
Windows10系统下Hadoop和Hive环境搭建
结合实际搭建过程中的问题,对文章进行了优化
环境准备
| 软件 | 版本 | 备注 |
|---|---|---|
Windows |
10 |
操作系统 |
JDK |
8 |
暂时不要选用大于等于JDK9的版本,因为启动虚拟机会发生未知异常 |
MySQL |
8.x |
用于管理Hive的元数据 |
Apache Hadoop |
3.3.0 |
- |
Apache Hive |
3.1.2 |
- |
Apache Hive src |
1.2.2 |
因为只有1.x版本的Hive源码提供了.bat启动脚本,有能力可以自己写脚本就不用下此源码包 |
winutils |
hadoop-3.3.0 |
Hadoop的Windows系统下的启动依赖 |
下面列举部分组件对应的下载地址:
Apache Hadoop 3.3.0:https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gzApache Hive 3.1.2:https://mirrors.bfsu.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gzApache Hive 1.2.2 src:https://mirrors.bfsu.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-src.tar.gzwinutils:https://github.com/kontext-tech/winutils(如果下载速度慢,可以先把仓库导入gitee.com再下载,或者用笔者已经同步好的仓库https://gitee.com/throwableDoge/winutils)
下载完这一些列软件之后,MySQL正常安装为系统服务随系统自启。解压hadoop-3.3.0.tar.gz、apache-hive-3.1.2-bin.tar.gz、apache-hive-1.2.2-src.tar.gz和winutils到指定目录:
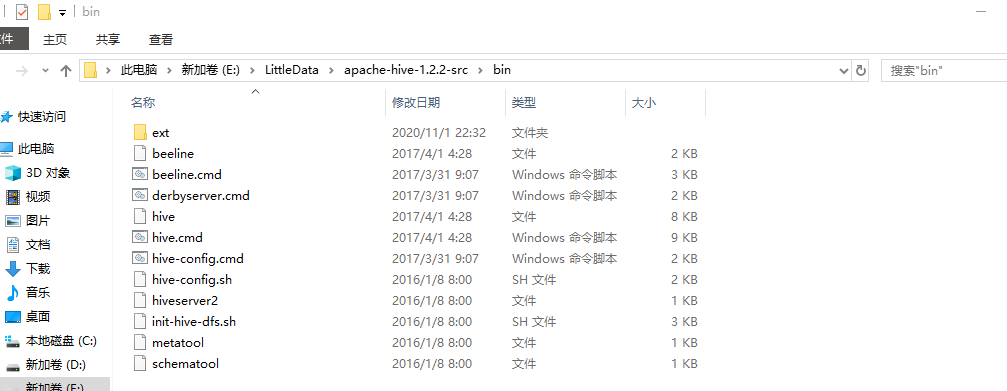
接着把源码包apache-hive-1.2.2-src.tar.gz解压后的bin目录下的文件拷贝到apache-hive-3.1.2-bin的bin目录中:
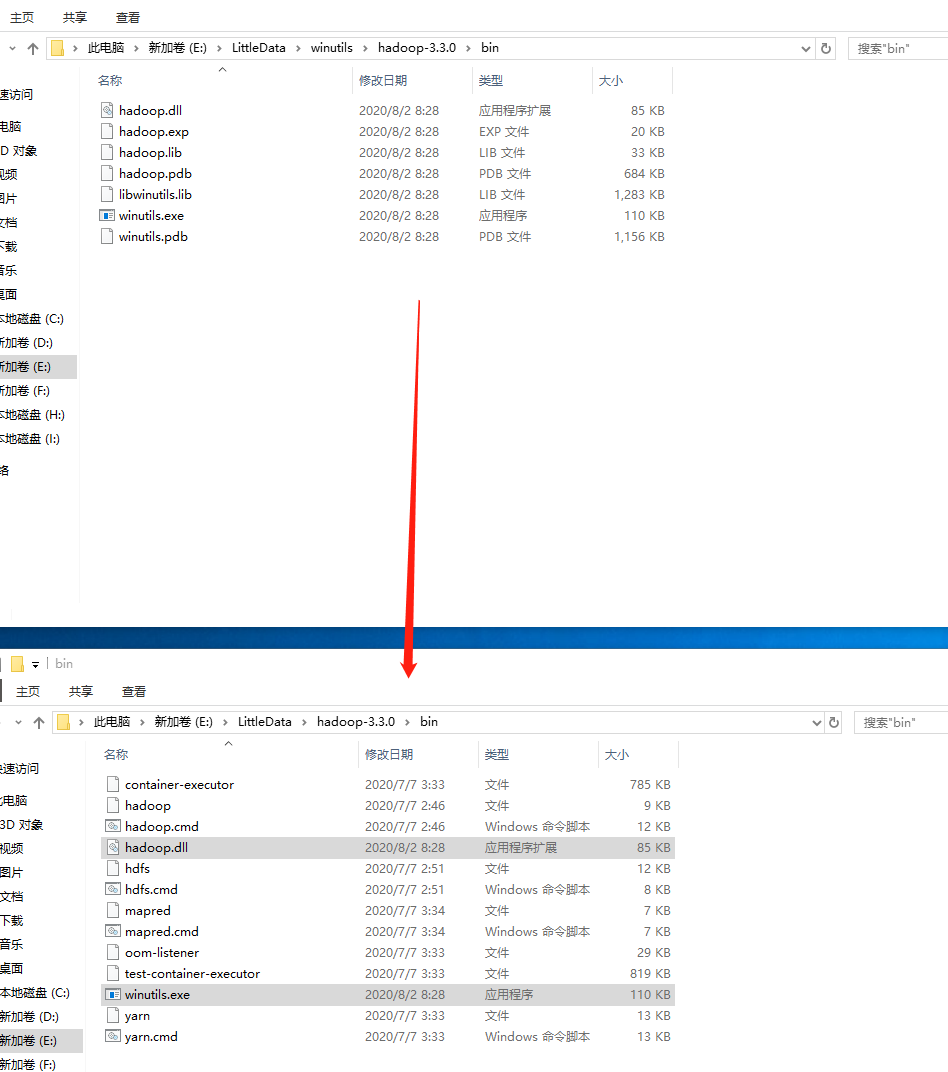
然后把winutils中的hadoop-3.3.0\bin目录下的hadoop.dll和winutils.exe文件拷贝到Hadoop的解压目录的bin文件夹下:
最后再配置一下JAVA_HOME和HADOOP_HOME两个环境变量,并且在Path中添加%JAVA_HOME%\bin;和%HADOOP_HOME%\bin:
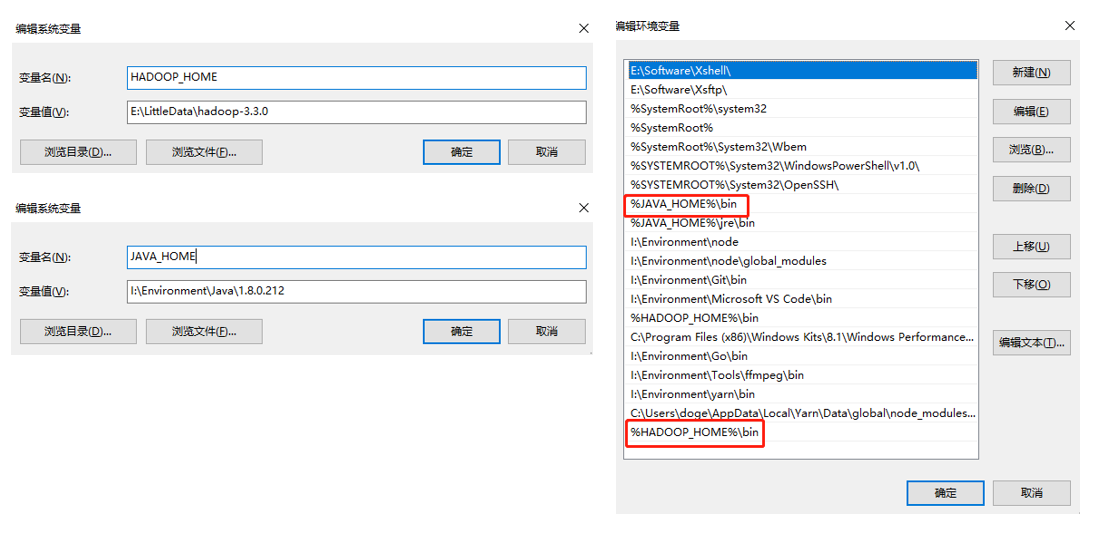
笔者本地安装的JDK版本为1.8.0.212,理论上任意一个小版本的JDK8都可以。
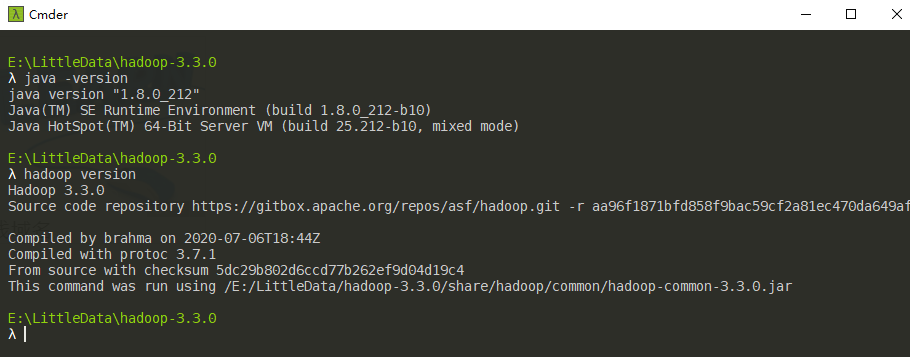
接着用命令行测试一下,如果上述步骤没问题,控制台输出如下:
配置和启动Hadoop
在HADOOP_HOME的etc\hadoop子目录下,找到并且修改下面的几个配置文件:
core-site.xml(这里的tmp目录一定要配置一个非虚拟目录,别用默认的tmp目录,否则后面会遇到权限分配失败的问题)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/hadoop/hadoop-3.3.0/data/tmp</value>
</property>
</configuration>
hdfs-site.xml(这里要预先创建nameNode和dataNode的数据存放目录,注意一下每个目录要以/开头,笔者这里预先在HADOOP_HOME/data创建了nameNode和dataNode子目录)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/hadoop/hadoop-3.3.0/data/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/hadoop/hadoop-3.3.0/data/dataNode</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
至此,最小化配置基本完成。接着需要格式化namenode并且启动Hadoop服务。切换至$HADOOP_HOME/bin目录下,使用CMD输入命令hdfs namenode -format(格式化namenode切记不要重复执行):
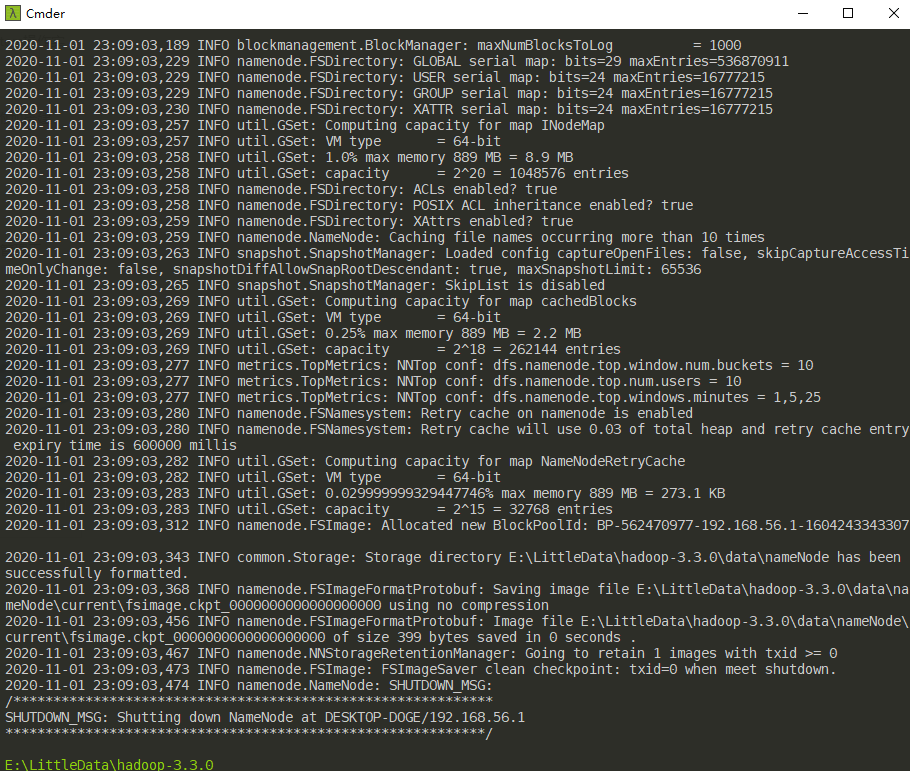
格式化namenode完毕后,切换至$HADOOP_HOME/sbin目录下,执行start-all.cmd脚本:

这里命令行会提示start-all.cmd脚本已经过期,建议使用start-dfs.cmd和start-yarn.cmd替代。同理,如果执行stop-all.cmd也会有类似的提示,可以使用stop-dfs.cmd和stop-yarn.cmd替代。start-all.cmd成功执行后,会拉起四个JVM实例(见上图中的Shell窗口自动新建了四个Tab),此时可以通过jps查看当前的JVM实例:
> jps
结果:
19408 ResourceManager
16324 NodeManager
14792 Jps
15004 NameNode
2252 DataNode
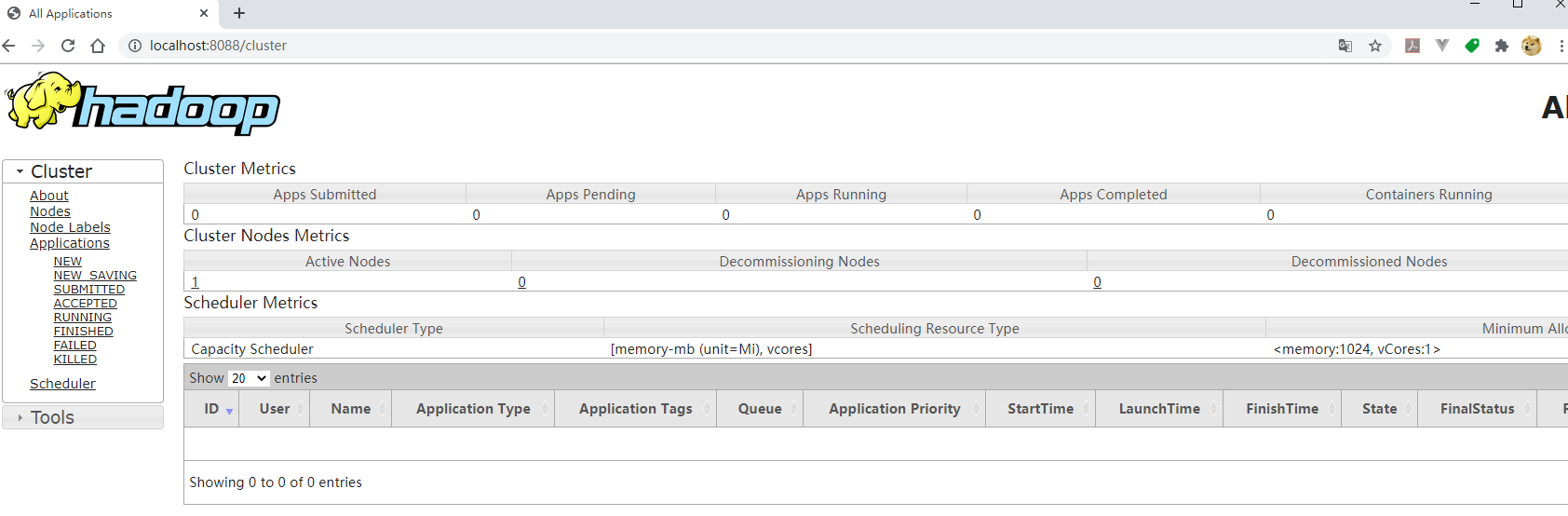
可见已经启动了ResourceManager、NodeManager、NameNode和DataNode四个应用,至此Hadoop的单机版已经启动成功。通过stop-all.cmd命令退出这四个进程。可以通过http://localhost:8088/查看调度任务的状态:
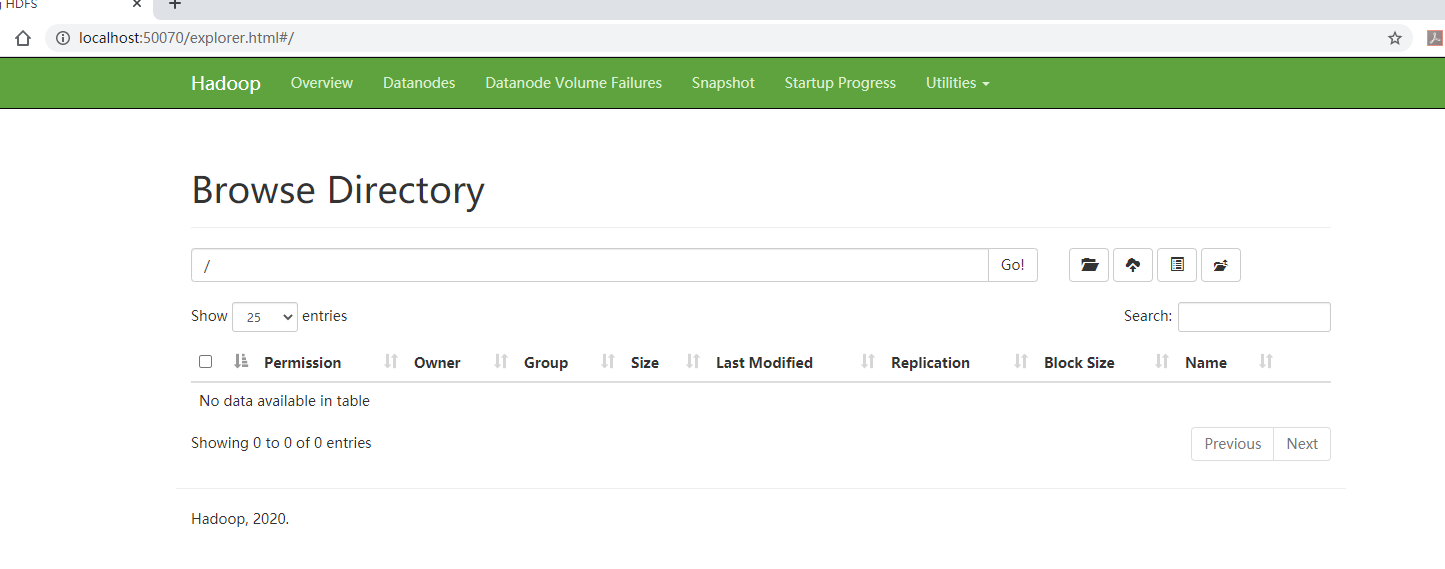
通过http://localhost:50070/去查看HDFS的状态和文件:
重启Hadoop的办法:先执行stop-all.cmd脚本,再执行start-all.cmd脚本。
配置和启动Hive
Hive是构筑于HDFS上的,所以务必确保Hadoop已经启动。Hive在HDFS中默认的文件路径前缀是/user/hive/warehouse,因此可以先通过命令行在HDFS中创建此文件夹:
hdfs dfs -mkdir /user/hive/warehouse -p
hdfs dfs -chmod -R 777 /user/hive/warehouse
同时需要通过下面的命令创建并为tmp目录赋予权限:
hdfs dfs -mkdir /tmp
hdfs dfs -chmod -R 777 /tmp
在系统变量中添加HIVE_HOME,具体的值配置为D:\hadoop\apache-hive-3.1.2-bin,同时在Path变量添加%HIVE_HOME%\bin;,跟之前配置HADOOP_HOME差不多。下载和拷贝一个mysql-connector-java-8.0.x.jar 或 postgresql-42.3.3.jar到$HIVE_HOME/lib目录下:
创建Hive的配置文件,在$HIVE_HOME/conf目录下已经有对应的配置文件模板,需要拷贝和重命名,具体如下:
$HIVE_HOME/conf/hive-default.xml.template => $HIVE_HOME/conf/hive-site.xml
$HIVE_HOME/conf/hive-env.sh.template=>$HIVE_HOME/conf/hive-env.sh$HIVE_HOME/conf/hive-exec-log4j.properties.template=>$HIVE_HOME/conf/hive-exec-log4j.properties$HIVE_HOME/conf/hive-log4j.properties.template=>$HIVE_HOME/conf/hive-log4j.properties
修改hive-env.sh脚本,在尾部添加下面内容:
export HADOOP_HOME=D:\hadoop\hadoop-3.3.0
export HIVE_CONF_DIR=D:\hadoop\apache-hive-3.1.2-bin\conf
export HIVE_AUX_JARS_PATH=D:\hadoop\apache-hive-3.1.2-bin\lib
修改hive-site.xml文件,主要修改下面的属性项:
| 属性名 | 属性值 | 备注 |
|---|---|---|
hive.metastore.warehouse.dir |
/user/hive/warehouse |
Hive的数据存储目录,这个是默认值 |
hive.exec.scratchdir |
/tmp/hive |
Hive的临时数据目录,这个是默认值 |
javax.jdo.option.ConnectionURL |
jdbc:postgresql://localhost:5432/hive | Hive元数据存放的数据库连接,如果是PGSQL则修改对应驱动 |
javax.jdo.option.ConnectionDriverName |
org.postgresql.Driver | Hive元数据存放的数据库驱动,如果是PGSQL则修改对应驱动 |
javax.jdo.option.ConnectionUserName |
root |
Hive元数据存放的数据库用户 |
javax.jdo.option.ConnectionPassword |
root |
Hive元数据存放的数据库密码 |
hive.exec.local.scratchdir |
D:\hadoop\apache-hive-3.1.2-bin/data/scratchDir | 创建本地目录$HIVE_HOME/data/scratchDir |
hive.downloaded.resources.dir |
D:\hadoop\apache-hive-3.1.2-bin/data/resourcesDir | 创建本地目录$HIVE_HOME/data/resourcesDir |
hive.querylog.location |
D:\hadoop\apache-hive-3.1.2-bin/data/querylogDir | 创建本地目录$HIVE_HOME/data/querylogDir |
hive.server2.logging.operation.log.location |
D:\hadoop\apache-hive-3.1.2-bin/operationDir | 创建本地目录$HIVE_HOME/data/operationDir |
hive.metastore.schema.verification |
false |
可选 |
hive.server2.enable.doAs |
false | 不加会遇到『user root cannot impersonate anonymous』,则要等待重连 |
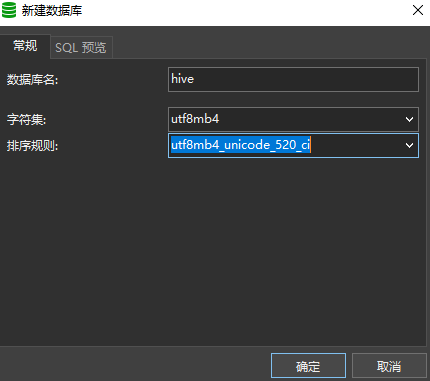
修改完毕之后,在本地的MySQL服务新建一个数据库hive,编码和字符集可以选用范围比较大的utf8mb4(虽然官方建议是latin1,但是字符集往大范围选没有影响):
上面的准备工作做完之后,可以进行Hive的元数据库初始化,在$HIVE_HOME/bin目录下执行下面的脚本:
hive.cmd --service schematool -dbType postgres -initSchema
这里有个小坑,hive-site.xml文件的第3215行有个神奇的无法识别的符号:

此无法识别符号会导致Hive的命令执行异常,需要去掉。当控制台输出Initialization script completed schemaTool completed的时候,说明元数据库已经初始化完毕:
此无法识别符号会导致Hive的命令执行异常,需要去掉。当控制台输出Initialization script completed schemaTool completed的时候,说明元数据库已经初始化完毕:
在$HIVE_HOME/bin目录下,通过hive.cmd可以连接Hive(关闭控制台即可退出):
> hive.cmd
尝试创建一个表t_test:
hive> create table t_test(id INT,name string);
hive> show tables;
查看http://localhost:50070/确认t_test表已经创建成功。
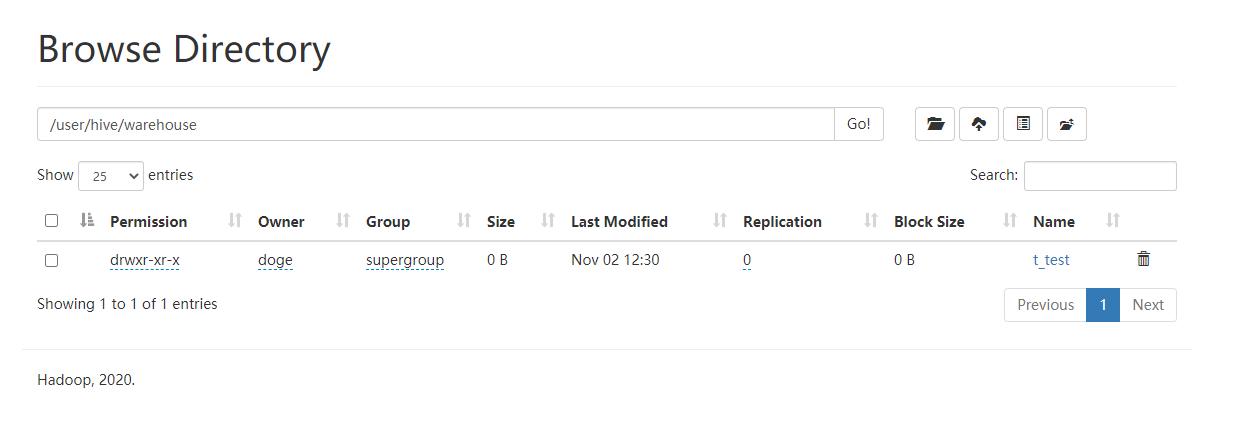
尝试执行一个写入语句和查询语句:
hive> insert into t_test(id,name) values(1,'throwx');
hive> select * from t_test;
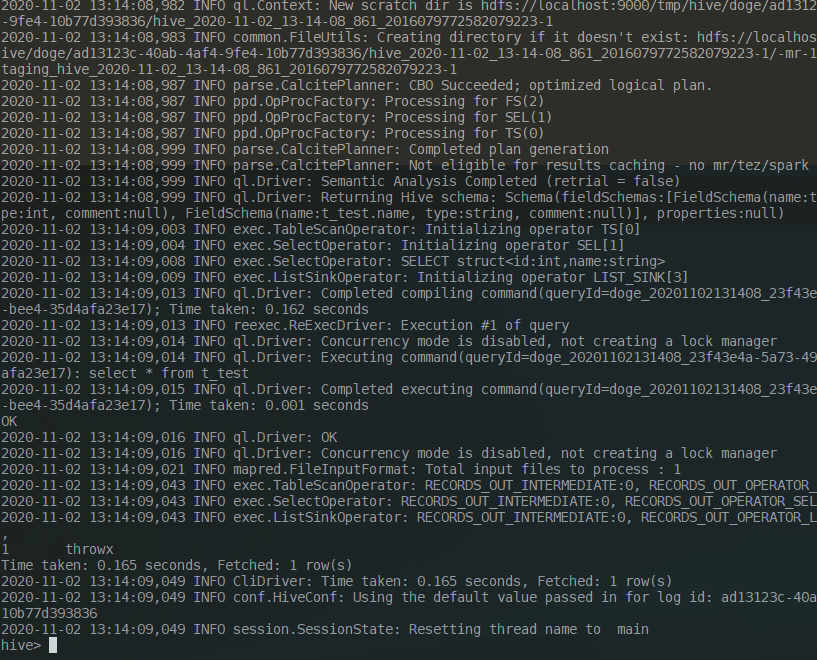
写用了30多秒,读用了0.165秒。
使用DBeaver连接Hive
HiveServer2是Hive服务端接口模块,必须启动此模块,远程客户端才能对Hive进行数据写入和查询。目前,此模块还是基于Thrift RPC实现,它是HiveServer的改进版,支持多客户端接入和身份验证等功能。配置文件hive-site.xml中可以修改下面几个关于HiveServer2的常用属性:
| 属性名 | 属性值 | 备注 |
|---|---|---|
hive.server2.thrift.min.worker.threads |
5 |
最小工作线程数,默认值为5 |
hive.server2.thrift.max.worker.threads |
500 |
最大工作线程数,默认值为500 |
hive.server2.thrift.port |
10000 |
侦听的TCP端口号,默认值为10000 |
hive.server2.thrift.bind.host |
127.0.0.1 |
绑定的主机,默认值为127.0.0.1 |
hive.execution.engine |
mr |
执行引擎,默认值为mr |
在$HIVE_HOME/bin目录下执行下面的命令可以启动HiveServer2:
hive.cmd --service hiveserver2
hiveserver2启动完毕后,通过DBeaver创建连接:
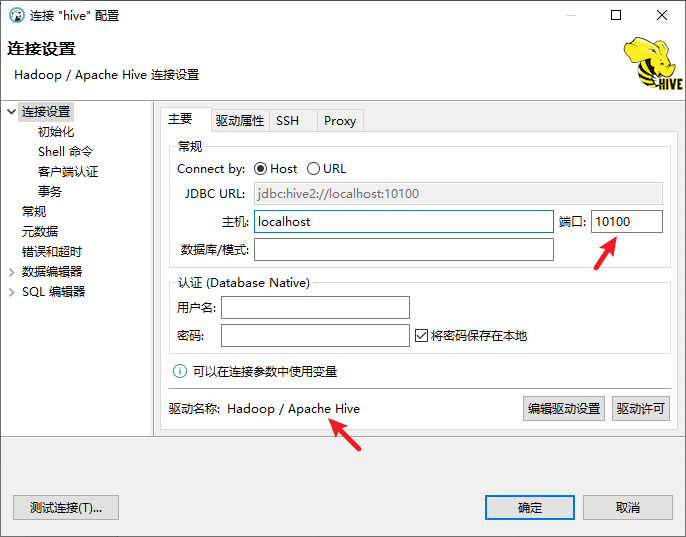
可能遇到的问题
下面小结一下可能遇到的问题。
hadoop查看版本失败
由于JAVA_HOME的路径中存在空格导致。解决方法:移动JDK位置到没有空格的目录
Java虚拟机启动失败
目前定位到是Hadoop无法使用JDK[9+的任意版本JDK,建议切换为任意JDK8的小版本。
出现找不到Hadoop执行文件异常
确保已经把winutils中的hadoop-3.3.0\bin目录下的hadoop.dll和winutils.exe文件拷贝到Hadoop的解压目录的bin文件夹中。
start-all.cmd脚本执行时有可能出现找不到批处理脚本的异常。此问题在公司的开发机出现过,在家用的开发机没有重现,具体解决方案是在start-all.cmd脚本的首行加入cd $HADOOP_HOME,如cd E:\LittleData\hadoop-3.3.0。
无法访问localhost:50070
一般是因为hdfs-site.xml配置遗漏了dfs.http.address配置项,添加:
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
然后调用stop-all.cmd,再调用start-all.cmd重启Hadoop即可。
Hive连接MySQL异常
注意MySQL的驱动包是否已经正确拷贝到$HIVE_HOME/lib下,并且检查javax.jdo.option.ConnectionURL等四个属性是否配置正确。如果都正确,注意是否MySQL的版本存在问题,或者服务的版本与驱动版本不匹配。
Hive找不到批处理文件
一般描述是'xxx.cmd' is not recognized as an internal or external command...,一般是Hive的命令执行时的异常,需要把Hive 1.x的源码包的bin目录下的所有.cmd脚本拷贝到$HIVE_HOME/bin对应的目录下。
文件夹权限问题
常见如CreateSymbolicLink异常,会导致Hive无法使用INSERT或者LOAD命令写入数据。出现这类问题可以通过下面方式解决:
Win + R然后运行gpedit.msc- 计算机设置 -Windows设置 — 安全设置 - 本地策略 - 用户权限分配 - 创建符号链接 - 添加当前用户。
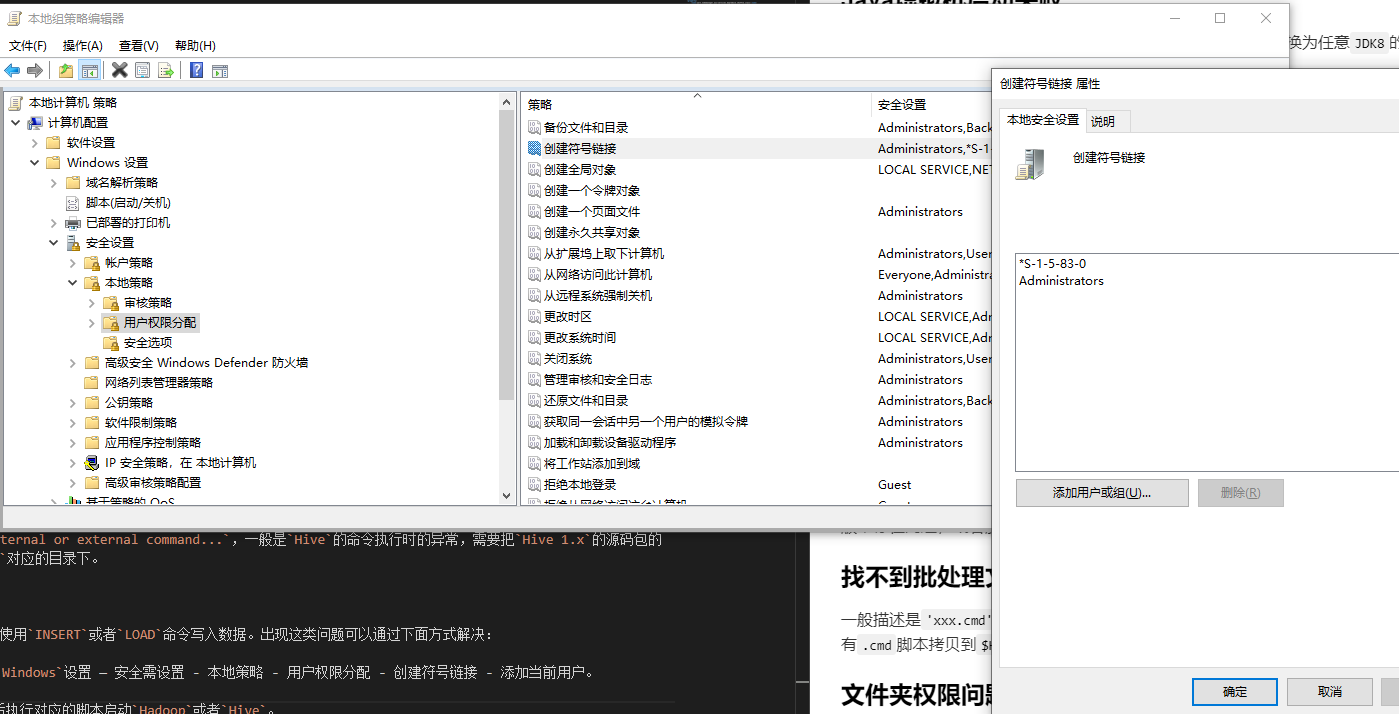
或者直接使用管理员账号或者管理员权限启动CMD,然后执行对应的脚本启动Hadoop或者Hive。
SessionNotRunning异常
启动HiveServer2中或者外部客户端连接HiveServer2时候有可能出现此异常,具体是java.lang.ClassNotFoundException: org.apache.tez.dag.api.TezConfiguration的异常。解决方案是:配置文件hive-site.xml中的hive.execution.engine属性值由tez修改为mr,然后重启HiveServer2即可。因为没有集成tez,重启后依然会报错,但是60000ms后会自动重试启动(一般重试后会启动成功):
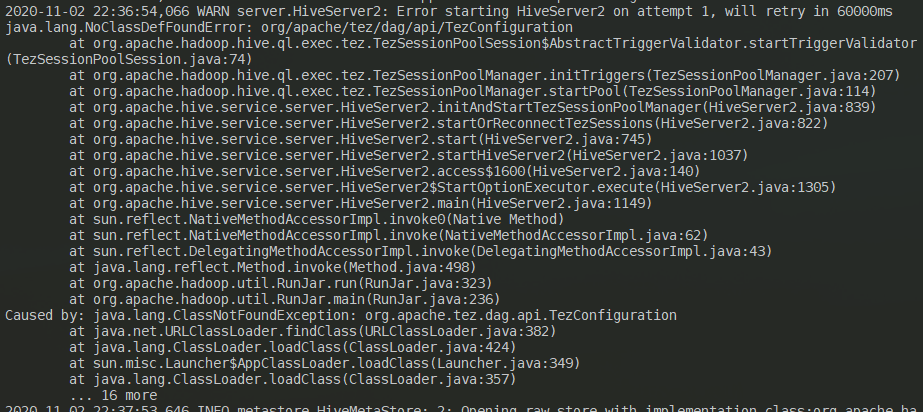
这算是一个遗留问题,但是不影响客户端正常连接,只是启动时间会多了60秒。
HiveServer2端口冲突
修改配置文件hive-site.xml中的hive.server2.thrift.port属性值为未被占用的端口,重启HiveServer2即可。
数据节点安全模式异常
一般是出现SafeModeException异常,提示Safe mode is ON。通过命令hdfs dfsadmin -safemode leave解除安全模式即可。
AuthorizationException
常见的是Hive通过JDBC客户端连接HiveServer2服务时候会出现这个异常,具体是信息是:User: xxx is not allowed to impersonate anonymous。这种情况只需要修改Hadoop的配置文件core-site.xml,添加:
<property>
<name>hadoop.proxyuser.xxx.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.xxx.groups</name>
<value>*</value>
</property>
这里的xxx是指报错时候具体的系统用户名,例如笔者开发机的系统用户名为doge
然后重启Hadoop服务即可。
MapRedTask的权限问题
常见的是Hive通过JDBC客户端连接HiveServer2服务执行INSERT或者LOAD操作时候抛出的异常,一般描述为:Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Permission denied: user=anonymous, access=EXECUTE, inode="/tmp/hadoop-yarn":xxxx:supergroup:drwx------。
解决方法:
通过命令hdfs dfs -chmod -R 777 /tmp赋予匿名用户/tmp目录的读写权限即可。
CreateSymbolicLink error (1314)
通过管理员cmd执行sbin\start-all.cmd,再不行则:
- run Command Prompt in admin mode
- execute etc\hadoop\hadoop-env.cmd
- run sbin\start-dfs.cmd
- run sbin\start-yarn.cmd
- now try to run your job
其他问题排查
# 读取yarn application日志
yarn application -status application_1496499143480_0003
# 读取 container 日志
yarn container -status container_1681451043876_0001_02_000001
INFO ipc.Client: Retrying connect to server的问题
把host文件的 0.0.0.0 的域名映射移除
小结
没什么事最好还是直接在Linux或者Unix系统中搭建Hadoop和Hive的开发环境比较合理,Windows系统的文件路径和权限问题会导致很多意想不到的问题。本文参考了大量互联网资料和Hadoop和Hive的入门书籍,这里就不一一贴出,站在巨人的肩膀上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号