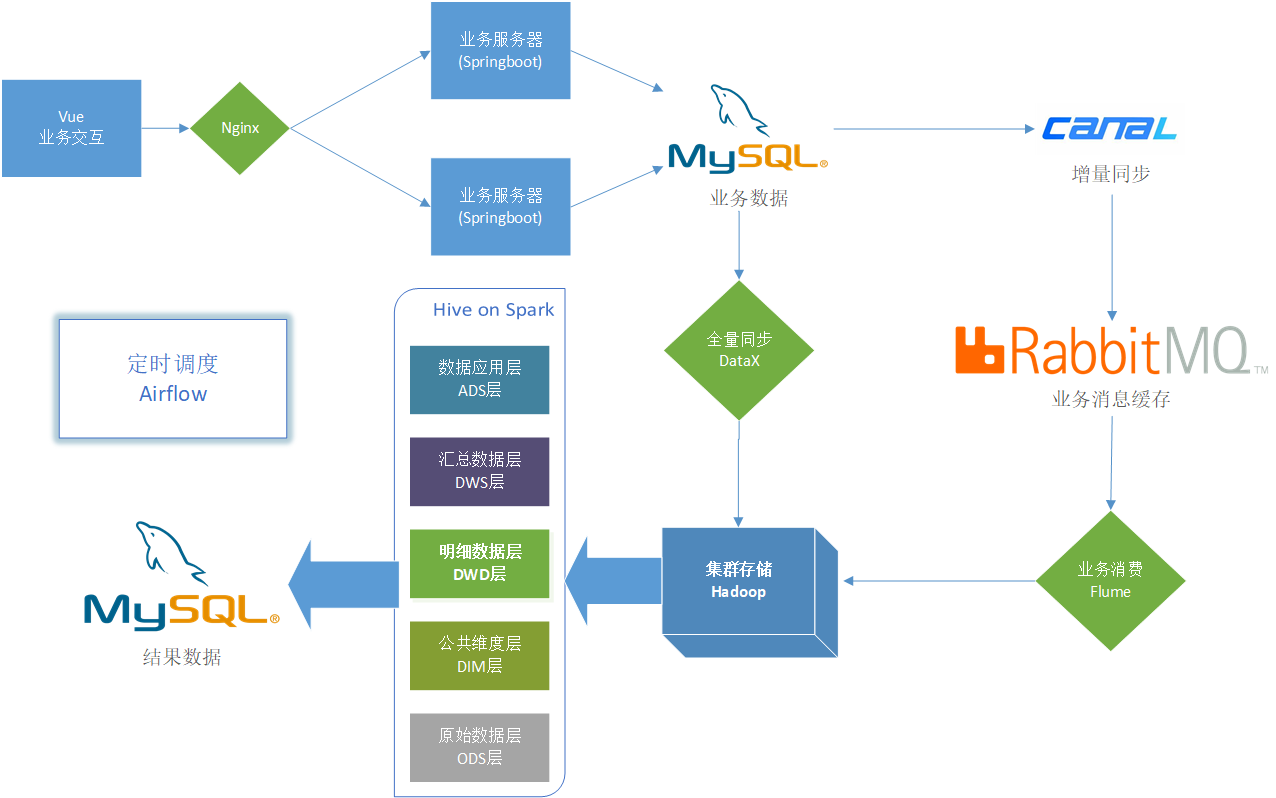
Ⅲ、版本选型
Hadoop、Hive、Spark有各自的依赖版本,在选择框架版本时需得注意,防止不兼容问题。
-
Hive和Hadoop的兼容性请在Hive下载页查找:Apache Hive Downloads
-
Hive和Spark官方的兼容版本为:
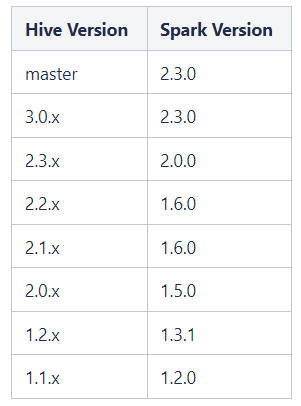
由于Spark3.x不再支持Hive,故需要编译Hive仓库源码使得Hive3.x兼容Spark3.x,这将在下文提及。
下表为技术组件的版本选型:
| 组件 | 版本 |
|---|---|
| JDK | 1.8 |
| Hadoop | 3.3.4 |
| Hive | 3.1.2(编译源码) |
| Spark | 3.3.1 |
| RabbitMQ | 3.12-management |
| Canal | 1.1.7 |
| Flume | 1.11.1 |
| DataX | v202308 |
| Airflow | 2.7.0 |
二、开发环境搭建
下文记录了从DataX数据同步到Airflow调度器的环境搭建。
请在搭建大数据平台之前配置JDK等必要环境。你可以选择在安装前卸载当前的JDK:
sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps // 卸载当前主机中的JDK
sudo apt update
sudo apt install openjdk-8-jdk
随后在/etc/profile中配置JDK1.8环境变量:
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export JAVA_HOME
export PATH
在/etc/profile中配置JDK1.8环境变量后,在命令行中输入source /etc/profile刷新配置并验证安装。
source /etc/profile
java -version
Ⅰ、Hadoop
数仓平台依赖于Hadoop框架提供HDFS,安装可参考:Hadoop安装搭建伪分布式教程(全面)吐血整理。
在下载需要的Hadoop版本后移动到合适的位置tar -zxvf filename解压。
①将已重命名的该文件夹的拥有者,指定给访问hdfs的用户(本文为root),防止hadoop操作时因权限不足而报错:
sudo chown -R root ./hadoop-3.x
在/etc/profile环境变量中配置操作hadoop的用户
# Hadoop
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
②在hadoop文件夹中的/ect/hadoop/hadoop-env.sh文件中配置Java环境:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
刷新配置文件
source hadoop-env.sh
③重要的配置文件进行修改,注意不是根目录的文件而是/ect/hadoop/下的配置文件:
core-site.xml
<configuration>
<property>
<!-- 配置HDFS -->
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<!-- 配置tmp路径 -->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanger.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
④进入/bin,输入命令格式化后启动hadoop:
hdfs namenode -format
start-all.sh
使用jsp命令检查运行着的java进程。
Ⅱ、Canal
本项目选择使用Canal——阿里巴巴 MySQL binlog 增量订阅&消费组件作为增量业务数据的采集工具,其通过监控mysql的binlog日志将操作的事务发送到指定消息队列——RabbitMQ。
RabbitMQ的安装详见:WSL安装Docker并部署后端开发环境

①首先我们需要修改MySql的配置文件my.cnf,打开binlog开关:
[mysqld]
server_id=1
log-bin=mysql-bin
binlog-format=ROW
binlog_do_db=db_name
重启mysql服务systemctl restart mysqld,在数据目录下查看是否生成了binlog文件。
②输入mysql -uroot -p进入mysql,在MySql中创建一个新用户并给予部分权限:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal' ;
再次重启mysql。
③在 GitHub 下载好对应版本的canal.deployer-1.1.7.tar.gz后在合适的路径解压:
tar -zxvf canal.deployer-1.1.7.tar.gz
④进入canal安装目录,在/conf/canal.properties进行总体配置:
...
# tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ
canal.serverMode = rabbitMQ
...
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host = 127.0.0.1
rabbitmq.virtual.host = /
rabbitmq.exchange = exchange.canal # canal将对应表的topic消息发送至交换机
rabbitmq.username = admin
rabbitmq.password = 123456
rabbitmq.deliveryMode = topic
⑤在/conf/example/instance.properties中配置实例:
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=2 # 不和上文的mysql的server_id重复
# position info
canal.instance.master.address=localhost:3306
canal.instance.master.journal.name=mysql-bin.000001
...
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
...
# 正则匹配canal作用的表
canal.instance.filter.regex=medi_mind\\.(patient|doctor|department|diagnosis)
# mq config
canal.mq.topic=example
# RabbitMq topic主题订阅匹配:topic:db_name\\.table_name,...
canal.mq.dynamicTopic=patient:medi_mind\\.patient,doctor:medi_mind\\.doctor,department:medi_mind\\.department,diagnosis:medi_mind\\.diagnosis
...
⑥使用进入bin目录,输入./startup.sh启动canal。
安装出现问题可参考:canal安装最详细教程
Ⅲ、Flume
Flume作为RabbitMQ的消息消费者将队列的消息同步到HDFS中,下载Flume后解压。
Flume没有提供支持消费RabbitMQ消息的功能,但在github中有作者开源了其开发的flume对接rabbitmq插件flume-ng-rabbitmq——Flume plugin for RabbitMQ
①拉取flume-ng-rabbitmq插件源码后使用maven打包为jar:
maven package
将flume-rabbitmq-channel-1.0-SNAPSHOT.jar放置于flume/lib目录下。
②在flume/conf目录创建flume-env.sh配置Java环境:export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64。
③在flume/job目录创建rabbit-flume-hdfs.properties配置文件,输入配置:
agent1.sources = source1
agent1.channels = channel1
agent1.sinks = sink1
# sources:RabbitMQ
agent1.sources.source1.type = org.apache.flume.source.rabbitmq.RabbitMQSource # flume-ng-rabbitmq插件
agent1.sources.source1.hostname = localhost
## agent1.sources.source1.queuename = log_jammin
agent1.sources.source1.exchangename = exchange.canal # topic绑定的交换机
agent1.sources.source1.topics = patient,doctor,department,diagnosis # flume将创建对应的topic队列来消费交换机收到的topic消息
agent1.sources.source1.username = admin
agent1.sources.source1.password = 123456
agent1.sources.source1.port = 5672
agent1.sources.source1.virtualhost = /
## 配置拦截器,在下文提及编写与打包
agent1.sources.source1.interceptors = interceptor1
agent1.sources.source1.interceptors.interceptor1.type = edu.hbmu.medimind.flume.interceptors.FlumeInterceptor$Builder
# Channels
agent1.channels.channel1.type = file
agent1.channels.channel1.checkpointDir = /home/flume/checkpoint/medi_mind
agent1.channels.channel1.dataDirs = /home/flume/data/medi_mind
agent1.channels.channel1.maxFileSize = 2146435071
agent1.channels.channel1.capacity = 1000000
agent1.channels.channel1.keep-alive = 6
# Sinks
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /origin_data/medi_mind/%{table}_inc/%Y-%m-%d
agent1.sinks.sink1.hdfs.filePrefix = db
agent1.sinks.sink1.hdfs.round = false
agent1.sinks.sink1.hdfs.rollInterval = 10
agent1.sinks.sink1.hdfs.rollSize = 134217728
agent1.sinks.sink1.hdfs.rollCount = 0
agent1.sinks.sink1.hdfs.fileType = CompressedStream
agent1.sinks.sink1.hdfs.codeC = gzip
# 拼装
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel= channel1
④编写Java拦截器处理来自RabbitMQ的Canal数据:
1.创建mavne项目flume-interceptor,写入依赖;
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.10.1</version>
<scope>provided</scope>
</dependency>
<!-- jackson2依赖 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.12.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
- 编写拦截器业务逻辑;
package edu.hbmu.medimind.flume.interceptors;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
public class FlumeInterceptor implements Interceptor {
public void initialize() {
}
// 处理单个事件
public Event intercept(Event event) {
ObjectMapper objectMapper = new ObjectMapper();
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
try {
JsonNode jsonNode = objectMapper.readTree(log);
long ts = jsonNode.get("ts").asLong();
String tableName = jsonNode.get("table").asText();
headers.put("timestamp", String.valueOf(ts));
headers.put("table", tableName);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
return event;
}
// 处理一组事件
public List<Event> intercept(List<Event> list) {
for (Event event : list) {
intercept(event);
}
return list;
}
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new FlumeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
- maven打包,将jar包放置于
flueme/lib/目录下。
⑤后台启动Flume:
nohup /home/flume/flume-1.11.0/bin/flume-ng agent -n agent1 -c /home/flume/flume-1.11.0/conf/ -f /home/flume/flume-1.11.0/job/rabbit-flume-hdfs.properties -Dflume.root.logger=INFO,console >> /home/flume/flume.log 2>&1 &
Ⅳ、DataX
本项目采用DataX进行MySql至HDFS的全量数据同步,下载后解压,在DataX GitHub官方文档中可查看各类reader和writer的用法。
①解压后你可以运行自检脚本测试是否成功安装:
python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
②MySql to HDFS 脚本示例:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": ["*"],
"splitPk": "department_id",
"connection": [
{
"table": [
"department"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/medi_mind?useSSL=false"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://localhost:9000",
"fileType": "text",
"path": "/origin_data/medi_mind/department_full/${date}",
"fileName": "tbl_department",
"column": [
{
"name": "department_id",
"type": "BIGINT"
},
{
"name": "department_name",
"type": "STRING"
},
{
"name": "department_director",
"type": "BIGINT"
},
{
"name": "department_address",
"type": "STRING"
},
{
"name": "department_phonenumber",
"type": "STRING"
},
{
"name": "is_effective",
"type": "TINYINT"
}
],
"compress": "gzip",
"writeMode": "truncate",
"fieldDelimiter": "\t"
}
}
}
]
}
}
Ⅴ、Hive
官方编译hive3.x的二进制版本不支持spark3,因而需要我们手动编译;在GitHub中有一个修改源码后的hive3.1.2 on sperk3.0的hive仓库。
①拉取仓库源码并编译为支持spark3.0.0的hive3.1.2
git clone https://github.com/forsre/hive3.1.2.git
cd hive3.1.2-master
maven package
将编译后的hive3.1.2~\hive3.1.2-master\packaging\target\apache-hive-3.1.2-bin\apache-hive-3.1.2-bin复制到合适的路径。
②在/etc/profile添加环境变量并刷新:
# Hive
export HIVE_HOME=/home/hive/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
source /ect/profile
③删除(修改后缀)lib目录中的log4j-slf4j-impl-2.17.1.jar解决日志jar包冲突
mv log4j-slf4j-impl-2.17.1.jar log4j-slf4j-impl-2.17.1.jar.bak
⑤Hive元数据需要连接MySql数据库,将MySQL的JDBC驱动拷贝到Hive的lib目录下。
⑥在$HIVE_HOME/conf目录下新建hive-site.xml配置文件,如下编辑:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true</value>
<description>mysql连接地址</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>mysql驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>mysql用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>mysql密码</description>
</property>
<property>
<name>system:java.io.tmpdir</name>
<value>/user/hive/tmp</value>
<description>在hdfs创建的地址</description>
</property>
<property>
<name>hive.auto.convert.join</name>
<value>false</value>
<description>Enables the optimization about converting common join into mapjoin</description>
</property>
</configuration>
⑦初始化MYSQL元数据库并修改部分字段字符集:
mysql -uroot -p
mysql> create database metastore;
mysql> schematool -initSchema -dbType mysql -verbose
mysql> use metastore;
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
⑧启动Hive并查看数据库:
hive
show databases;
Ⅵ、Spark
Hive引擎包括:默认MR、Tez、Spark。本项目采用Spark作为Hive的执行引擎,即Hive on Spark。
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
由于官网下载的Hive3.1.2和Spark3.3.1默认是不兼容的。因为Hive3.1.3支持的Spark版本是2.3.0,所以我们在上文重新编译了Hive3.1.2版本以支持Spark3。
①在Spark官网下载对应的spark-3.x.x-bin-without-hadoop.tgz版本压缩包并解压。
②在bin目录下新建spark-env.sh文件,添加配置以下配置并保存:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
③在/etc/profile中添加SPARK_HOME环境变量并使其生效:
# Spark
export SPARK_HOME=/home/spark/spark-3.3.1
export PATH=$PATH:$SPARK_HOME/bin
source /ect/profile
④在Hive的conf目录下中创建一个spark配置文件spark-defaults.conf,编辑以下内容:
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://localhost:9000/spark-log
spark.executor.memory 1g
spark.driver.memory 1g
⑤向HDFS上传spark纯净版——即spark-3.x.x-bin-without-bin,文件夹中jars目录下的jar包:
hadoop fs -mkdir /spark-jars
hadoop fs -put /home/spark/jars/* /spark-jars
⑥编辑hive的conf目录下的hive-site.xml配置文件,添加spark依赖配置:
<!--Spark依赖位置(注意:端口号9000必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://localhost:9000/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
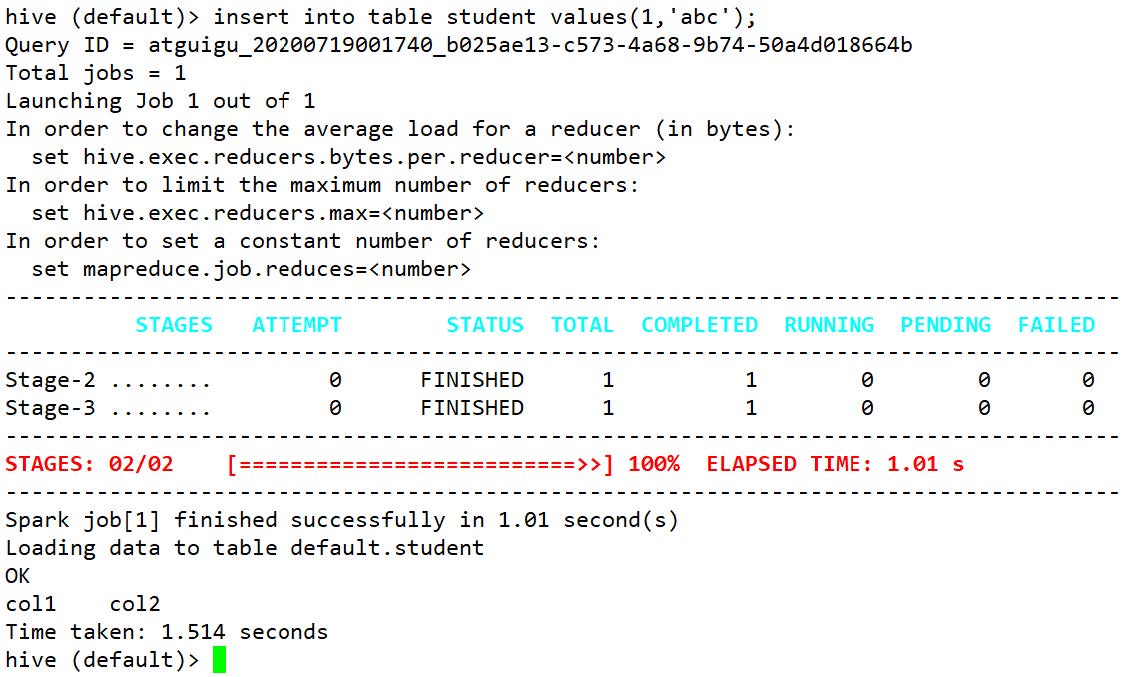
⑦启动hive,执行HQL语句后查看执行引擎是否为spark:
hive
hive (default)> create table student(id int, name string);
hive (default)> insert into table student values(1,'abc');
等待一段时间后,出现下列结果即为配置成功。
⑧在学习环境中可能出现Yarn ApplicationMaster资源不够用的现象,需要我们配置放开占用的调度限制:
容量调度器对每个资源队列中同时运行的Application Master占用的资源进行了限制,该限制通过yarn.scheduler.capacity.maximum-am-resource-percent参数实现,其默认值是0.1,表示每个资源队列上Application Master最多可使用的资源为该队列总资源的10%,目的是防止大部分资源都被Application Master占用,而导致Map/Reduce Task无法执行。
生产环境该参数可使用默认值。但学习环境,集群资源总数很少,如果只分配10%的资源给Application Master,则可能出现,同一时刻只能运行一个Job的情况,因为一个Application Master使用的资源就可能已经达到10%的上限了。故此处可将该值适当调大。
修改Hadoop的hadoop/etc/hadoop/capacity-scheduler.xml文件,修改以下数值将ApplicationMaster资源调度限制改为80%:
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
</property
重启Yarn服务
stop-yarn.sh
start-yarn.sh
延伸阅读
本文来自博客园,作者:TfiyuenLau,转载请注明原文链接:https://www.cnblogs.com/tfiyuenlau/articles/17657133.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号