基于TensorFlow2的SSD算法实现原神目标检测
 使用tensorflow2+ssd300训练原神目标检测模型,数据集采用在Kaggle开源的GenshinHeadDataset与自己获取并标注的小数据集(仅千余张)。摆烂太多天了...新年的第一篇博客就从原神开始吧(笑)。
使用tensorflow2+ssd300训练原神目标检测模型,数据集采用在Kaggle开源的GenshinHeadDataset与自己获取并标注的小数据集(仅千余张)。摆烂太多天了...新年的第一篇博客就从原神开始吧(笑)。
基于TensorFlow2的SSD算法实现原神目标检测
刚刚入坑原神顺便就想玩玩最近学的cv目标检测。算法方面可以直接使用开源的 SSD300 网络模型基于vgg_model预训练模型进行训练。数据集方面 Kaggle 上有人整理了 Genshin Head Dataset,可堪一用;但找遍中英全网似乎也没人做出原神的怪物数据集,我得自己通过录制截屏等方式制作训练集,这无疑既费时间又费精力;最终也只是收集了部分 Monsters 的图像数据。
原神VOC数据集与训练权值文件:百度网盘资源分享——提取码:1024
一、SSD算法简介
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法,截至目前是主要的检测框架之一,相比Faster RCNN有明显的速度优势,相比YOLO又有明显的mAP优势(不过已经被CVPR 2017的YOLO9000超越)。——来源网络
SSD 是一种非常优秀的端到端目标检测方法,也就是说目标检测和分类是同时完成的,其主要思路是利用 CNN 提取特征后,均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,物体分类与预测框的回归同时进行,整个过程只需要一步,所以其优势是速度快。
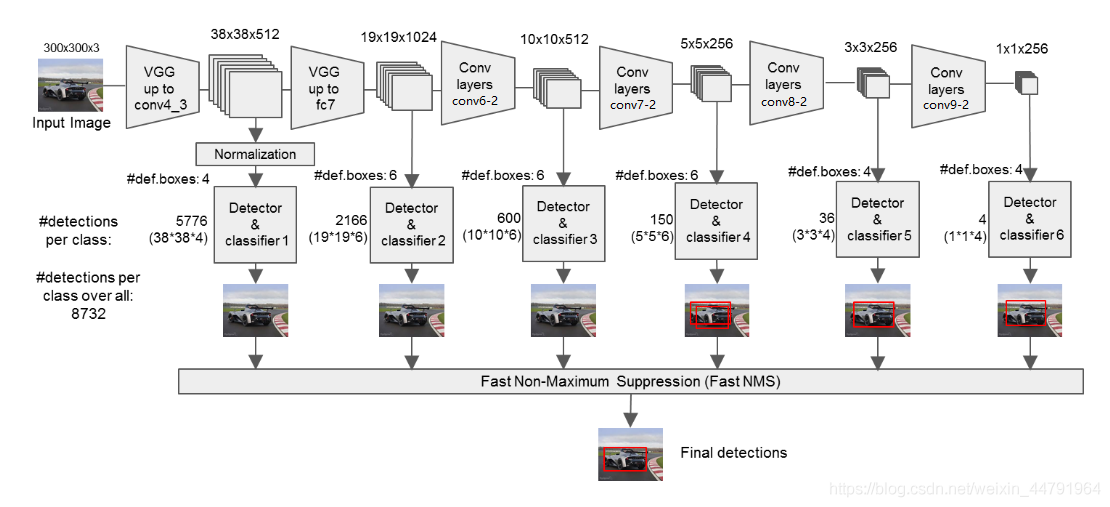
SSD 核心设计理念总结为以下三点:
- 采用多尺度特征图用于检测:选取了6个不同的 feature map 进行检测
- 采用卷积进行检测:Yolo v1 最后采用全连接层预测bbox的坐标及其对应分类,SSD直接采用卷积对不同的特征图来进行提取检测结果
- 设置先验框 anchor: SSD 借鉴了Faster R-CNN中 anchor 的理念,不同的 feature map 上分别生成4~6个 proposal
具体原理请参考:睿智的目标检测37——TF2搭建SSD目标检测平台(tensorflow2)
二、VOC训练集处理
在完成对数据集的收集与整理后,我们通过VOC格式制作目标检测的数据集;训练前将标签文件放在 VOCdevkit 文件夹下的 VOC2023 文件夹下的 Annotation 中;并将图片文件放在 VOCdevkit 文件夹下的 VOC2023 文件夹下的 JPEGImages 中。
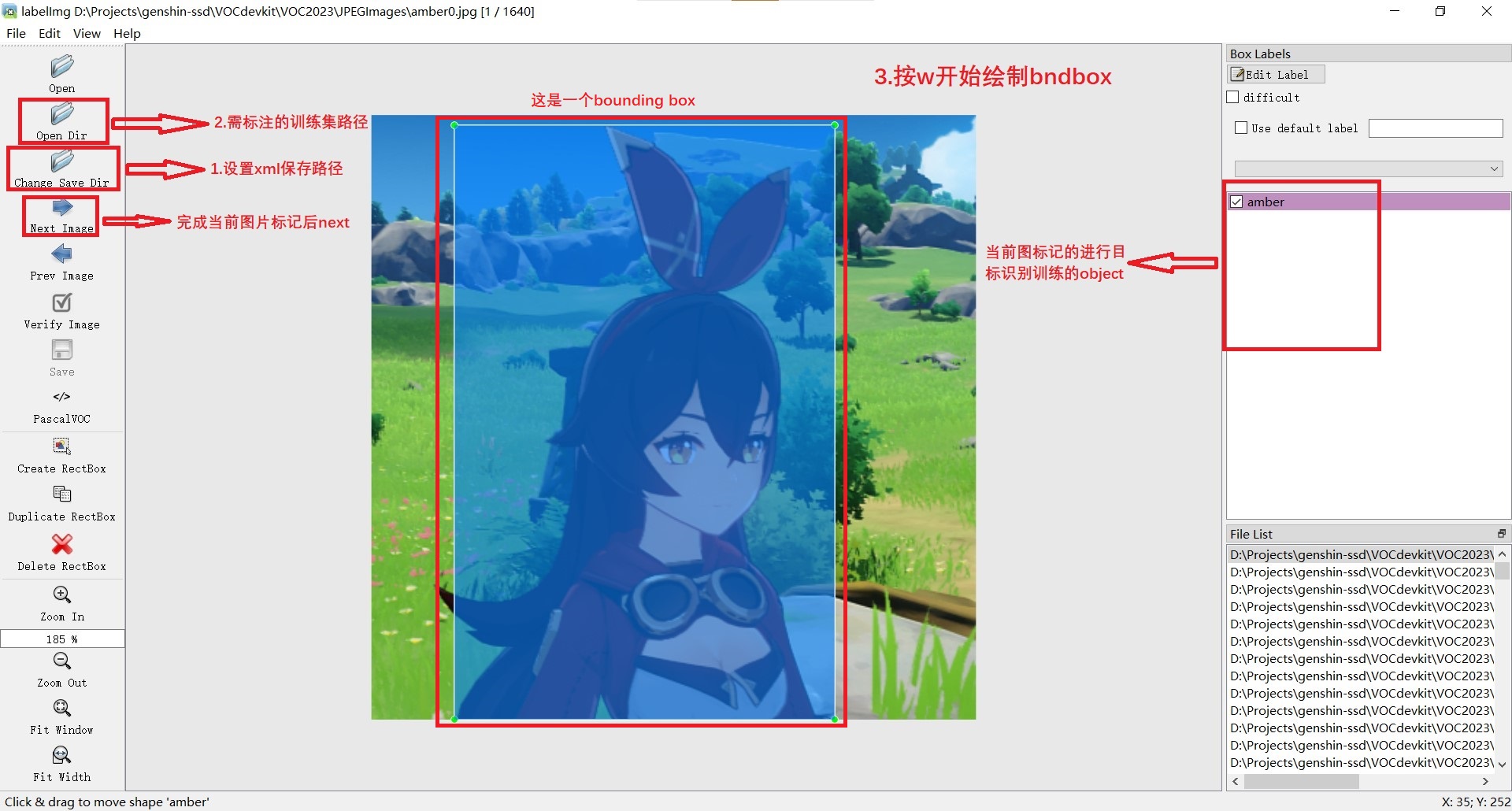
Ⅰ、通过 Labelimg 标记 bndbox
- 安装Labelimg,打开命令提示符,在其中输入如下命令:
pip install labelimg
- 使用 cmd 打开 Labelimg 的GUI界面:
labelimg
下图标注了使用方法:
Ⅱ、批处理 VOC Annotation
使用Labelimg标注图片的 bounding box 虽精准但极为烦杂,个人实在没有精力将千余张图片精准地标记真实框。
而由于Genshin Head Datasets数据集已经完成了原神角色的头部截取,所以本文选择直接将图片的长宽作为bndbox的长宽,批处理生成符合VOC格式的 xml 文件。
def annotations_generator():
"""
生成对原神头像的Annotations XML文件
其bndbox为全图大小
:return:
"""
path = './Genshin Head Dataset/processed_images/'
pathList = os.listdir(path)
for name in pathList:
fileList = os.listdir(path + name)
for file in fileList:
# 获取高与宽
image = cv2.imread(path + name + os.sep + file)
w = image.shape[1]
h = image.shape[0]
# 生成xml内容
string = """<annotation>
<folder>JPEGImages</folder>
<filename>""" + file + """</filename>
<path>D:\Projects\genshin-ssd\VOCdevkit\VOC2007\JPEGImages\\""" + file + """</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>""" + str(w) + """</width>
<height>""" + str(h) + """</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>""" + name + """</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1</xmin>
<ymin>1</ymin>
<xmax>""" + str(w) + """</xmax>
<ymax>""" + str(h) + """</ymax>
</bndbox>
</object>
</annotation>
"""
with open('./VOCdevkit/VOC2023/Annotations' + '/' + file.removesuffix('.jpg') + '.xml', mode='w', encoding='utf-8') as fp:
fp.write(string)
print('文件:' + file + '的xml注解文件生成完成!')
三、训练与预测
整理完VOC数据集后,就可以开始对原神人物识别任务进行目标检测的AI模型训练与预测了。
我们可以通过 model.summary() 获得目前神经网络模型 ssd300 的基本结构:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 300, 300, 3 0 []
)]
conv1_1 (Conv2D) (None, 300, 300, 64 1792 ['input_1[0][0]']
)
conv1_2 (Conv2D) (None, 300, 300, 64 36928 ['conv1_1[0][0]']
)
pool1 (MaxPooling2D) (None, 150, 150, 64 0 ['conv1_2[0][0]']
)
conv2_1 (Conv2D) (None, 150, 150, 12 73856 ['pool1[0][0]']
8)
conv2_2 (Conv2D) (None, 150, 150, 12 147584 ['conv2_1[0][0]']
8)
pool2 (MaxPooling2D) (None, 75, 75, 128) 0 ['conv2_2[0][0]']
conv3_1 (Conv2D) (None, 75, 75, 256) 295168 ['pool2[0][0]']
conv3_2 (Conv2D) (None, 75, 75, 256) 590080 ['conv3_1[0][0]']
conv3_3 (Conv2D) (None, 75, 75, 256) 590080 ['conv3_2[0][0]']
pool3 (MaxPooling2D) (None, 38, 38, 256) 0 ['conv3_3[0][0]']
conv4_1 (Conv2D) (None, 38, 38, 512) 1180160 ['pool3[0][0]']
conv4_2 (Conv2D) (None, 38, 38, 512) 2359808 ['conv4_1[0][0]']
conv4_3 (Conv2D) (None, 38, 38, 512) 2359808 ['conv4_2[0][0]']
pool4 (MaxPooling2D) (None, 19, 19, 512) 0 ['conv4_3[0][0]']
conv5_1 (Conv2D) (None, 19, 19, 512) 2359808 ['pool4[0][0]']
conv5_2 (Conv2D) (None, 19, 19, 512) 2359808 ['conv5_1[0][0]']
conv5_3 (Conv2D) (None, 19, 19, 512) 2359808 ['conv5_2[0][0]']
pool5 (MaxPooling2D) (None, 19, 19, 512) 0 ['conv5_3[0][0]']
fc6 (Conv2D) (None, 19, 19, 1024 4719616 ['pool5[0][0]']
)
fc7 (Conv2D) (None, 19, 19, 1024 1049600 ['fc6[0][0]']
)
conv6_1 (Conv2D) (None, 19, 19, 256) 262400 ['fc7[0][0]']
conv6_padding (ZeroPadding2D) (None, 21, 21, 256) 0 ['conv6_1[0][0]']
conv6_2 (Conv2D) (None, 10, 10, 512) 1180160 ['conv6_padding[0][0]']
conv7_1 (Conv2D) (None, 10, 10, 128) 65664 ['conv6_2[0][0]']
conv7_padding (ZeroPadding2D) (None, 12, 12, 128) 0 ['conv7_1[0][0]']
conv7_2 (Conv2D) (None, 5, 5, 256) 295168 ['conv7_padding[0][0]']
conv8_1 (Conv2D) (None, 5, 5, 128) 32896 ['conv7_2[0][0]']
conv8_2 (Conv2D) (None, 3, 3, 256) 295168 ['conv8_1[0][0]']
conv9_1 (Conv2D) (None, 3, 3, 128) 32896 ['conv8_2[0][0]']
conv4_3_norm (Normalize) (None, 38, 38, 512) 512 ['conv4_3[0][0]']
conv9_2 (Conv2D) (None, 1, 1, 256) 295168 ['conv9_1[0][0]']
conv4_3_norm_mbox_conf (Conv2D (None, 38, 38, 84) 387156 ['conv4_3_norm[0][0]']
)
fc7_mbox_conf (Conv2D) (None, 19, 19, 126) 1161342 ['fc7[0][0]']
conv6_2_mbox_conf (Conv2D) (None, 10, 10, 126) 580734 ['conv6_2[0][0]']
conv7_2_mbox_conf (Conv2D) (None, 5, 5, 126) 290430 ['conv7_2[0][0]']
conv8_2_mbox_conf (Conv2D) (None, 3, 3, 84) 193620 ['conv8_2[0][0]']
conv9_2_mbox_conf (Conv2D) (None, 1, 1, 84) 193620 ['conv9_2[0][0]']
conv4_3_norm_mbox_loc (Conv2D) (None, 38, 38, 16) 73744 ['conv4_3_norm[0][0]']
fc7_mbox_loc (Conv2D) (None, 19, 19, 24) 221208 ['fc7[0][0]']
conv6_2_mbox_loc (Conv2D) (None, 10, 10, 24) 110616 ['conv6_2[0][0]']
conv7_2_mbox_loc (Conv2D) (None, 5, 5, 24) 55320 ['conv7_2[0][0]']
conv8_2_mbox_loc (Conv2D) (None, 3, 3, 16) 36880 ['conv8_2[0][0]']
conv9_2_mbox_loc (Conv2D) (None, 1, 1, 16) 36880 ['conv9_2[0][0]']
conv4_3_norm_mbox_conf_flat (F (None, 121296) 0 ['conv4_3_norm_mbox_conf[0][0]']
latten)
fc7_mbox_conf_flat (Flatten) (None, 45486) 0 ['fc7_mbox_conf[0][0]']
conv6_2_mbox_conf_flat (Flatte (None, 12600) 0 ['conv6_2_mbox_conf[0][0]']
n)
conv7_2_mbox_conf_flat (Flatte (None, 3150) 0 ['conv7_2_mbox_conf[0][0]']
n)
conv8_2_mbox_conf_flat (Flatte (None, 756) 0 ['conv8_2_mbox_conf[0][0]']
n)
conv9_2_mbox_conf_flat (Flatte (None, 84) 0 ['conv9_2_mbox_conf[0][0]']
n)
conv4_3_norm_mbox_loc_flat (Fl (None, 23104) 0 ['conv4_3_norm_mbox_loc[0][0]']
atten)
fc7_mbox_loc_flat (Flatten) (None, 8664) 0 ['fc7_mbox_loc[0][0]']
conv6_2_mbox_loc_flat (Flatten (None, 2400) 0 ['conv6_2_mbox_loc[0][0]']
)
conv7_2_mbox_loc_flat (Flatten (None, 600) 0 ['conv7_2_mbox_loc[0][0]']
)
conv8_2_mbox_loc_flat (Flatten (None, 144) 0 ['conv8_2_mbox_loc[0][0]']
)
conv9_2_mbox_loc_flat (Flatten (None, 16) 0 ['conv9_2_mbox_loc[0][0]']
)
mbox_conf (Concatenate) (None, 183372) 0 ['conv4_3_norm_mbox_conf_flat[0][
0]',
'fc7_mbox_conf_flat[0][0]',
'conv6_2_mbox_conf_flat[0][0]',
'conv7_2_mbox_conf_flat[0][0]',
'conv8_2_mbox_conf_flat[0][0]',
'conv9_2_mbox_conf_flat[0][0]']
mbox_loc (Concatenate) (None, 34928) 0 ['conv4_3_norm_mbox_loc_flat[0][0
]',
'fc7_mbox_loc_flat[0][0]',
'conv6_2_mbox_loc_flat[0][0]',
'conv7_2_mbox_loc_flat[0][0]',
'conv8_2_mbox_loc_flat[0][0]',
'conv9_2_mbox_loc_flat[0][0]']
mbox_conf_logits (Reshape) (None, 8732, 21) 0 ['mbox_conf[0][0]']
mbox_loc_final (Reshape) (None, 8732, 4) 0 ['mbox_loc[0][0]']
mbox_conf_final (Activation) (None, 8732, 21) 0 ['mbox_conf_logits[0][0]']
predictions (Concatenate) (None, 8732, 25) 0 ['mbox_loc_final[0][0]',
'mbox_conf_final[0][0]']
==================================================================================================
Total params: 26,285,486
Trainable params: 26,285,486
Non-trainable params: 0
__________________________________________________________________________________________________
Total GFLOPs: 62.798G
Ⅰ、train
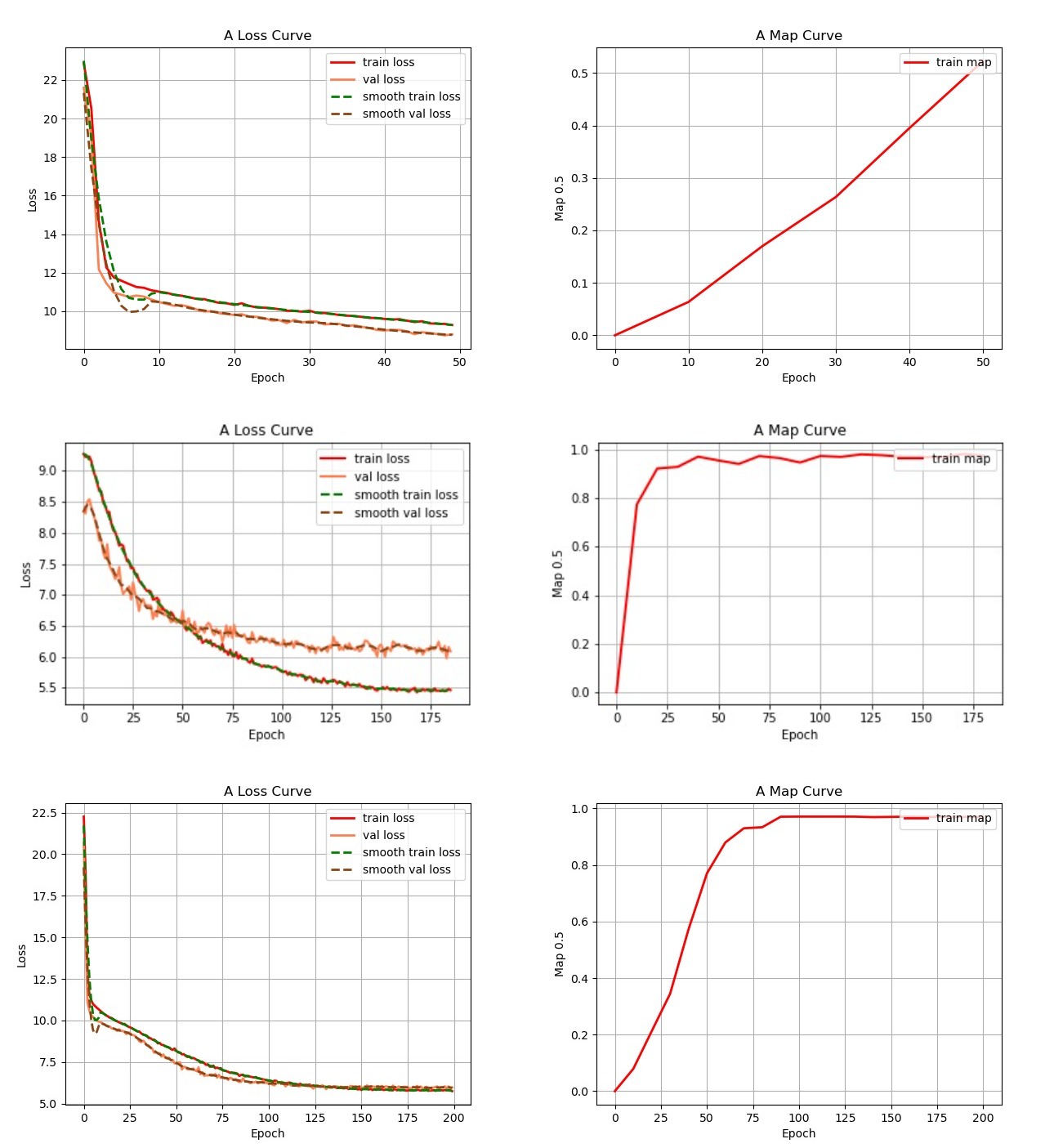
运行 train.py 文件后开始网络训练,训练好的权值文件将保存在 logs 文件夹中,每个训练世代(Epoch)包含若干训练步长(Step),每个训练步长(Step)进行一次梯度下降。
损失值的大小用于判断是否收敛,比较重要的是有收敛的趋势,即验证集损失不断下降,如果验证集损失基本上不改变的话,模型基本上就收敛了。损失值的具体大小并没有什么意义,大和小只在于损失的计算方式,并非是接近于0才好。如果想要让损失好看点,可以直接到对应的损失函数里面除上10000。
训练过程中的损失值会保存在 logs 文件夹下的 loss_%Y_%m_%d_%H_%M_%S 文件夹中。
到目前为止尝试了 Freeze 冻结网络结构训练 50 个 epochs,和 UnFreeze 训练近 400 个 epochs,模型基本收敛。
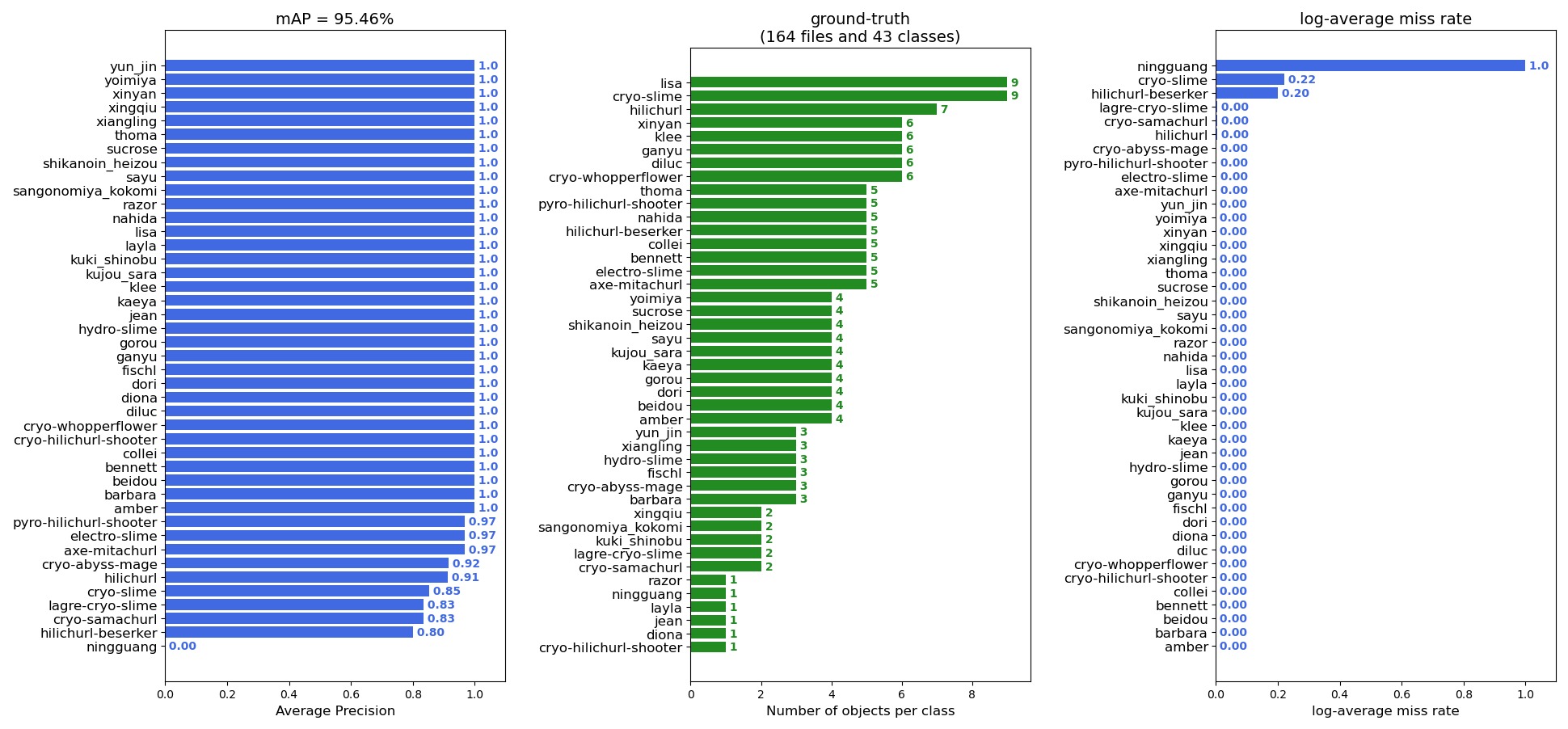
使用 get_map.py 计算训练好的 best_epoch_weights.h5 权值文件在对验真集进行预测时,当门限值(Confidence)为0.5时,所对应的 Recall 和 Precision 值。
Ⅱ、predict
训练结果预测需要用到两个文件,分别是ssd.py和predict.py。
- model_path 指向训练好的权值文件(.h5),在logs文件夹里。
- classes_path 指向检测类别所对应的txt。
_defaults = {
# --------------------------------------------------------------------------#
# 使用自己训练好的模型进行预测一定要修改model_path和classes_path!
# model_path指向logs文件夹下的权值文件,classes_path指向model_data下的txt
#
# 训练好后logs文件夹下存在多个权值文件,选择验证集损失较低的即可。
# 验证集损失较低不代表mAP较高,仅代表该权值在验证集上泛化性能较好。
# 如果出现shape不匹配,同时要注意训练时的model_path和classes_path参数的修改
# --------------------------------------------------------------------------#
"model_path": 'model_data/best_epoch_weights.h5',
"classes_path": 'model_data/voc_classes.txt',
# ---------------------------------------------------------------------#
# 用于预测的图像大小,和train时使用同一个即可
# ---------------------------------------------------------------------#
"input_shape": [300, 300],
# ---------------------------------------------------------------------#
# 只有得分大于置信度的预测框会被保留下来
# ---------------------------------------------------------------------#
"confidence": 0.5,
# ---------------------------------------------------------------------#
# 非极大抑制所用到的nms_iou大小
# ---------------------------------------------------------------------#
"nms_iou": 0.45,
# ---------------------------------------------------------------------#
# 用于指定先验框的大小
# ---------------------------------------------------------------------#
'anchors_size': [30, 60, 111, 162, 213, 264, 315],
# ---------------------------------------------------------------------#
# 该变量用于控制是否使用letterbox_image对输入图像进行不失真的resize,
# 在多次测试后,发现关闭letterbox_image直接resize的效果更好
# ---------------------------------------------------------------------#
"letterbox_image": False,
}
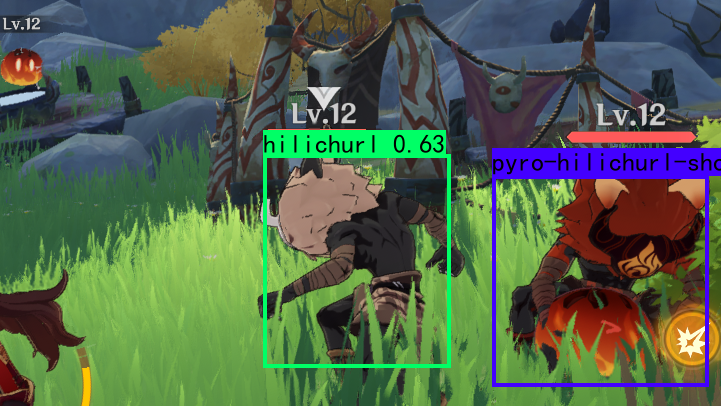
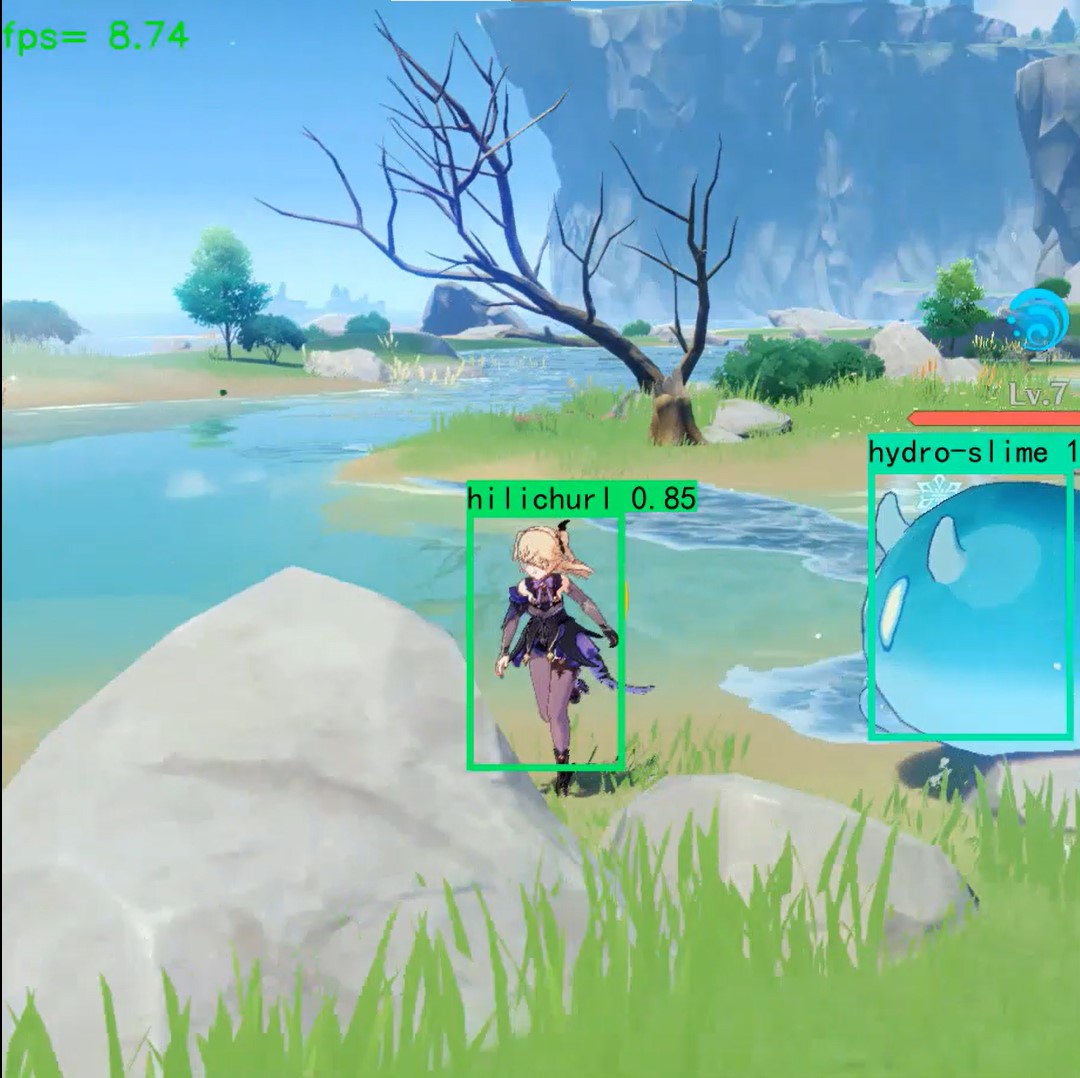
下图是到今日为止(2023/1/26),训练的神经网络模型对原神随机截图的人物检测演示结果:
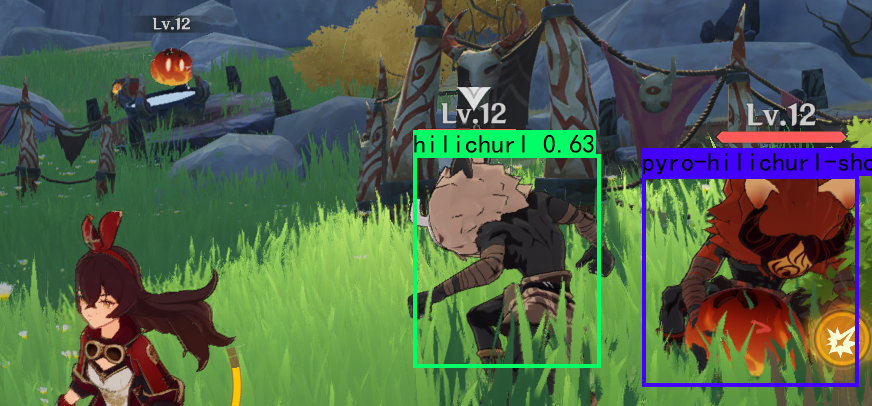
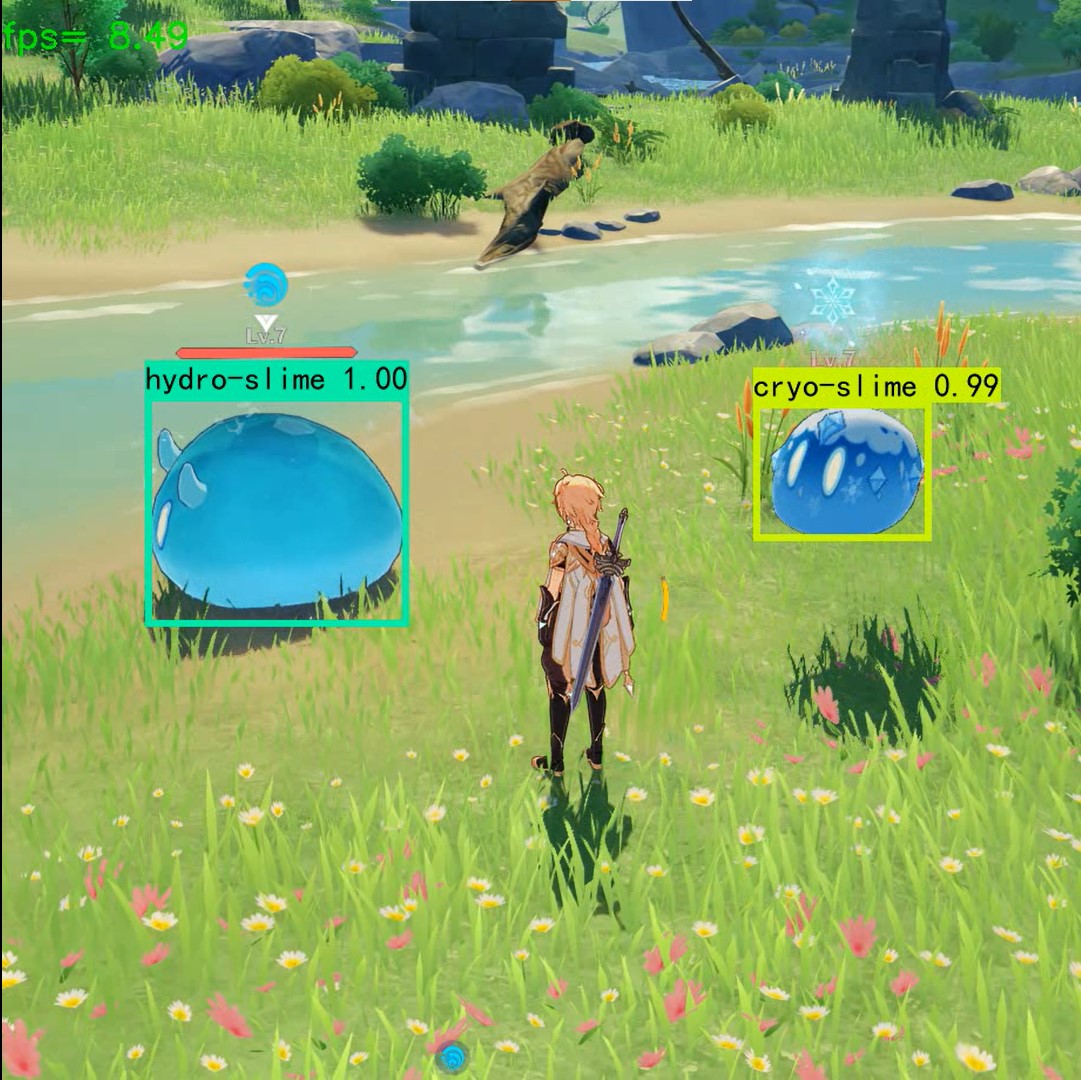

事实上,ai常常将原神人物全身模型识别为丘丘人(hilichurl);这很可能是由于原神角色的训练集仅有头部信息,而ai模型无法正常理解人物头部与头部以下部位的不明显边缘过渡,这导致问题了发生。
参考文章
本文来自博客园,作者:TfiyuenLau,转载请注明原文链接:https://www.cnblogs.com/tfiyuenlau/articles/17068400.html


{kind=link}
{kind=link}
{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人