
性能TPS 瓶颈定位
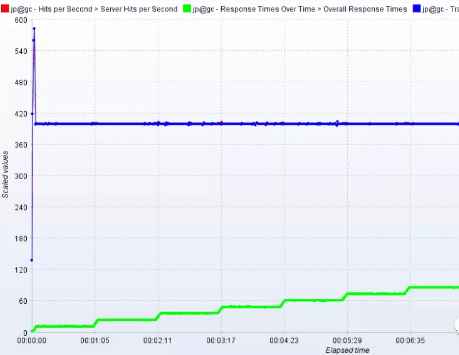
100并发用户下的负载测试,TPS最大升到570左右,然后跌到400,并且长期保持。加线程也不能让tps再有所增加
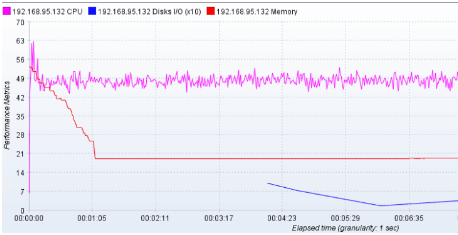
从监听到的服务器指标来看,cpu利用率一直处于低迷的状态,大约只有40%左右。
问题定位
执行 vmstat 1 10
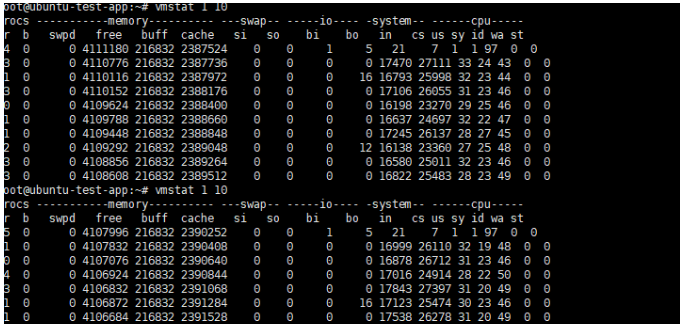
可以观察到,运行队列不是很长,iowait不高,没有swap切换,但是上下文切换和中断似乎有点偏高
执行mpstat -P ALL 1
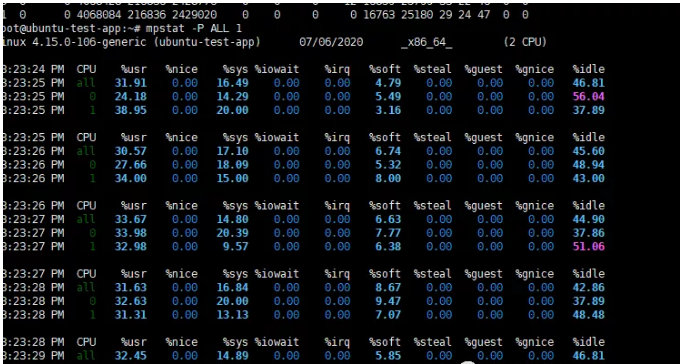
可以很明显的观察到软中断有点偏高,用户空间的cpu利用率大约是系统空间的两倍。
接下来 执行 watch -d cat /proc/interrupts
分析一下是什么导致的软中断过高
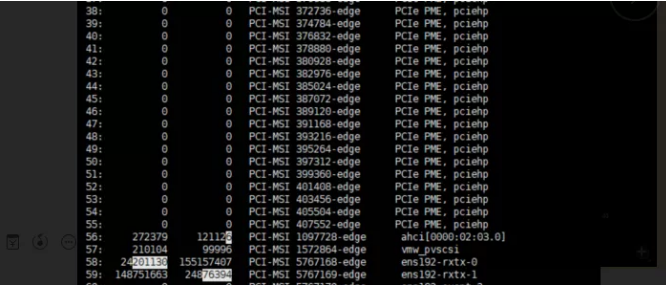
可以发现中断频率最高的两个网卡和vmw服务。有可能是网络出现了故障,但是vmw是什么暂时未知
执行*netstat -n | awk '/tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' *,查看一下timewait有多少
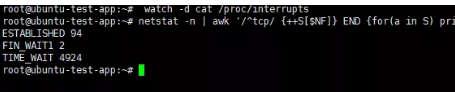
4900多timewait,偏高。
接下来重头戏,需要拦截一下系统进程,看一下系统内部到底在做什么导致的切换和中断过高
执行** strace -o strace.log -tt -p 29779**
这条命令生成了一个进程日志,从日志里面可以看出一些问题
1:系统内部写日志的时候没有权限,出现了反复读写的死循环
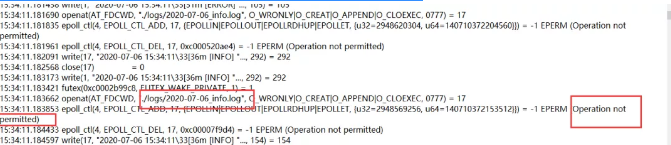
2:大量的tcp连接超时
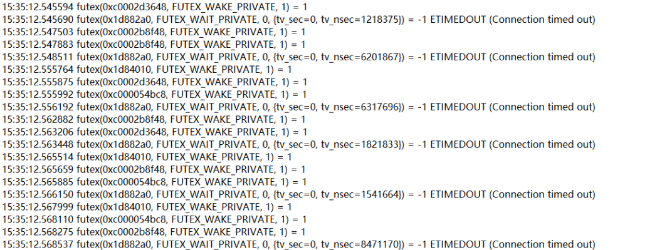
问题大致明白了。因为系统反复写日志不成功,导致内核频繁的上下文切换;因为tcp连接故障导致的系统频繁中断
解决问题
1:调整tcp的keepalive时间,从1200加到了3000
2:增加tcp缓冲和内存共享
3:日志问题开发暂时不想解决
结果
tcp调整之后,最大tps增加到了650左右,但是还是会掉到420。因为上下文切换过快导致了cpu无法正常工作,所以tps无法从根本上提升

 浙公网安备 33010602011771号
浙公网安备 33010602011771号