现代CPU调优2性能测量
2 性能测量
要了解应用程序的性能,第一步就是对其进行衡量。任何关心性能评估的人都可能知道,有时进行公平的性能测量并从中得出准确的结论是多么困难。性能测量可能会非常出人意料,而且有违直觉。更改源代码中看似无关的部分,可能会对程序性能产生重大影响,让我们大吃一惊。由于各种原因,测量结果可能会持续高估或低估真实性能,从而导致结果失真,无法准确反映实际情况。这种现象被称为测量偏差。
与大多数功能问题相比,性能问题往往更难重现,也更难找出根本原因。程序的每次运行通常在功能上是相同的,但从性能角度看却有些不同。例如,在解压压缩文件时,我们会一次又一次地得到相同的结果,这意味着这一操作是可重现的。但是,我们不可能重现这一操作在 CPU 上的逐周期性能曲线。
要获得准确而有意义的结果,进行公平的性能实验是必不可少的一步。您需要确保您关注的问题是正确的,而不是在调试一些无关的问题。设计性能测试和配置环境都是性能评估过程中的重要组成部分。
由于存在测量偏差,性能评估通常会涉及统计方法,而这些方法本身就值得写一整本书。在这一领域,有许多棘手的案例和大量的研究工作。我们不会深入探讨绩效衡量评估的统计方法。相反,我们只讨论高层次的想法,并提供基本的指导。我们鼓励您自行深入研究。
在本章中,我们将
- 简要介绍现代系统产生噪声性能测量结果的原因,以及可以采取的措施。
- 解释在生产部署中测量性能的重要性。
- 就如何正确收集和分析性能测量结果提供一般性指导。
- 探讨如何在实施代码库变更时自动检测性能衰退。
- 介绍开发人员在基于时间的测量中可以使用的软件和硬件计时器。
- 讨论如何编写优秀的微基准,以及在编写过程中可能遇到的一些常见陷阱。
2.1 现代系统中的噪声
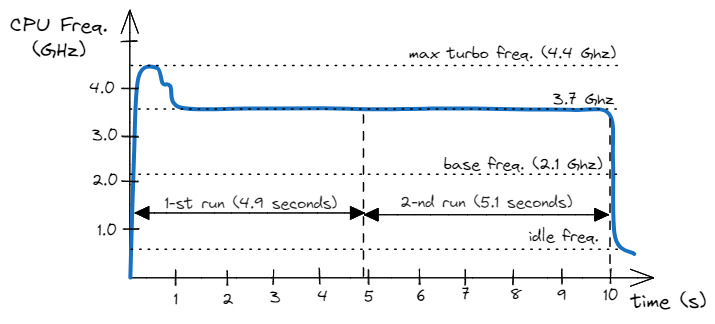
硬件和软件中有许多旨在提高性能的功能,但并非所有功能都具有确定性行为。例如动态频率扩展(DFS Dynamic Frequency Scaling),它允许 CPU 将频率提升到远远高于基本频率的水平,从而大幅提高运行速度。DFS 也经常被称为涡轮增压模式。遗憾的是,CPU 不能长时间处于涡轮增压模式,否则可能面临过热的风险。因此,一段时间后,CPU 会降低频率,以保持在热限制范围内。DFS 通常在很大程度上取决于当前的系统负载和核心温度等外部因素,因此很难预测其对性能测量的影响。下图显示了 DFS 可能导致性能差异的典型示例。在我们的方案中,我们在一个 “冷 ”处理器上紧接着运行了两次基准测试。在第一秒中,基准的第一次迭代以 4.4 GHz 的最大涡轮频率运行,但随后 CPU 不得不将频率降至 4 GHz 以下。第二次运行没有提升 CPU 频率的优势,也没有进入涡轮增压模式。尽管我们两次运行的基准测试版本完全相同,但运行环境却不尽相同。正如您所看到的,第一次运行比第二次运行快 200 毫秒,这是因为第一次运行时 CPU 频率较高。
即使运行 Windows 任务管理器或 Linux top程序也会影响测量结果,因为额外的 CPU 内核将被激活并分配给它。这可能会影响运行实际基准的内核频率。噪声也可能来自软件。考虑对 git status 命令进行基准测试,该命令会访问磁盘上的许多文件。在这种情况下,文件系统对性能的影响很大,尤其是文件系统缓存。第一次运行时,文件系统缓存中缺少所需的条目。文件系统缓存失效,我们的 git status 命令运行得非常慢。不过,第二次运行时,文件系统缓存已经预热,运行速度会比第一次快很多。
您可能会考虑在测量前进行一次模拟运行。这当然有帮助,但不幸的是,测量偏差也会在运行过程中持续存在。Mytkowicz 等人,2009 年的论文表明,UNIX 环境大小(即存储环境变量所需的字节总数)或链接顺序(提供给链接器的对象文件的顺序)会以不可预测的方式影响性能。内存布局影响性能测量的其他方式还有很多。要获得一致的性能,需要在相同的条件下运行基准的所有迭代。要在每次运行基准时获得 100% 一致的结果是不可能的,但通过仔细控制环境或许可以接近。消除系统中的非确定性有助于进行定义明确、稳定的性能测试,例如微基准测试。
考虑这样一种情况:您实施了代码变更,并希望通过对程序的 “之前 ”和 “之后 ”版本进行基准测试来了解相对加速比。在这种情况下,您可以控制系统中的大部分可变因素,包括硬件配置、操作系统设置、后台进程等。禁用对性能有非确定性影响的功能将有助于获得更一致、更准确的对比结果。您可以在附录 A 中找到此类功能的示例以及禁用方法。此外,有一些工具可以设置环境以确保基准测试结果的差异较小;temci 就是这样一种工具。
不过,要复制完全相同的环境并完全消除偏差是不可能的:可能存在不同的温度条件、电力传输峰值、意外系统中断等。追寻系统中所有潜在的噪声和变化源可能是一个永无止境的过程。例如,在对大型分布式云服务进行基准测试时,有时就无法做到这一点。
当您想测量变更对真实世界性能的影响时,您不应该排除系统的非确定性行为。没错,这些功能可能会导致性能不稳定,但它们的目的是提高系统的整体性能。您应用程序的用户很可能会启用这些功能来提供更好的性能。因此,在分析生产应用程序的性能时,应尽量复制目标系统配置,并对其进行优化。在系统中引入任何人为调整都会改变结果,使其与用户的结果大相径庭。
2.2 衡量生产环境性能
当应用程序在共享基础架构(如公共云)中运行时,通常会有来自其他客户的工作负载在同一台服务器上运行。随着虚拟化和容器等技术的普及,公共云提供商会尽量充分利用其服务器的容量。不幸的是,这给在这样的环境中衡量性能带来了额外的障碍。当您的应用程序与相邻进程共享资源时,其性能可能会变得非常难以预测。
通过在实验室中重现特定场景来分析生产工作负载可能相当棘手。有时,“内部 ”性能测试不可能重现确切的行为。这就是云提供商和超大规模提供商提供直接在生产系统上监控性能的工具的原因。在实验室环境中表现良好的代码变更不一定在生产环境中表现良好。请咨询您的云服务提供商,了解如何对生产实例进行性能监控。我们将在第 7.9 节概述连续剖析器。
大型服务提供商实施遥测系统来监控用户设备的性能已成为一种趋势。Netflix Icarus遥测服务就是这样一个例子,它运行在遍布全球的数千台不同设备上。这种遥测系统有助于 Netflix 了解用户对 Netflix 应用程序性能的看法。它使 Netflix 工程师能够分析从许多设备上收集到的数据,并发现原本不可能发现的问题。通过这类数据,可以做出更明智的决策,确定优化工作的重点。
监控生产部署的一个重要注意事项是测量开销。由于任何类型的监控都会影响运行服务的性能,因此我们建议使用轻量级剖析方法。根据 Ren 等人,2010:
“要在提供真实流量的数据中心机器上进行连续剖析,极低的开销至关重要。通常情况下,可接受的总开销应低于 1%。性能监控开销可通过限制剖析机器集和减少数据样本捕获频率来降低。
2.3 持续基准测试
我们刚刚讨论了为什么要监控生产过程中的性能。另一方面,尽管并非所有的性能退步都能在实验室中发现,但建立持续的 “内部 ”测试以尽早发现性能问题仍是有益的。软件供应商不断寻求加快向市场交付产品速度的方法。许多公司每隔几个月或几周就会部署新编写的代码。性能缺陷往往会以惊人的速度泄漏到生产软件中Jin 等人,2012。大量代码变更给彻底分析其性能影响带来了挑战。
性能衰退是指使软件运行速度慢于前一版本的缺陷。要捕捉性能性能衰退,就必须检测改变程序性能的提交。从数据库系统到搜索引擎再到编译器,几乎所有大型软件系统在其不断演进和部署的生命周期中都会遇到性能衰退的问题。在软件开发过程中,要完全避免性能衰退可能是不可能的,但通过适当的测试和诊断工具,可以大大降低此类缺陷无声无息地渗入生产代码的可能性。
使用图表(如下图所示)跟踪应用程序的性能非常有用。使用这种图表,您可以看到历史趋势,并找到性能提高或降低的时刻。通常情况下,您可以为跟踪的每项性能测试设置单独的一行。不要在单个图表中包含太多基准,否则会造成很大干扰。
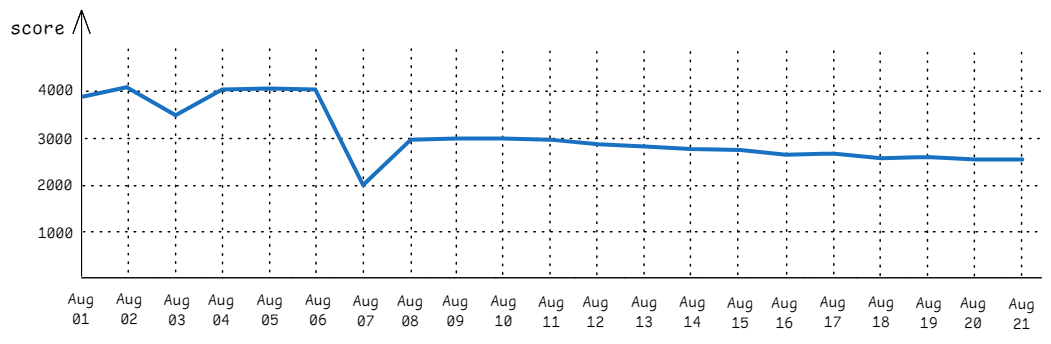
让我们考虑一下检测性能下降的潜在解决方案。我想到的第一个方案是:让人查看图表。大家很可能会捕捉到 8 月 7 日发生的性能倒退,但并不能明显地发现后来出现的较小的性能倒退。人往往会很快失去注意力,可能会错过衰退,尤其是在繁忙的图表上。此外,这是一项耗时而枯燥的工作,必须每天进行。
8 月 3 日还有一次有趣的性能下降。开发人员很可能也会发现这一点,但是,我们大多数人都会不屑一顾,因为第二天性能就恢复了。但我们能确定这只是测量中的一个小故障吗?
如果这是一次真正的回归,而 8 月 4 日的优化弥补了这一回归呢?如果我们能修复回归并保留优化,我们的性能分数就会达到 4500 左右。不要忽视这种情况。一种方法是在 8 月 2 日至 8 月 4 日重复测量,并检查这期间的代码变化。
第二种方法是设定一个阈值,例如 2%。所有性能在该阈值范围内的代码修改都被视为噪音,而所有超过阈值的修改都被视为回归。这比第一种方案要好一些,但仍有其自身的缺点。性能测试中的波动是不可避免的:有时,即使是无伤大雅的代码修改也会引发基准性能的变化。为阈值选择一个合适的值非常困难,而且不能保证低误报率和低误报率。阈值设置过低可能会导致分析出一堆并非由源代码变化而是由随机噪声引起的小回归。阈值设置过高可能会导致过滤掉真正的性能回归。小的性能退步可能会慢慢堆积成更大的性能退步,从而被忽视。
从 8 月 11 日到 8 月 21 日的下降趋势。这一时期以 3000 分开始,以 2600 分结束。这大约是 10 天内 15%的衰退,平均每天 1.5%。如果我们设置 2% 的阈值,所有的回归都会被过滤掉。但是,正如我们所看到的,累积的回归幅度远远大于阈值。
尽管如此,这个选项对很多项目来说还是很有效的,尤其是当基准中的噪音水平很低时。此外,您还可以调整每个测试的阈值。Chromium 项目中的 LUCI26 就是一个持续集成 (CI) 系统的例子,在该系统中,每个测试都需要设置明确的阈值,以提醒出现回归。
值得一提的是,长期跟踪性能结果要求您保持用于运行基准的机器配置不变。更改配置可能会使之前的所有性能结果失效。您可以决定使用新配置重新收集所有历史测量结果,但这样做的成本很高。
最近流行的另一种方法是使用统计方法来识别性能回归。它利用一种名为 “变化点检测 ”的算法(CPD, see Matteson & James, 2014)的算法,该算法利用历史数据识别性能发生变化的时间点。许多性能监控系统都采用了 CPD(Change Point Detection) 算法,包括几个开源项目。您可以在网上搜索,找到更适合您需要的算法。
CPD 的显著优点是无需设置阈值。该算法会评估一个大窗口中的近期结果,这样就可以将异常值视为噪音而忽略不计,从而减少误报。CPD 的缺点是缺乏即时反馈。例如,考虑一个性能测试,其运行时间的历史测量值如下:5 秒、6 秒、5 秒、5 秒、7 秒。如果下一个基准结果出现在 11 秒,那么很可能会超过阈值,并立即生成警报。但是,在使用 CPD 算法的情况下,此时不会采取任何措施。如果在下一次运行中,性能恢复到 5 秒,那么它可能会将其视为误报,而不会生成警报。相反,如果下一两次运行的结果分别是 10 秒和 12 秒,CPD 算法才会触发警报。
对于哪种方法更好,没有明确的答案。如果您的开发流程需要即时反馈,例如在拉取请求被合并之前对其进行评估,那么使用阈值是更好的选择。此外,如果您能消除系统中的大量噪音,并获得稳定的性能结果,那么使用阈值会更合适。在一个非常安静的系统中,前面提到的 11 秒测量结果很可能预示着真正的性能下降,因此我们需要尽早标记它。相反,如果系统中存在大量噪音,例如运行分布式宏基准,那么 11 秒的结果可能只是一个假阳性。在这种情况下,您最好使用变化点检测。
典型的 CI 性能跟踪系统应自动执行以下操作:
-
- 设置被测系统。
-
- 运行基准套件。
-
- 报告结果
-
- 确定性能是否发生变化。
-
- 对性能的意外变化发出警报。
-
- 将结果可视化,以便人工分析。
CI 性能跟踪系统的另一个理想功能是允许开发人员在将补丁提交到代码库之前提交性能评估工作。这大大简化了开发人员的工作,有利于加快实验周转。代码更改对性能的影响经常被列入签入标准列表。
如果由于某种原因,代码库中出现了性能退步,及时发现是非常重要的。首先,因为在它发生后,合并的变更较少。这样,我们就可以让负责回归的人员在转到其他任务之前对问题进行检查。此外,开发人员在处理回归问题时也会容易得多,因为他们对所有细节都记忆犹新,而不是在几周之后。
最后,CI 系统不仅要对软件性能回归发出警报,还要对意外的性能改进发出警报。例如,有人可能会签入一个看似无害的提交,但却在自动跟踪工具中将性能提高了 10%。您最初的本能可能是庆祝这一偶然的性能提升,然后继续一天的工作。然而,虽然这次提交可能通过了 CI 管道中的所有功能测试,但这次意外的改进很可能发现了功能测试中的漏洞,而这个漏洞只会在性能回归结果中体现出来。例如,该变更导致应用程序跳过了功能测试未涵盖的部分工作。这种情况经常发生,因此有必要明确提及:将自动化性能回归工具作为整体软件测试框架的一部分。
最后,我们强烈建议建立一个自动化性能统计跟踪系统。尝试使用不同的算法,看看哪种算法最适合您的应用程序。这当然需要时间,但这将是对项目未来性能健康的可靠投资。
2.4 手动性能测试
在上一节中,我们讨论了 CI 系统如何帮助评估代码变更对性能的影响。然而,由于硬件不可用、测试基础架构设置过于复杂、需要收集额外指标等原因,并不总能利用此类系统。在本节中,我们将为本地性能评估提供基本建议。
我们通常通过以下方法来衡量代码变更对性能的影响:1)衡量基线性能;2)衡量修改后程序的性能;3)相互比较。例如,我们有一个递归计算斐波那契数字的程序(基线),我们决定用一个循环重写它(修改后)。两个版本在功能上都是正确的,并产生了相同的斐波纳契数。现在,我们需要比较两个版本程序的性能。
强烈建议不要只进行一次测量,而是多次运行基准。如果只根据一次测量结果进行比较,就会增加我们在第 2.1 节中讨论过的测量偏差带来的数字偏差风险。因此,我们为基线程序收集了 N 个性能测量值,为修改版程序收集了 N 个测量值。我们将一组性能测量值称为性能分布。现在,我们需要汇总并比较这两个分布,以确定哪个版本的程序速度更快。
比较两个性能分布的最直接方法是取两个分布中 N 个测量值的平均值,然后计算比率。对于我们在本书中讨论的代码改进类型,这种简单的方法在大多数情况下都很有效。然而,性能分布的比较是非常微妙的,有很多方法可以让你被测量结果所迷惑,从而得出错误的结论。我们将不再赘述统计分析的细节,而是建议您阅读相关教科书。Dror G. Feitelson 所著的《计算机系统性能评估的工作量建模》是专门针对性能工程师的一本很好的参考书,其中包含更多关于模态分布、偏斜度和其他相关主题的信息。
数据科学家通常通过绘图来展示测量结果。这样可以避免得出有偏差的结论,并让读者自行解释数据。绘制分布图的常用方法之一是使用箱线图。下图中我们将同一功能程序的两个版本(“之前 ”和 “之后”)的性能分布可视化。每个分布中有 70 个性能数据点。
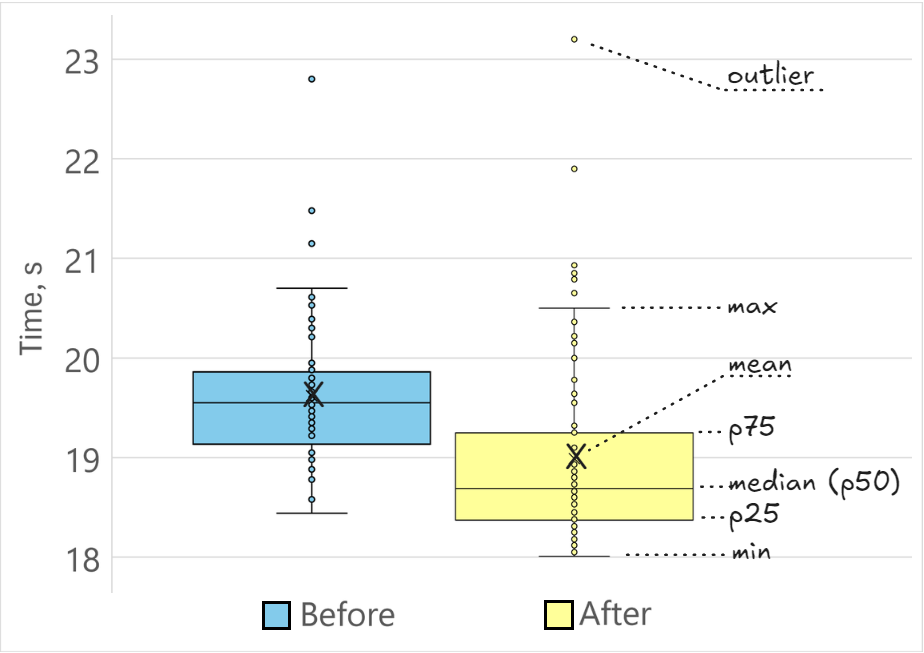
让我们来描述一下图中的术语:
- 平均数(mean,通常称为average)是数据集中所有数值的总和除以数值的个数。用 X 表示。
- 中位数(median)是数据集中数值排序后的中间值。与 50 百分位数(p50)相同。
- 第 25 百分位数 (p25)
- 第 75 百分位数 (p75)
- 离群值(outlier)是指与数据集中其他样本有显著差异的数据点。离群值可能是由数据的可变性或实验误差造成的。
- 最小值和最大值(whiskers)代表最极端的数据点,不被视为异常值。
通过图中的方框图,我们可以感觉到代码更改对性能产生了积极影响,因为 “更改后 ”的样本通常比 “更改前 ”的样本更快。不过,也有一些 “之前 ”的测量结果比 “之后 ”的快。箱形图允许在同一图表上对多个分布进行比较。Stefan Marr 在一篇博文中介绍了使用盒图可视化性能分布的好处。
在某些情况下,您可以使用其他指标来计算加速度,包括中位数、最小值和第 95 百分位数,具体取决于哪个指标更能代表您的分布。
标准差可以量化数据集中的值平均偏离均值的程度。标准差小表示数据点接近平均值,标准差大表示数据点分布范围更广。除非分布具有较低的标准差,否则不要计算加速度。如果测量值的标准偏差与平均值的数量级相同,那么平均值就不是一个有代表性的指标。考虑采取措施减少测量中的噪音。如果无法做到这一点,则以平均值、中位数、标准偏差、百分位数、最小值、最大值等关键指标的组合来表示结果。
性能提升通常有两种表现形式:加速因子或百分比提升。如果一个程序原本需要 10 秒运行,而你将其优化为 1 秒,这就是 10 倍的速度提升。我们从原来的程序中减少了 9 秒的运行时间,也就是减少了 90% 的时间。计算改进百分比的公式如下所示。在本书中,我们将同时使用这两种方法来表示速度提升: 加速百分比 = (1 - 新时间/旧时间 ) × 100%。
要计算准确的加速比,最重要的因素之一是收集丰富的样本,即大量运行基准。这听起来似乎显而易见,但并非总能实现。例如,一些 SPEC CPU 2017 基准 在现代机器上运行时间超过 10 分钟。这意味着仅制作三个样本就需要 1 个小时: 每个版本的程序需要 30 分钟。试想一下,您的套件中不仅有一个基准,还有数百个基准。即使将工作分配到多台机器上,要收集统计上足够的数据也会变得非常昂贵。
如果获取新的测量结果成本高昂,就不要急于收集大量样本。通常情况下,只需运行三次,就能学到很多东西。如果这三个样本的标准偏差很低,那么收集更多的测量结果可能也不会有什么新的收获。这在具有基本一致性的程序(如静态基准)中非常典型。但是,如果您发现标准偏差异常高,我不建议您启动新的运行并希望获得 “更好的统计数据”。您应该找出导致性能差异的原因以及如何减少差异。
在自动化设置中,您可以根据标准偏差动态限制基准迭代次数,从而实施自适应策略,即收集样本,直到标准偏差在一定范围内。分布中的标准差越小,所需的样本数就越少。一旦标准偏差低于临界值,就可以停止收集测量值。Akinshin, 2019 Chapter 4中对这一策略有更详细的解释。
需要注意的一个重要问题是异常值的存在。可以将某些样本(例如冷运行)作为异常值丢弃,但不要故意从测量集中丢弃不需要的样本。对于某些类型的基准,异常值可能是最重要的指标之一。例如,在对有实时限制的软件进行基准测试时,99 百分位数可能会非常有趣。
我建议使用基准测试工具,因为它们可以自动进行性能测量。例如, Hyperfine是一款流行的跨平台命令行基准测试工具,它能自动确定运行次数,并能将结果可视化为包含平均值、最小值、最大值的表格,或方框图。
在接下来的两节中,我们将讨论如何测量挂钟时间(延迟),这是最常见的情况。不过,有时我们可能还想测量其他情况,如每秒请求数(吞吐量)、堆分配、上下文切换等。
2.5 软件和硬件定时器
为了对执行时间进行基准测试,工程师通常会使用两种不同的定时器,所有现代平台都提供了这两种定时器:
- 全系统高分辨率定时器
这是一个系统定时器,通常以简单计算自任意起始日期(称为Epoch)以来的刻度数的方式实现。该时钟是单调的,即总是上升的。系统时间可以通过系统调用从操作系统中获取。在 Linux 系统上,可以通过 clock_gettime 系统调用访问系统定时器。系统定时器的分辨率为纳秒,在所有 CPU 之间保持一致,并且与 CPU 频率无关。尽管系统定时器可以返回纳秒级精度的时间戳,但它并不适合测量短时间运行的事件,因为通过 clock_gettime 系统调用获取时间戳需要很长时间。但它可以测量持续时间超过一微秒的事件。在 C++ 中访问系统计时器的标准方法是使用 std::chrono:
#include <cstdint>
#include <chrono>
// 返回经过的纳秒数
uint64_t timeWithChrono() {
using namespace std::chrono;
auto start = steady_clock::now();
// 运行一些代码
auto end = steady_clock::now();
uint64_t delta = duration_cast<nanoseconds>
(end - start).count();
return delta;
}
- 时间戳计数器(TSC Time Stamp Counter)
这是一个硬件定时器,以硬件寄存器的形式实现。TSC 是单调的,速率恒定,即不考虑频率变化。每个 CPU 都有自己的 TSC,简单来说就是所经过的参考周期数(参见第 4.6 节)。它适用于测量持续时间从纳秒到一分钟的短事件。在 x86 平台上,可以使用编译器的内置函数 __rdtsc 来获取 TSC 值,该函数使用 RDTSC 汇编指令。关于使用 RDTSC 汇编指令对代码进行基准测试的更多底层细节,请参阅白皮书Paoloni, 2010 。在 ARM 平台上,您可以读取 CNTVCT_EL0,计数器-定时器虚拟计数寄存器。
#include <x86intrin.h>
#include <cstdint>
// 返回经过的参考时钟数
uint64_t timeWithTSC() {
uint64_t start = __rdtsc();
// 运行一些代码
return __rdtsc() - start;
}
选择使用哪种计时器非常简单,取决于您要测量的时间有多长。如果测量的时间很短,那么 TSC 的精确度会更高。相反,使用 TSC 来测量一个运行数小时的程序则毫无意义。除非您需要周期精度,否则系统定时器应该足以应付大部分情况。需要注意的是,访问系统定时器的延迟通常高于访问 TSC。执行 clock_gettime 系统调用可能比执行 RDTSC 指令慢得多。后者耗时约 5 ns(20 个 CPU 周期),而前者耗时约 500 ns。这对于最大限度地减少测量开销可能非常重要,尤其是在生产环境中。CppPerformanceBenchmarks 软件库的维基页面上提供了不同平台上访问定时器的不同 API 的性能比较。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
2.6 微基准
微基准是人们为快速测试某种假设而编写的独立小程序。通常,微基准用于选择某种相对较小的算法或功能的最佳实现。几乎所有现代语言都有基准测试框架在 C++ 中,您可以使用 Google benchmark库;在 C# 中,您可以使用 BenchmarkDotNet。Julia 有 BenchmarkTools 包,Java 有 JMH (Java Microbenchmark Harness),Rust 有 Criterion包等。
在编写微基准时,确保您要测试的场景在运行时确实由您的微基准执行是非常重要的。优化编译器可能会删除一些重要的代码,这些代码可能会使实验变得毫无用处,甚至更糟,会让您得出错误的结论。在下面的示例中,现代编译器可能会删除整个循环:
/ foo DOES NOT benchmark string creation
void foo() {
for (int i = 0; i < 1000; i++)
std::string s("hi");
}
类似这样的失误在论文Always Measure One Level Deeper : Ousterhout 2018中得到了很好的体现,作者在该文中提倡采用更科学的方法,从不同角度测量性能。根据论文中的建议,我们应该检查基准的性能曲线,确保目标代码成为热点。有时,异常时序会被立即发现,因此在分析和比较基准运行时要运用常识。
防止编译器优化掉重要代码的常用方法之一是使用类似 DoNotOptimize的辅助函数,这些函数会在引擎盖下执行必要的内联汇编魔法:
// foo benchmarks string creation
void foo() {
for (int i = 0; i < 1000; i++) {
std::string s("hi");
DoNotOptimize(s);
}
}
如果编写得当,微基准测试可以成为性能数据的良好来源。它们通常用于比较关键函数不同实现的性能。一个好的基准可以测试现实条件下的性能。相反,如果基准所使用的合成输入与实际情况不同,那么基准很可能会误导您,使您得出错误的结论。此外,当基准在没有其他高要求进程的系统上运行时,它拥有所有可用资源,包括 DRAM 和高速缓存空间。这样的基准很可能会支持速度更快的函数版本,即使它比其他版本消耗更多内存。但是,如果存在消耗大量 DRAM 的邻居进程,导致属于基准进程的内存区域被交换到磁盘,结果可能恰恰相反。
出于同样的原因,在对函数进行单元测试后得出的结果下结论时也要小心谨慎。现代单元测试框架(如 GoogleTest)会提供每次测试的持续时间。然而,这些信息并不能替代在实际条件下使用真实输入测试函数的精心编写的基准(详见Fog, 2023b, chapter 16.2)。虽然不可能总是复制与实际情况完全相同的输入和环境,但这是开发人员在编写优秀基准时应该考虑的问题。
2.7 主动基准测试
如前几节所述,衡量性能是一项复杂的任务,途中会有许多陷阱。作为人类,我们往往欢迎有利的结果,而忽视不利的结果。这往往会导致以 “运行并遗忘 ”的方式进行基准测试,不进行额外的分析,从而忽略任何潜在的问题。
以这种方式进行的测量很可能是不完整的、误导性的,甚至是错误的。
考虑以下两种情况:
-
开发人员 A 在团队会议上 “如果我们在整个 C++ 代码库的类声明中添加 final 关键字,将使我们的代码速度提高 5%,某些测试显示速度提高了 30%。
-
开发人员 B 在下一次团队会议上说 “我仔细研究了在类声明中添加 final 关键字对性能的影响。首先,我进行了较长时间的测试,没有测得超过 5%的提速。
最初观察到的 30% 速度提升是测试不稳定造成的异常值。我还注意到用于测量的两台机器配置不同:虽然 CPU 相同,但其中一台机器的内存模块速度更快。我在同一台机器上重新进行了测试,发现性能差异在 1%以内。我比较了更改前后生成的机器代码,发现没有明显差异。此外,我还比较了执行指令的数量、高速缓存缺失、页面故障、上下文切换等,没有发现任何异常。在这一点上,我得出的结论是,与我们可以进行的其他优化相比,最终关键字对性能的影响可以忽略不计"。
开发人员 A 所做的基准测试是被动完成的。结果的呈现没有任何技术解释,性能影响也被夸大了。与此相反,开发人员 B 进行了主动基准测试 。她确保了适当的机器配置,进行了广泛的测试,深入研究了更深的层次,并收集了尽可能多的指标来支持她的结论。她的分析解释了她观察到的性能结果的根本技术原因。
你应该有良好的直觉来发现可疑的基准结果。每当看到一些出版物介绍的基准结果看起来好得不像真的,而且没有任何技术解释时,你都应该持怀疑态度。展示测量结果无可厚非,但正如 John Ousterhout 所说:“性能测量结果在被证明无罪之前应被视为有罪”。Always Measure One Level Deeper : Ousterhout 2018验证结果的最佳方式是通过主动基准测试。
主动基准测试比被动基准测试需要付出更多努力,但这是获得可靠结果的唯一途径。
2.8 问题与练习
- 取一系列测量值的平均值来确定程序的运行时间是否总是安全的?有哪些误区?
- 假设您发现了一个性能错误,现在正试图在开发环境中修复该错误。如何减少系统中的噪音,以获得更明显的基准测试结果?
- 是否可以通过函数级单元测试来跟踪程序的整体性能?
- 贵组织是否有性能回归系统?如果有,是否可以改进?如果没有,请考虑安装该系统的策略。要考虑到:什么在变,什么没变(源代码、编译器、硬件配置等)、变化发生的频率、测量方差是多少、基准套件的运行时间是多少以及可以运行多少次迭代。
本章小结
- 现代系统具有非确定性能。消除系统中的非确定性有助于进行定义明确、稳定的性能测试,例如微基准测试。
- 要评估用户对服务响应速度的感知,就必须测量生产中的性能。不过,这需要处理噪声环境,并使用统计方法分析结果。
- 采用自动性能跟踪系统可以防止性能回归泄漏到生产软件中。此类 CI 系统应运行自动性能测试、可视化结果并对发现的性能异常发出警报。
- 可视化性能分布有助于比较性能结果。这是一种向广大受众展示性能结果的安全方法。
- 要对执行时间进行基准测试,工程师可以使用两种不同的定时器:全系统高分辨率定时器和时间戳计数器。前者适用于测量持续时间超过一微秒的事件。后者可用于高精度测量短事件。
- 微基准适合快速实验,但您始终应该在实际条件下的真实应用中验证您的想法。通过检查性能配置文件,确保基准测试的代码是正确的。
- 始终深入一级进行测量,收集尽可能多的指标来支持您的结论,并准备好解释您观察到的性能结果的根本技术原因。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号