中间件 MQ
一、什么是mq?
MQ全称 Message Queue(消息队列),是在消息的传输过程中保存消息的容器。多用于分布 式系统之间进行通信。
二、mq的优缺点?
优点:
1.应用解耦: 降低系统之间的耦合,提高系统的可维护性。
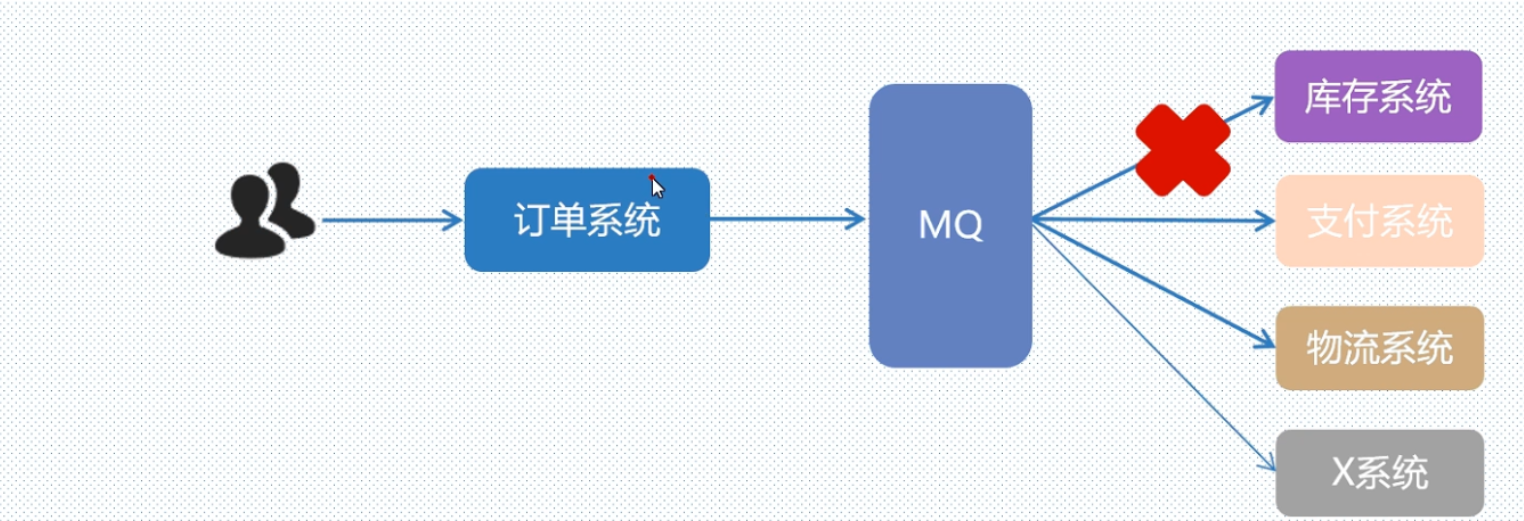

2.异步提速: 可以系统的吞吐量。
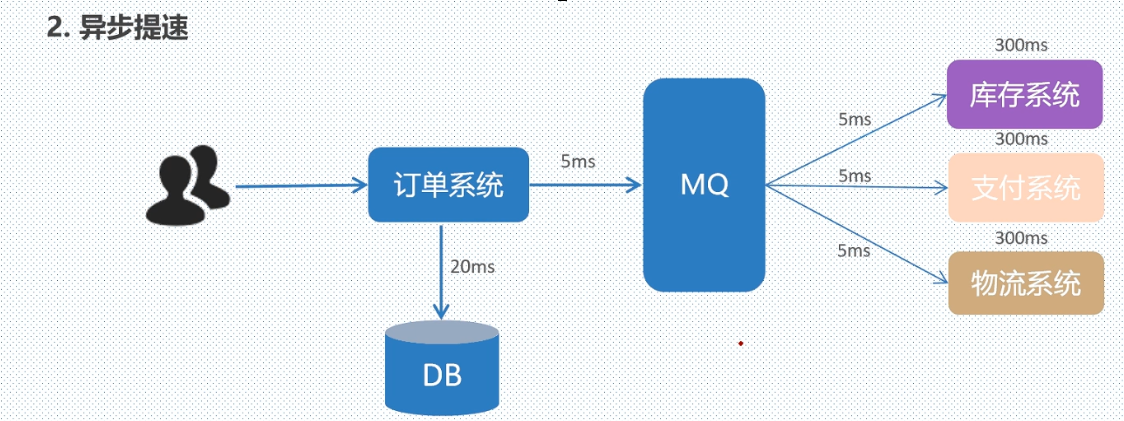

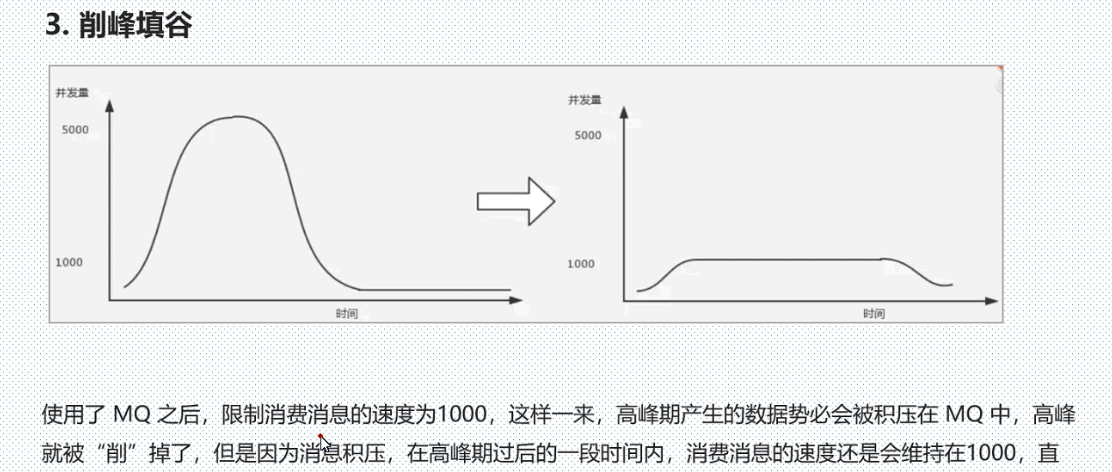
3.削峰填谷: 可以提高系统的稳定性。

缺点:
1.系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦 MQ 宕机,就会对业务造成影响。如何保证MQ的高可用?
2.系统复杂度提高
MQ 的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过 MQ 进行异步调用。如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性?
3.一致性问题
A 系统处理完业务,通过 MQ 给B、C、D三个系统发消息数据,如果 B 系统、C 系统处理成功,D 系统处理失败。如何保证消息数据处理的一致性?
三、如何选择mq?
生产者不需要从消费者处获得反馈。引入消息队列之前的直接调用,其接口的返回值应该为空,这才让明明下层的动作还没做,上层却当成动作做完了继续往后走,即所谓异步成为了可能。
容许短暂的不一致性。
确实是用了有效果。即解耦、提速、削峰这些方面的收益,超过加入MQ,管理MQ这些成本。
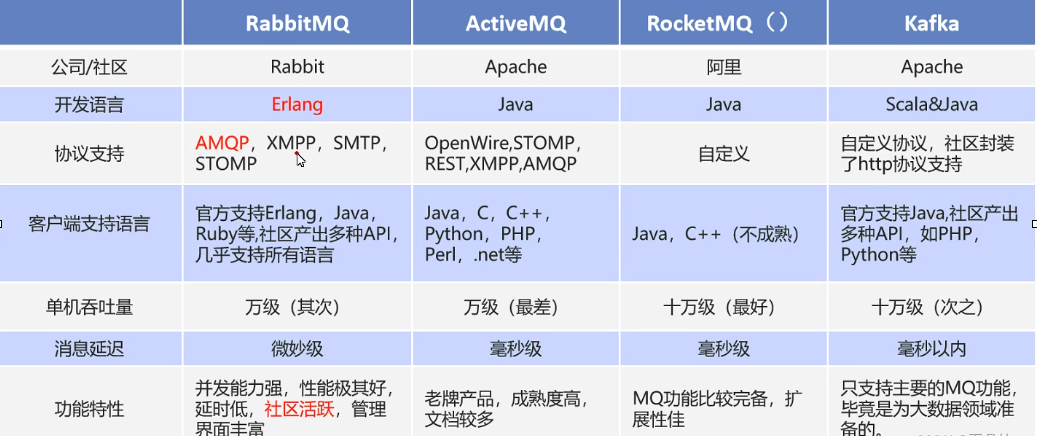
四、常见的mq产品
RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMq
五。使用场景
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。
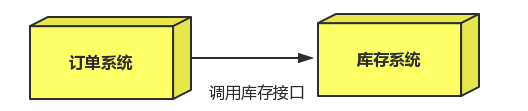
传统模式的缺点:
- 假如库存系统无法访问,则订单减库存将失败,从而导致订单失败
- 由于订单系统调用了库存系统的接口,所以它们存在耦合
引入消息队列后的做法:
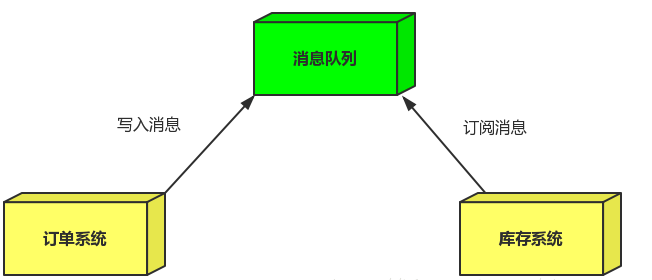
- 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功
- 库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作
- 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦
- 为了保证库存肯定有,可以将队列大小设置成库存数量,或者采用其他方式解决。
2.2 异步处理
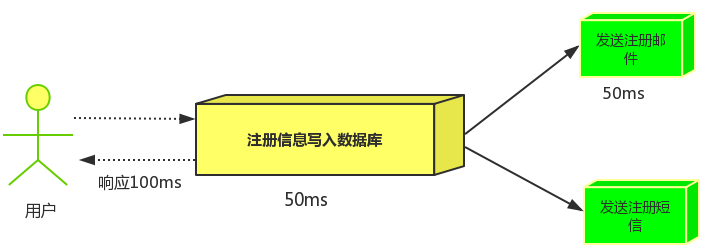
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 1.串行的方式;2.并行方式
(1) 串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端

(2) 并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间
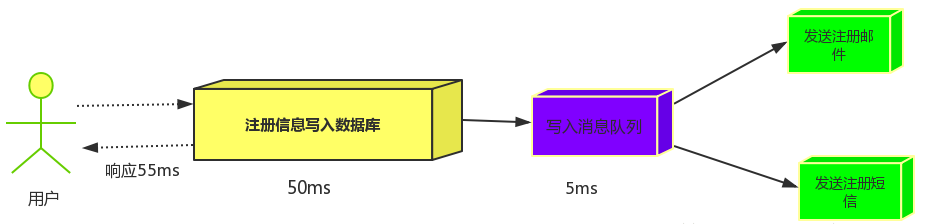
(3) 引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
2.3 流量削峰
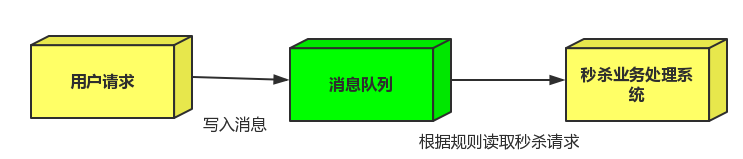
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
应用场景:系统其他时间A系统每秒请求量就100个,系统可以稳定运行。系统每天晚间八点有秒杀活动,每秒并发请求量增至1万条,但是系统最大的处理能力只能每秒处理1000个请求,于是系统崩溃,服务器宕机。
传统架构:大量用户(100万用户)通过浏览器在晚上八点高峰期同时参与秒杀活动。大量的请求涌入我们的系统中,高峰期达到每秒钟5000个请求,大量的请求打到MySQL上,每秒钟预计执行3000条SQL。但是一般的MySQL每秒钟扛住2000个请求就不错了,如果达到3000个请求的话可能MySQL直接就瘫痪了,从而系统无法被使用。但是高峰期过了之后,就成了低峰期,可能也就1万用户访问系统,每秒的请求数量也就50个左右,整个系统几乎没有任何压力。
引入MQ:100万用户在高峰期的时候,每秒请求有5000个请求左右,将这5000请求写入MQ里面,系统A每秒最多只能处理2000请求,因为MySQL每秒只能处理2000个请求。系统A从MQ中慢慢拉取请求,每秒就拉取2000个请求,不要超过自己每秒能处理的请求数量即可。MQ,每秒5000个请求进来,结果只有2000个请求出去,所以在秒杀期间(将近一小时)可能会有几十万或者几百万的请求积压在MQ中。这个短暂的高峰期积压是没问题的,因为高峰期过了之后,每秒就只有50个请求进入MQ了,但是系统还是按照每秒2000个请求的速度在处理,所以说,只要高峰期一过,系统就会快速将积压的消息消费掉。我们在此计算一下,每秒在MQ积压3000条消息,1分钟会积压18万,1小时积压1000万条消息,高峰期过后,1个多小时就可以将积压的1000万消息消费掉。
六。说明
[1]、QPS(Queries Per Second):即每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。每秒查询率:在因特网上,经常用每秒查询率来衡量域名系统服务器的机器的性能,即为QPS。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
[2]、TPS(Transactions Per Second):每秒事务数,每秒系统能够处理的事务次数。
[3]、PV(page view):即页面浏览量,或点击量;通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标。对PV的解释是,一个访问者在24小时(0点到24点)内到底看了你网站几个页面。这里需要强调:同一个人浏览你网站同一个页面,不重复计算PV量,点100次也算1次。说白了,PV就是一个访问者打开了你的几个页面。PV之于网站,就像收视率之于电视,从某种程度上已成为投资者衡量商业网站表现的最重要尺度。
PV的计算:当一个访问着访问的时候,记录他所访问的页面和对应的IP,然后确定这个IP今天访问了这个页面没有。如果你的网站到了23点,单纯IP有60万条的话,每个访问者平均访问了3个页面,那么pv表的记录就要有180万条。
[4]、UV(Unique Visitor):指访问某个站点或点击某条新闻的不同IP地址的人数。在同一天内,uv只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数。独立IP访问者提供了一定时间内不同观众数量的统计指标,而没有反应出网站的全面活动。
[5]、PR值:即PageRank,网页的级别技术,用来标识网页的等级/重要性。级别从1到10级,10级为满分。PR值越高说明该网页越受欢迎(越重要)。例如:一个PR值为1的网站表明这个网站不太具有流行度,而PR值为7到10则表明这个网站非常受欢迎(或者说极其重要)。
[6]、计算关系:
- QPS = 并发量 / 平均响应时间
- 并发量 = QPS * 平均响应时间
- 原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
- 公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS) 。
- 机器数量:峰值时间每秒QPS / 单台机器的QPS = 需要的机器 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号