
Fink
一。Flink和Spark一样,是一个大数据处理引擎。主要区别在于Flink做的是流处理,Spark做的是批处理。
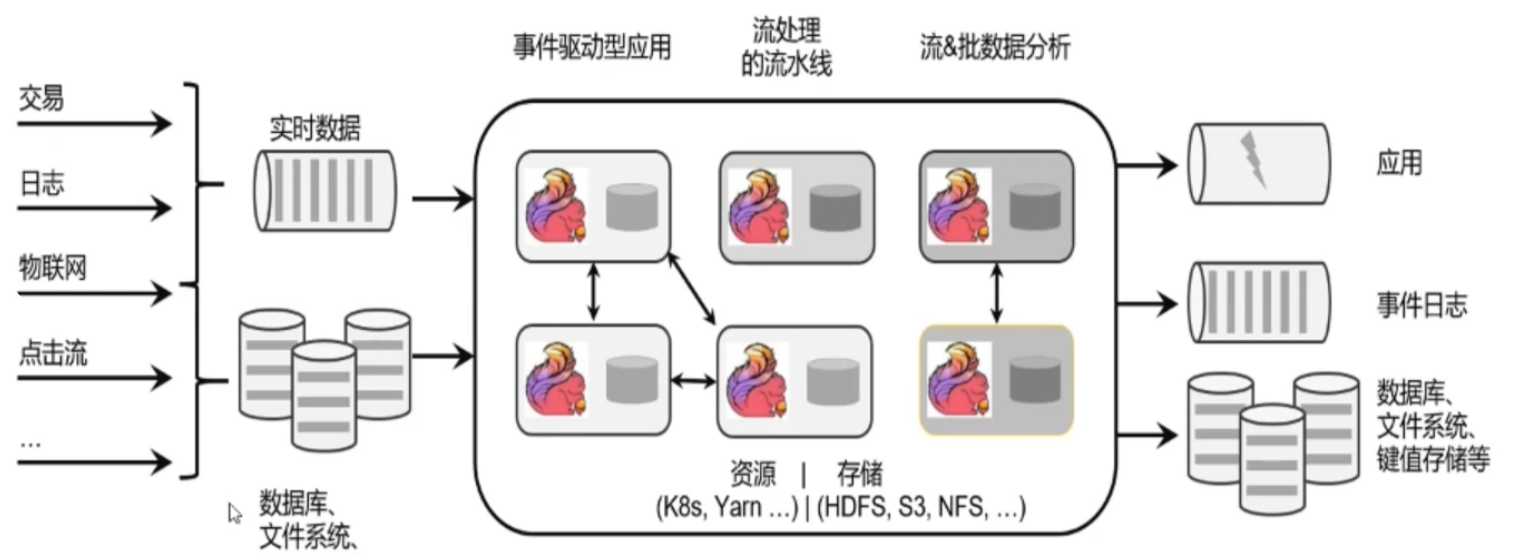
二。Flink处理的是无界的和有界的数据流,做有状态的计算。Flink 设计旨在所有常见的集群环境中运行,以任意规模和内存级速度执行计算。
三。Flink 具有以下几个特点:
支持流处理和批处理:Flink 提供了统一的编程模型,可以同时支持流处理和批处理,使得使用者可以根据自己的需求选择合适的处理方式。
高性能和低延迟:Flink 采用了基于内存的计算模型和数据流操作技术,能够实现毫秒级的延迟和高吞吐量的数据处理,适合于实时数据处理场景。
丰富的API和库:Flink 提供了丰富的API和库,包括流操作、窗口、状态管理、连接器等,使得开发人员可以快速开发出复杂的实时数据处理应用程序。
容错性:Flink 支持故障恢复和容错性,在节点故障或者网络异常的情况下仍然能够保证数据处理的正确性和完整性。
易于部署和管理:Flink 可以在各种环境中部署,包括本地模式、云平台和容器化部署。同时 Flink 还提供了易于使用的 Web UI 和命令行工具来管理和监控应用程序。
总之,Flink 是一个高性能、低延迟、可扩展和容错的分布式流处理框架,适用于广泛的实时数据处理场景,例如网络安全监测、电商推荐系统、物联网数据分析等。
(一)
有界流和无界流
1.有界流(Bounded Stream)指数据流具有明确的开始和结束时间,数据流中的数据量是确定的。因此,有界流可以视为一种特殊的流处理方式,与无界流(Unbounded Stream)形成对比。
相对于无界流而言,有界流更容易进行处理和分析,因为其数据不会持续增长,处理过程中可以对整个数据集做全局分析。同时,有界流也更容易存储和传输,因为数据量有限。
有界流通常用于以下场景:
批处理:批处理中的输入数据就是有界流,需要在任务执行前将其完全读取,才能对数据进行统计、分析等操作。
历史分析:对于历史数据的分析和挖掘,由于数据已经确定,可以采用有界流处理方式,例如运营商分析客户账单历史数据。
数据迁移:当需要从一个系统迁移到另一个系统时,可以采用有界流的方式将旧系统中的历史数据导入到新系统中。
需要注意的是,有界流通常要求数据规模较小,可以被一次性读取到内存中进行处理。如果数据规模很大,也可以采用批处理的方式进行处理。
2.无界流(Unbounded Stream)指数据源连续不断地产生数据,没有明确的开始和结束时间,数据量是无限的。因此,无界流需要一种特殊的处理方式,以实现即时的、连续的流数据处理。
相对于有界流而言,无界流具有以下特点:
数据源是连续不断的,没有明确的开始和结束时间,数据量是无限的。
连续的数据流需要即时处理,并及时生成结果反馈。
数据流的质量和准确性较低,在处理过程中需要考虑数据丢失和重复的情况。
无界流通常用于以下场景:
实时数据分析:例如网络流量监测、智能家居等应用场景,需要对数据进行实时的处理和分析。
事件处理:各种事件驱动的系统都可以看作是无界流,包括日志、消息等。
在线机器学习:通过不断更新模型,并根据新数据调整模型参数,实现在线机器学习。
为了高效地处理无界流数据,需要采取一些特殊的技术手段,例如基于流式计算引擎的实时计算框架,包括Apache Flink、Apache Storm等。这些框架能够实现对数据流的实时、增量式处理,并支持一些高级功能,如窗口、状态管理等。
有界流和无界流是两种不同的数据流模型,它们有以下几点区别:
数据流特性:有界流的数据流有明确的开始和结束时间,并且数据量是有限的,处理过程中可以对整个数据集进行全局分析;而无界流是连续不断的数据流,没有明确的开始和结束时间,并且数据量是无限的。
处理方式:由于有界流数据量有限,因此通常使用批处理技术进行处理,即将所有数据一次性读入内存进行处理;而无界流数据源是连续不断的,需要实时处理,在处理过程中需要考虑数据的持续产生和处理反馈。
处理框架:由于有界流的特殊性质,通常采用传统的批处理框架进行处理,如Hadoop、Spark等;而无界流需要采用专门的流式计算框架进行处理,如Flink、Storm等。
应用场景:有界流通常用于历史数据分析、数据迁移等场景,无界流适用于实时监控、实时报警、事件驱动等场景。
总之,有界流和无界流各自具有不同的特点和优势,在不同的应用场景下选择合适的数据流处理技术是非常重要的。
(二)
批处理和流处理
(1)批处理是一种计算模式,是指将一批数据集合在一起,一次性输入到计算系统中进行处理的方式。批处理通常是离线处理,即不需要实时响应用户请求,而是按照一定的时间间隔、容量大小或者规则定期进行批量处理。
批处理主要用于处理大规模数据集合,通常包括以下步骤:
数据采集:从不同的数据源获取数据,并对其进行清洗和加工,以保证数据质量。
数据存储:将数据存储在数据库、文件系统或者其他存储介质中,以便后续的处理操作。
数据处理:对数据进行计算、分析、转换等操作,以提取出有价值的信息。
数据输出:将处理结果输出到文件、数据库或者其他系统中,供后续的业务使用。
批处理通常适用于那些需要处理大量数据、并且能够容忍一定延迟的场景,例如金融领域的风险控制、电商平台的数据分析、科学研究的数据处理等。经典的批处理框架有 Hadoop MapReduce、Apache Spark 等。
(2)流处理是一种计算模式,是指对实时数据流进行连续的、实时的处理方式。与批处理不同,流处理通常需要以毫秒或者微秒级别响应事件的发生,并及时产生相应的反馈和输出。
流处理主要通过以下步骤进行:
数据源接入:从外部系统获取数据流,例如传感器数据、日志数据等。
数据采集和变换:对数据流进行采样、聚合、过滤等处理,以提取出有用的信息。
计算和分析:对数据进行实时的计算和分析操作,例如计算均值、标准差、频率等统计量。
输出和存储:将计算结果输出到文件、数据库或者其他系统中,以便后续的业务使用。
流处理技术具有以下优势:
实时性高:流处理可以在毫秒或者微秒级别响应事件的发生,对于对延迟较为敏感的场景非常适用。
精度高:流处理可以保证数据的实时性和准确性,能够让用户更加精细地分析和控制数据。
可扩展性强:流处理架构基于分布式系统设计,能够动态扩展和收缩集群规模以满足需求的变化。
应用场景广泛:流处理适用于各种实时数据分析需求,例如网络安全监测、智能物联网、金融交易系统、在线广告等。
经典的流处理框架包括 Apache Flink、Apache Storm、Apache Kafka Streams 等。
批处理和流处理是两种不同的数据处理方式,它们有以下几点区别:
数据处理方式:批处理是离线的、面向数据集的处理方式,需要将数据集合在一起并批量进行处理;而流处理是实时的、连续的处理方式,可以在数据到达时立即处理。
实时性:批处理通常是周期性执行的,如每天或每周一次,而流处理是实时的,对于实时性要求高的应用场景更加适用。
数据规模:批处理适用于大规模数据集的处理,处理的数据量通常很大;而流处理适用于对数据流的实时处理,处理的数据量相对较小。
处理模型:批处理采用静态作业模型,通常包括MapReduce等处理阶段;而流处理则采用动态的、增量的处理模型,能够实时地根据数据变化调整处理流程。
数据输入方式:批处理通常从存储介质中读取数据,处理完后再写入回存储介质中;而流处理则通过数据流的方式输入数据,能够及时的处理输入的数据。
总之,批处理和流处理各有优势,在不同的应用场景下针对不同的处理需求进行选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号