Python并行编程2构建多线程程序(上):threading简介
2 构建多线程程序
在本章中,我们将介绍线程及其并发编程。在标准 Python 库中有一个threading 模块,它允许我们轻松地实现线程,并为线程的同步提供了一系列有用的工具。本章将专门介绍该模块,并逐一介绍所有提供的类及其功能。
主要内容
- 线程
- 锁和RLock
- 信号
- 条件
- 事件
- 线程池执行器
2.1 线程
并发编程的主角正是线程,为此,threading模块提供了Thread 类:
class threading.Thread(group=None,
target=None,
name=None,
args=(),
kwargs={},
*,
daemon=None)
Thread() 构造函数需要许多参数,其中最重要和最常用的是 target 和 args。要在线程中调用的函数传递给 target,而要传递给它的参数则传递给 args。我们可以通过一个实际例子立即了解这类对象的功能。在程序中,我们定义了五个线程,它们将相互竞争。所有线程都以同一个函数为目标,为方便起见,我们将其称为 function()。这个函数不会执行任务,只会占用很短的时间,只是为了模拟执行一组指令所花费的时间:
import threading
import time
def function(i):
print ("start Thread %i\n" %i)
time.sleep(2)
print ("end Thread %i\n" %i)
return
t1 = threading.Thread(target=function , args=(1,))
t2 = threading.Thread(target=function , args=(2,))
t3 = threading.Thread(target=function , args=(3,))
t4 = threading.Thread(target=function , args=(4,))
t5 = threading.Thread(target=function , args=(5,))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
print("END Program")
从代码中我们可以看到,首先定义了五个线程类实例,使用变量 t1、t2 等对应多个线程。随后,将通过调用 start() 方法启动线程的执行。运行程序后,我们将得到:
start Thread 1
start Thread 2
start Thread 3
start Thread 4
start Thread 5
END Program
end Thread 2
end Thread 1
end Thread 5
end Thread 3
end Thread 4
我们看到程序同时启动了所有五个线程,然后不等它们执行完毕就关闭了,导致输入新命令的提示出现。实际上,这五个线程在后台继续执行,继续在命令行上输出。
从输出中还可以看到另一个有趣的现象,那就是线程执行的关闭顺序与开始顺序不同,而且每次执行的顺序也会不同。这是线程的正常行为,因为它们是并发运行的。它们的执行持续时间和顺序很少可以预测。因此,使用本章后面将介绍的同步方法非常重要。
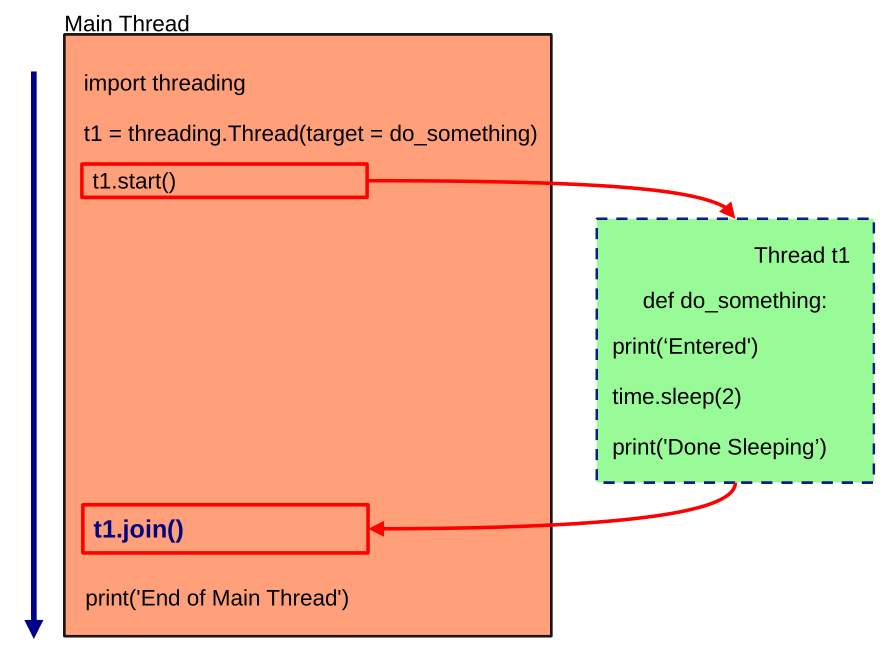
2.1.1 join() 方法
在前面的案例中,我们已经看到,通过在程序中启动线程,可以观察到程序在线程之前结束的行为。这个问题很容易解决,因为线程模块提供了 join() 方法。在线程上启动该方法后,程序会等待其执行结束后再关闭。因此,如果有多个线程,我们将在每个线程上调用 join() 方法。
import threading
import time
def function(i):
print ("start Thread %i" %i)
time.sleep(2)
print ("end Thread %i" %i)
return
t1 = threading.Thread(target=function , args=(1,))
t2 = threading.Thread(target=function , args=(2,))
t3 = threading.Thread(target=function , args=(3,))
t4 = threading.Thread(target=function , args=(4,))
t5 = threading.Thread(target=function , args=(5,))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t1.join()
t2.join()
t3.join()
t4.join()
t5.join()
print("END Program")
在这种情况下,通过运行程序,我们将得到如下结果:
start Thread 1
start Thread 2
start Thread 3
start Thread 4
start Thread 5
end Thread 1
end Thread 2
end Thread 3
end Thread 5
end Thread 4
END Program
我们可以看到,现在程序会等待所有线程执行完毕后才关闭。
但让我们进一步思考一下。作为一个简单的同步示例,我们可以在程序的某一时刻调用 join() 方法。例如,我们只想执行主程序的部分代码,然后等待线程开始执行。然后重新启动、执行其他操作或启动其他线程。
让我们通过修改前面的示例代码来看一个简单的例子:
import threading
import time
def function(i):
print ("start Thread %i" %i)
time.sleep(2)
print ("end Thread %i" %i)
return
t1 = threading.Thread(target=function , args=(1,))
t2 = threading.Thread(target=function , args=(2,))
t3 = threading.Thread(target=function , args=(3,))
t4 = threading.Thread(target=function , args=(4,))
t5 = threading.Thread(target=function , args=(5,))
t1.start()
t2.start()
t1.join()
t2.join()
print("First set of threads done")
print("The program can execute other code here")
t3.start()
t4.start()
t5.start()
t3.join()
t4.join()
t5.join()
print("Second set of threads done")
print("END Program")
运行新修改的代码,我们将得到如下结果:
start Thread 1
start Thread 2
end Thread 1
end Thread 2
First set of threads done
The program can execute other code here
start Thread 3
start Thread 4
start Thread 5
end Thread 4
end Thread 3
end Thread 5
Second set of threads done
END Program
我们可以看到,可以使用 join() 方法在程序中添加一个等待线程开始执行的点,然后用下面几行代码重新开始。

2.1.2 常见的线程同步模式
在前面使用多个线程的示例中,你可以看到相同的代码行被多次使用。每次我们都为每个线程定义了 start() 和 join() 方法的调用,写下了无数行类似的代码。随着线程数量的增加,情况会越来越糟。不过,还有其他更方便的代码编写方法。
import threading
import time
def function(i):
print ("start Thread %i" %i)
time.sleep(2)
print ("end Thread %i" %i)
return
n_threads = 5
threads = [ ]
for i in range(n_threads):
t = threading.Thread(target=function , args=(i,))
threads.append(t)
t.start()
for i in range(n_threads):
threads[i].join()
这种形式的代码更易读,也更简单。通过使用一个 for 循环来遍历所需的线程数量,我们避免了单独定义每个线程(t1、t2、t3......),以及为每个线程调用 start() 和 join() 方法。
我们将得到与前面示例相同的结果:
start Thread 0
start Thread 1
start Thread 2
start Thread 3
start Thread 4
end Thread 0
end Thread 1
end Thread 4
end Thread 3
end Thread 2
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
2.1.2 concurrent.futures模块和 ThreadPoolExecutor
除了线程模块外,标准库中还有另一个模块可以为我们提供线程方面的有用工具,我们将在下一章看到它,同样适用于进程。该模块名为 concurrent.futures,是异步执行可调用程序的高级接口。
其中的 ThreadPoolExecutor 类对于同时管理多个线程非常有用。事实上,当我们的程序中有许多线程需要管理时,最有效的方法就是创建一个 ThreadPoolExecutor。
举个例子,我们想同时启动四个线程,它们都与一个或多个函数相关联。与其编写四个 Thread 类实例的定义,然后四次调用 start() 方法和四次调用 join() 方法,不如使用 ThreadPoolExecutor 来得简单。
下面的代码就是一个例子:
import concurrent.futures
import time
def thread(num,t):
print("Thread %s started" %num)
time.sleep(t)
print("Thread %s ended" %num)
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as t:
t.submit(thread(1,10))
t.submit(thread(2,1))
t.submit(thread(3,10))
t.submit(thread(4,4))
print("Program ended")
运行这段代码,我们会得到类似下面的结果。
Thread 1 started
Thread 1 ended
Thread 2 started
Thread 2 ended
Thread 3 started
Thread 3 ended
Thread 4 started
Thread 4 ended
Program ended
线程是连续执行的,而执行显然是分开的。从这个极其简洁的结果来看,ThreadPoolExecutor 内部提供了某种同步系统。即使它内部不应该有任何同步系统。如果我们不使用 ThreadPoolExecutor,而是像下面这样写之前的代码:
import threading
import time
def thread(num,t):
print("Thread %s started" %num)
time.sleep(t)
print("Thread %s ended" %num)
t1 = threading.Thread(target=thread, args=(1,10,))
t2 = threading.Thread(target=thread, args=(2,1,))
t3 = threading.Thread(target=thread, args=(3,10,))
t4 = threading.Thread(target=thread, args=(4,4,))
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()
print("Program ended")
运行它,我们会发现完全不同的行为:
Thread 1 started
Thread 2 started
Thread 3 started
Thread 4 started
Thread 2 ended
Thread 4 ended
Thread 1 ended
Thread 3 ended
Program ended
在这里,线程是同时并发启动的。因此,每个运行线程的执行时间取决于其持续时间。
2.1.3 线程竞争
下面的代码是一个简单明了的示例,可以说明两个相互竞争的线程是如何工作的(并发编程)。每个线程都被分配了一个不同的函数 addA() 和 addB(),它们模拟循环执行的某种操作,每次迭代分别需要时间 A 和时间 B。这两个线程将一起启动,由于在 Python 中它们不能并行执行,只能一次执行一个,因此在程序执行过程中,它们将竞争以尽快结束它们的循环(COUNT 等于 5 次迭代)。为了监控两个线程的执行顺序,每个周期的两个函数都会将对应于两个线程的字母 A 和 B 添加到字符串中:
import threading
import time
sequence = ""
COUNT = 5
timeA = 5
timeB = 10
def addA():
global sequence
for i in range(COUNT):
time.sleep(timeA)
sequence = "%sA" %sequence
print("Sequence: %s" %sequence)
def addB():
global sequence
for i in range(COUNT):
time.sleep(timeB)
sequence = "%sB" %sequence
print("Sequence: %s" %sequence)
# the Main program
t1 = threading.Thread(target = addA)
t2 = threading.Thread(target = addB)
t1.start()
t2.start()
t1.join()
t2.join()
在程序运行过程中,您可以看到执行顺序。因此,如果运行你刚才编写的代码,就会得到类似下面的序列:
Sequence: A
Sequence: AB
Sequence: ABA
Sequence: ABAA
Sequence: ABAAB
Sequence: ABAABA
Sequence: ABAABAA
Sequence: ABAABAAB
Sequence: ABAABAABB
Sequence: ABAABAABBB
从结果中我们可以看到,两个线程以任意方式交替执行。你会发现,序列会随着执行的不同而变化。你还可以通过改变 timeA 和 timeB 变量的值来改变每个线程的执行时间。这将反过来影响相互竞争的两个线程的执行顺序。
2.1.4 使用Thread 子类
在前面的示例中,我们通过 Thread() 构造函数定义了一个线程,函数名称作为参数通过 target 参数传递给该构造函数:
t = threading.Thread(target = function_name)
在这种情况下,我们将函数中定义的代码所定义的线程分成了两个不同的实体。
另一种构思代码的方式是将新线程定义为线程子类,它有自己的方法,因此可以在其内部执行一些代码,而无需调用更多外部函数。这样,线程就是真正的对象,与面向对象编程一致。
from threading import Thread
import time
sequence = ""
COUNT = 5
timeA = 1
timeB = 2
class ThreadA(Thread):
def __init__(self):
Thread.__init__(self)
def run(self):
global sequence
for i in range(COUNT):
time.sleep(timeA)
sequence = "%sA" %sequence
print("Sequence: %s" %sequence)
class ThreadB(Thread):
def __init__(self):
Thread.__init__(self)
def run(self):
global sequence
for i in range(COUNT):
time.sleep(timeB)
sequence = "%sB" %sequence
print("Sequence: %s" %sequence)
# the Main program
t1 = ThreadA()
t2 = ThreadB()
t1.start()
t2.start()
t1.join()
t2.join()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号