
nginx2
https://www.cnblogs.com/knowledgesea/p/5199046.html
https://www.cnblogs.com/knowledgesea/p/5175711.html
https://www.codesheep.cn/2018/06/26/%E4%BB%8E%E4%B8%80%E4%BB%BD%E9%85%8D%E7%BD%AE%E6%B8%85%E5%8D%95%E8%AF%A6%E8%A7%A3Nginx%E6%9C%8D%E5%8A%A1%E5%99%A8%E9%85%8D%E7%BD%AE/ 从一份配置清单详解Nginx服务器配置
《Nginx高性能Web服务器详解》


检测配置文件是否有语法错误:nginx -t
查看系统允许进程打开的文件描述符个数:cat /proc/sys/fs/file-max
https://www.codesheep.cn/2018/05/25/Nginx%E6%9C%8D%E5%8A%A1%E5%99%A8%E5%BC%80%E7%AE%B1%E4%BD%93%E9%AA%8C/ Nginx服务器开箱体验
Nginx配置文件的整体结构
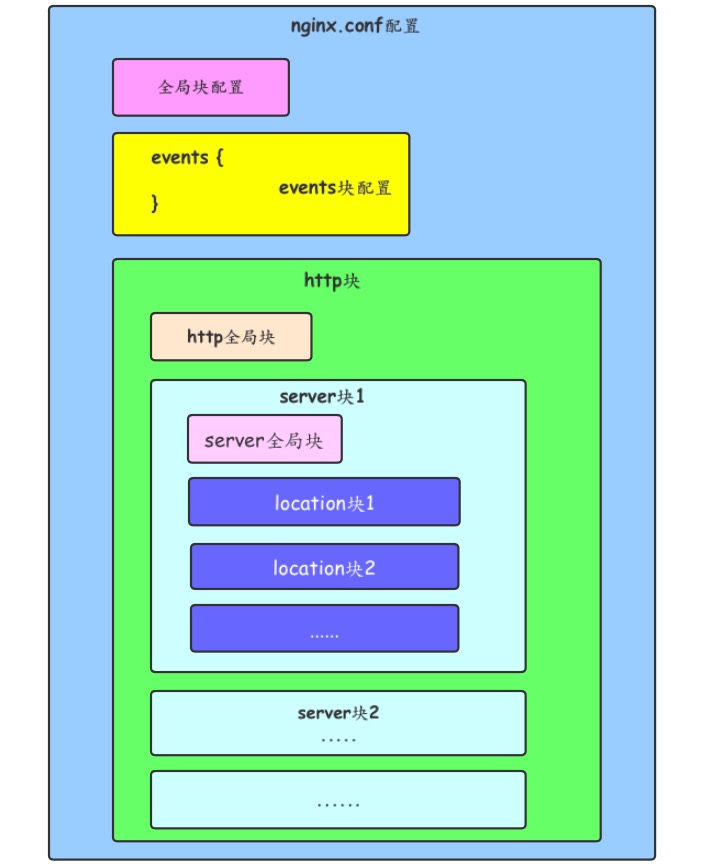 nginx配置文件结构
nginx配置文件结构
从图中可以看出主要包含以下几大部分内容:
1. 全局块
该部分配置主要影响Nginx全局,通常包括下面几个部分:
- 配置运行Nginx服务器用户(组)
- worker process数
- Nginx进程PID存放路径
- 错误日志的存放路径
- 配置文件的引入
2. events块
该部分配置主要影响Nginx服务器与用户的网络连接,主要包括:
- 设置网络连接的序列化
- 是否允许同时接收多个网络连接
- 事件驱动模型的选择
- 最大连接数的配置
3. http块
- 定义MIMI-Type
- 自定义服务日志
- 允许sendfile方式传输文件
- 连接超时时间
- 单连接请求数上限
4. server块
- 配置网络监听
- 基于名称的虚拟主机配置
- 基于IP的虚拟主机配置
5. location块
- location配置
- 请求根目录配置
- 更改location的URI
- 网站默认首页配置
一份配置清单例析
笔者按照文章:《Nginx服务器开箱体验》 中的实验,给出了一份简要的清单配置举例:
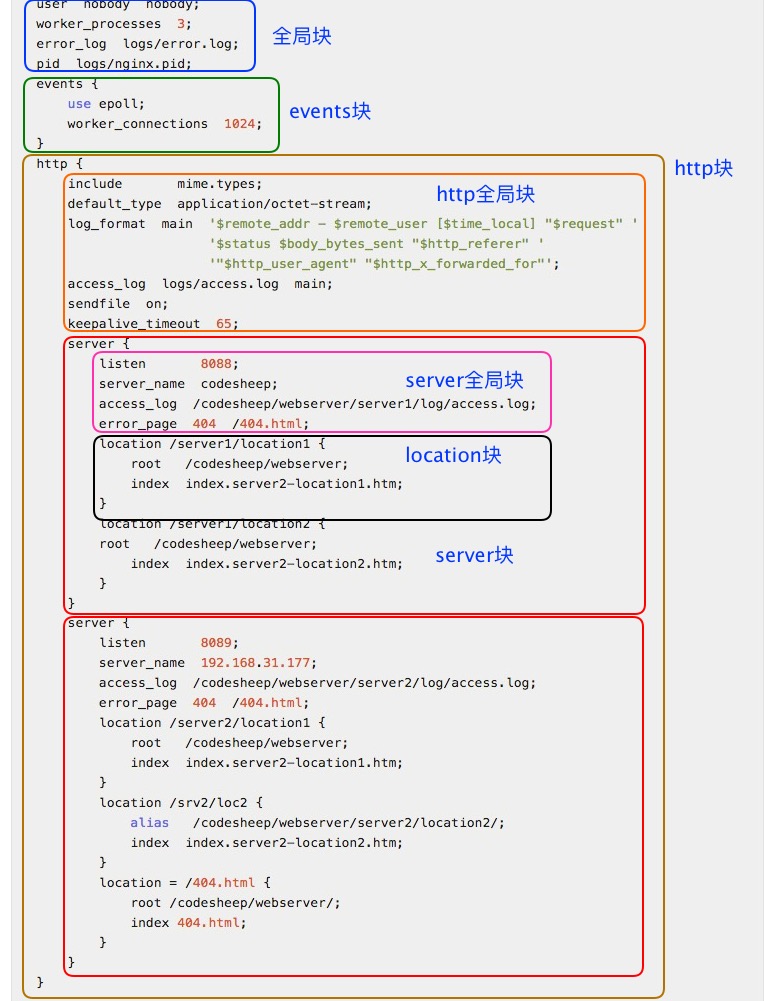 一份配置清单例析
一份配置清单例析
配置代码如下:
1
|
|
接下来就来详细剖析以下配置文件中各个指令的含义⬇️
配置运行Nginx服务器用户(组)
指令格式:user user [group];
- user:指定可以运行Nginx服务器的用户
- group:可选项,可以运行Nginx服务器的用户组
如果user指令不配置或者配置为 user nobody nobody ,则默认所有用户都可以启动Nginx进程
worker process数配置
Nginx服务器实现并发处理服务的关键,指令格式:worker_processes number | auto;
- number:Nginx进程最多可以产生的worker process数
- auto:Nginx进程将自动检测
按照上文中的配置清单的实验,我们给worker_processes配置的数目是:3,启动Nginx服务器后,我们可以后台看一下主机上的Nginx进程情况:
1
|
ps -aux | grep nginx
|
很明显,理解 worker_processes 这个指令的含义就很容易了
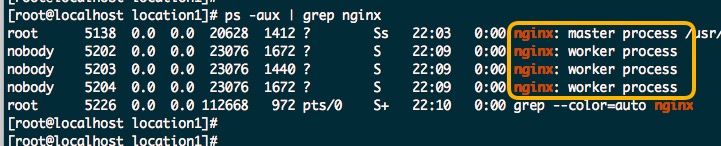 ps -aux | grep nginx
ps -aux | grep nginx
Nginx进程PID存放路径
Nginx进程是作为系统守护进程在运行,需要在某文件中保存当前运行程序的主进程号,Nginx支持该保存文件路径的自定义
指令格式:pid file;
-
file:指定存放路径和文件名称
-
如果不指定默认置于路径
logs/nginx.pid
错误日志的存放路径
指定格式:error_log file | stderr;
- file:日志输出到某个文件file
- stderr:日志输出到标准错误输出
配置文件的引入
指令格式:include file;
- 该指令主要用于将其他的Nginx配置或者第三方模块的配置引用到当前的主配置文件中
设置网络连接的序列化
指令格式:accept_mutex on | off;
- 该指令默认为on状态,表示会对多个Nginx进程接收连接进行序列化,防止多个进程对连接的争抢。
说到该指令,首先得阐述一下什么是所谓的 “惊群问题”,可以参考 WIKI百科的解释。就Nginx的场景来解释的话大致的意思就是:当一个新网络连接来到时,多个worker进程会被同时唤醒,但仅仅只有一个进程可以真正获得连接并处理之。如果每次唤醒的进程数目过多的话,其实是会影响一部分性能的。
所以在这里,如果accept_mutex on,那么多个worker将是以串行方式来处理,其中有一个worker会被唤醒;反之若accept_mutex off,那么所有的worker都会被唤醒,不过只有一个worker能获取新连接,其它的worker会重新进入休眠状态
这个值的开关与否其实是要和具体场景挂钩的。
是否允许同时接收多个网络连接
指令格式:multi_accept on | off;
- 该指令默认为off状态,意指每个worker process 一次只能接收一个新到达的网络连接。若想让每个Nginx的worker process都有能力同时接收多个网络连接,则需要开启此配置
事件驱动模型的选择
指令格式:use model;
- model模型可选择项包括:select、poll、kqueue、epoll、rtsig等……
最大连接数的配置
指令格式:worker_connections number;
- number默认值为512,表示允许每一个worker process可以同时开启的最大连接数
定义MIME-Type
指令格式:
1
|
include mime.types;
|
-
MIME-Type指的是网络资源的媒体类型,也即前端请求的资源类型
-
include指令将mime.types文件包含进来
cat mime.types 来查看mime.types文件内容,我们发现其就是一个types结构,里面包含了各种浏览器能够识别的MIME类型以及对应类型的文件后缀名字,如下所示:
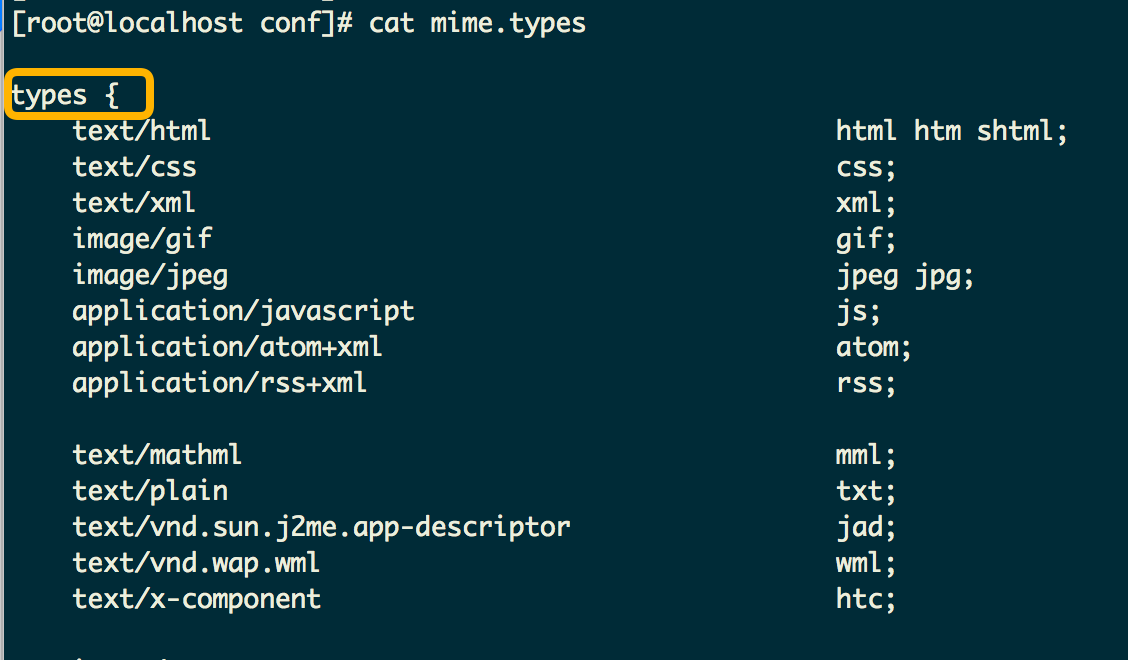 cat mime.types
cat mime.types
自定义服务日志
指令格式:
1
|
access_log path [format];
|
-
path:自定义服务日志的路径 + 名称
-
format:可选项,自定义服务日志的字符串格式。其也可以使用
log_format定义的格式
允许sendfile方式传输文件
指令格式:
1
|
sendfile on | off;
|
- 前者用于开启或关闭使用sendfile()传输文件,默认off
- 后者指令若size>0,则Nginx进程的每个worker process每次调用sendfile()传输的数据了最大不能超出此值;若size=0则表示不限制。默认值为0
连接超时时间配置
指令格式:keepalive_timeout timeout [header_timeout];
-
timeout 表示server端对连接的保持时间,默认75秒
-
header_timeout 为可选项,表示在应答报文头部的 Keep-Alive 域设置超时时间:“Keep-Alive : timeout = header_timeout”
单连接请求数上限
指令格式:keepalive_requests number;
- 该指令用于限制用户通过某一个连接向Nginx服务器发起请求的次数
配置网络监听
指令格式:
-
第一种:配置监听的IP地址:
listen IP[:PORT]; -
第二种:配置监听的端口:
listen PORT;
实际举例:
1
|
listen 192.168.31.177:8080; # 监听具体IP和具体端口上的连接
|
基于名称和IP的虚拟主机配置
指令格式:server_name name1 name2 ...
- name可以有多个并列名称,而且此处的name支持正则表达式书写
实际举例:
1
|
server_name ~^www\d+\.myserver\.com$
|
此时表示该虚拟主机可以接收类似域名 www1.myserver.com 等的请求而拒绝 www.myserver.com 的域名请求,所以说用正则表达式可以实现更精准的控制
至于基于IP的虚拟主机配置比较简单,不再太赘述:
指令格式:server_name IP地址
location配置
指令格式为:location [ = | ~ | ~* | ^~ ] uri {...}
- 这里的uri分为标准uri和正则uri,两者的唯一区别是uri中是否包含正则表达式
uri前面的方括号中的内容是可选项,解释如下:
-
“=”:用于标准uri前,要求请求字符串与uri严格匹配,一旦匹配成功则停止
-
“~”:用于正则uri前,并且区分大小写
-
“~*”:用于正则uri前,但不区分大小写
-
“^~”:用于标准uri前,要求Nginx找到标识uri和请求字符串匹配度最高的location后,立即使用此location处理请求,而不再使用location块中的正则uri和请求字符串做匹配
请求根目录配置
指令格式:root path;
- path:Nginx接收到请求以后查找资源的根目录路径
当然,还可以通过alias指令来更改location接收到的URI请求路径,指令为:
1
|
alias path; # path为修改后的根路径
|
设置网站的默认首页
指令格式:index file ......
- file可以包含多个用空格隔开的文件名,首先找到哪个页面,就使用哪个页面响应请求

 浙公网安备 33010602011771号
浙公网安备 33010602011771号