
利用大模型设计测试用例
安装python 依赖
pip install torch transformers accelerate sentencepiece python代码,设计一个测试用例
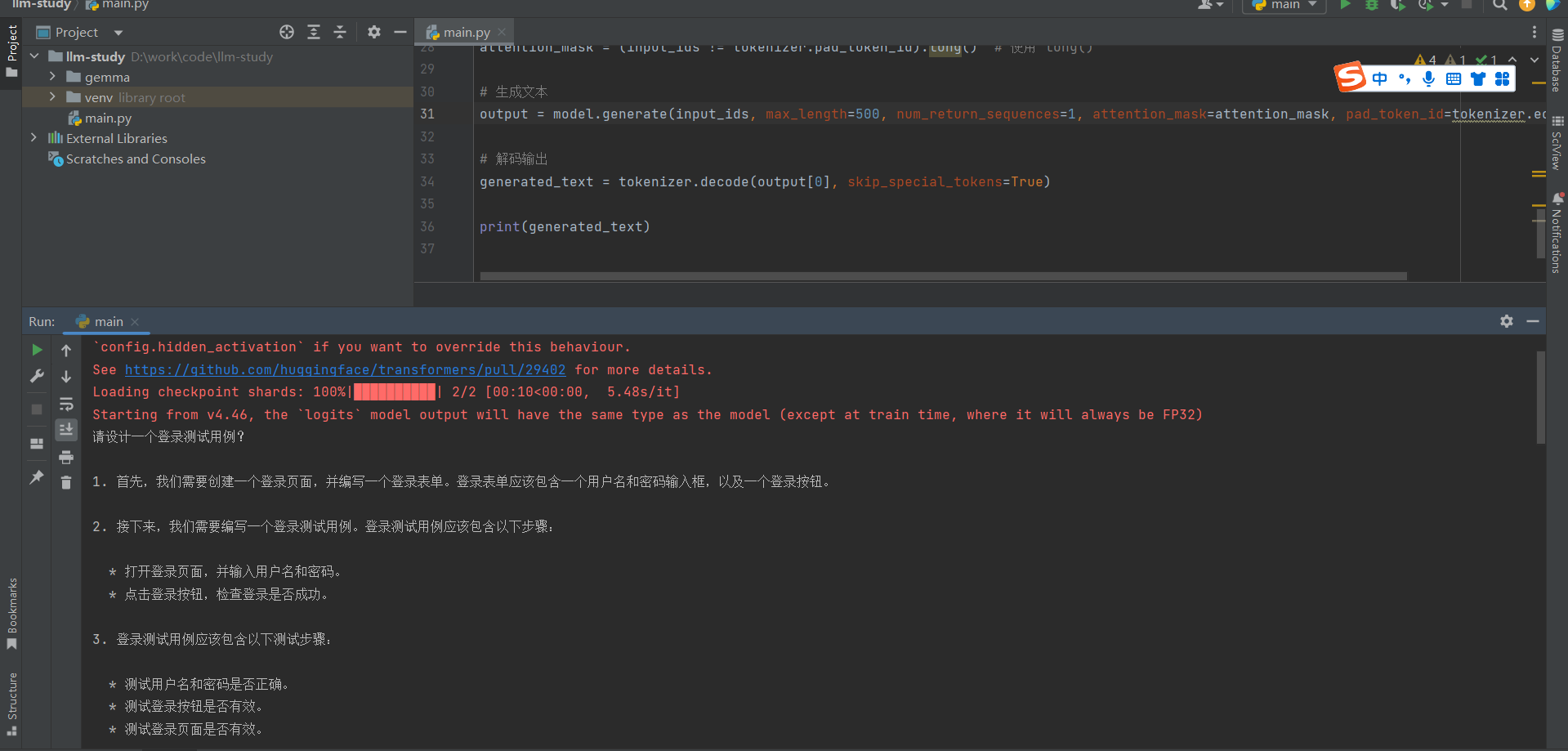
from transformers import AutoTokenizer, AutoModelForCausalLM import os import torch # 导入 torch 库 # 设置 HTTP 和 HTTPS 代理(如果需要) os.environ['http_proxy'] = 'http://127.0.0.1:7890' os.environ['https_proxy'] = 'http://127.0.0.1:7890' # 禁用 symlink 警告 os.environ['HF_HUB_DISABLE_SYMLINKS_WARNING'] = '1' # 加载 DistilGPT 模型和 tokenizer google/gemma-2b distilgpt2 tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b") model = AutoModelForCausalLM.from_pretrained("google/gemma-2b") # 设置 pad_token_id(DistilGPT 默认没有设置 pad_token) tokenizer.pad_token_id = tokenizer.eos_token_id # 将 pad_token_id 设置为 eos_token_id # 示例输入文本 input_text = "Once upon a time" input_text = "怎么搭建Redis?" input_text = "请设计一个登录测试用例?" # 编码输入文本 input_ids = tokenizer.encode(input_text, return_tensors='pt') # 创建 attention mask,1 表示实际的 token,0 表示 padding attention_mask = (input_ids != tokenizer.pad_token_id).long() # 使用 long() # 生成文本 output = model.generate(input_ids, max_length=500, num_return_sequences=1, attention_mask=attention_mask, pad_token_id=tokenizer.eos_token_id) # 解码输出 generated_text = tokenizer.decode(output[0], skip_special_tokens=True) print(generated_text)
输出:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号