GPU不一定是最佳选择
1 GPU确实很快
Bepuphysics v2 主要对两个架构细节非常敏感:内存带宽和浮点吞吐量。从配备双通道 DDR3 内存(如 3770K)的四核 4 宽 SIMD CPU 到配备 AVX2 和更高频率 DDR4 的 7700K,可以带来巨大的速度提升。尽管它仍然只是四核,而且从 Ivy Bridge 到 Kaby Lake 的通用 IPC/时钟改进并不具有突破性。
假设我们想疯狂一把,假设我还设法解决了高核心数系统的一些潜在调度问题。AMD 的 EPYC 7601 可能是一个不错的选择。尽管 Zen 1 的每核浮点运算能力不如当代的英特尔 CPU 或 Zen 2,但大量的内核可实现 600 多 gflops 的性能。如果使用 8 个内存通道的 DDR4 内存,有效内存带宽可以轻松达到 7700K 的 3 到 4 倍(120 多 GBps)。
现在考虑高端显卡。7601 属于高端产品,因此我们将考虑 2080 TI:13.4 tflops 和 616 GBps 内存带宽。Radeon Instinct MI60(采用大块 HBM2)的带宽约为 1 TBps。
即使将预算降至更合理的水平,CPU 和 GPU 之间的差距依然存在。显卡的设计就是为了获得巨大的吞吐量,是高度并行工作负载的理想选择,可以充分利用其极其宽泛的硬件。
图形显然非常适合图形硬件,但图形卡的功能已逐渐变得更加通用。我们已经从固定函数变换提升到了涵盖加密货币挖矿、蛋白质折叠、光线追踪以及物理模拟的通用级别。
所以,如果 “厕所厕所人 ”认为他们可以通过完全采用 GPU 执行获得如此巨大的收益,那我为什么还要为 CPU 构建 bepuphysics v2 呢?
2 算法与架构
要实现合理的多线程扩展,通常需要将计算表述为一个巨大的 for 循环,其中每个迭代都与其他迭代无关。如果能保证每次迭代都在进行完全相同类型的工作,只是数据不同,则可获得加分。这同时适用于 CPU 和 GPU,但在这种使用情况下,GPU 的性能往往远远超过 CPU。
3 案例研究:碰撞批处理
我们并不总能奢侈地将完全相同类型的独立任务做上一百万次。考虑一下碰撞检测的狭窄阶段。在 bepuphysics v2 中,每个工作者都会生成不可预测的碰撞对流。碰撞对的类型、数量和顺序都是未知的。这就带来了一些复杂性。一种潜在的 GPU 实现方式是,专门设置一个通道,从碰撞对流中提取所有工作,并将它们添加到大的连续列表中。该过程完成后,你会在一个位置上看到每个球体-球体对的列表,在另一个位置上看到每个球体-胶囊的列表,以此类推。看起来可能是这样的
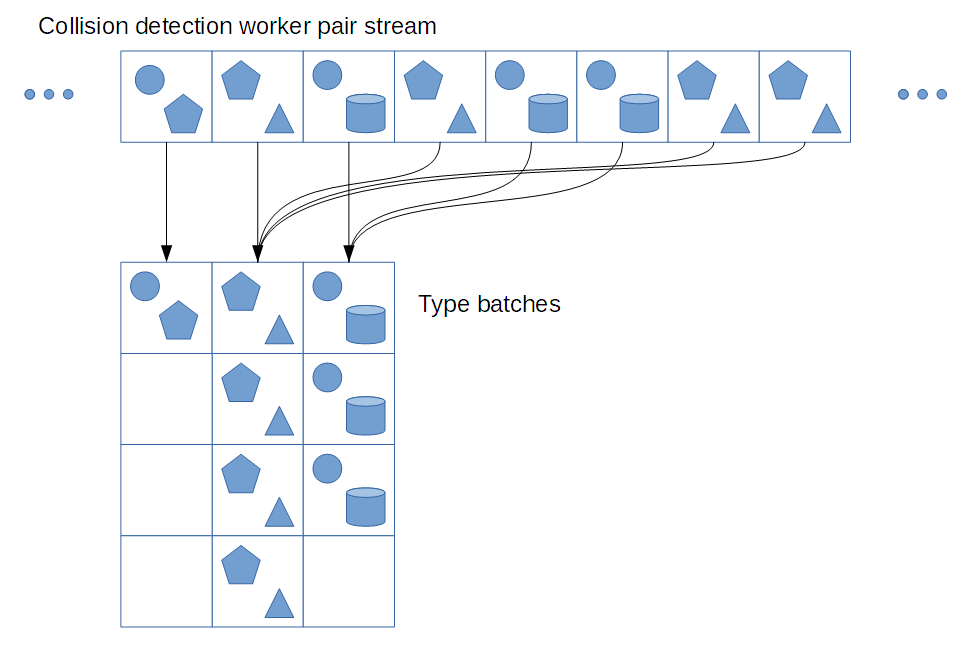
然后,你就可以为每对碰撞类型调度相应的碰撞处理程序。只要有足够数量的碰撞对,GPU 就能达到相当高的占用率。
但仍然存在一些问题。在 GPU 上,可能会有成千上万的工作者。你是否打算编写一套带有全局原子计数器的共享类型批处理?你花了那么多时间在第一遍中写入所有内容,却又要在第二遍中返回并重新读取所有内容--这占用了大量的内存带宽!
你还没有失去选择的余地,但现在事情开始变得复杂了。也许你可以创建一个批处理类型的中间集,在线程组共享内存中积累一个小的本地集,定期刷新到主集,从而减少全局原子调用的次数。也许你还可以巧妙地使用波形操作。
不过,即使不考虑记账成本,理论上毫无意义的 “写即读 ”问题依然存在。也许你可以利用硬件加速光线追踪所隐含的一些特性。使用不可预知的目标曲面着色器进行光线跟踪实际上是一个非常类似的问题,随着硬件的改进,可以高效地支持 “可调用着色器”,因此可以有更多的选择。
在 CPU 环境中,我们只需将每一对代码放入一个线程本地类型批处理中即可。当类型批计数达到某个执行阈值(比如 16 或 32 个条目)时,将其刷新。在大多数情况下,这意味着类型批中的数据仍在 L1 缓存中,如果没有,则几乎总是仍在 L2 缓存中。从配对收集任务到执行类型批处理的配对处理器之间的任务交换确实会带来一些开销,但对于 CPU 来说,我们谈论的是几十纳秒的高端时间。当类型批处理的执行时间预计只需几微秒时,这并不重要。
正如这些变通方法所显示的,在 GPU 上实现类似功能从根本上说并非不可能,但这对设备来说并不自然,而且你可能无法通过这样的代码来实现 13.4 teraflops 的数字(至少在一段时间内)。从高层次上讲,CPU 已对延迟进行了优化,可以轻松处理这类小规模决策,而 GPU 则对吞吐量进行了优化。这一点在硬件、工具和编程模型中都有所体现;逆向思维会让人感到不舒服。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
- 如需英文原版可联系微信pythontesting
4 案例研究:动态层次结构宽相位碰撞测试
算法的可并行性各不相同。有些算法顽固地抵制任何形式的多线程,有些算法则需要花费一些精力才能找出并行性,而有些算法的并行性则令人难以忍受。在很多情况下,当同一任务同时存在顺序算法和并行算法时,顺序算法的版本具有明显的优势,只有在并行版本上投入大量硬件才能克服这种优势。
Bepuphysics v2 的广泛阶段就是这种现象的一个有趣例子。它使用动态更新的二叉树。要找出存在哪些碰撞对,必须以某种方式对该树的所有叶子进行测试。
这种天真的算法非常简单,适合 GPU 或其他非常宽的机器:循环每一个可碰撞点,并根据树测试其边界框。每次测试都是完全独立的。
但要注意的是,我们要一遍又一遍地加载树的节点。整棵树可能有数百万字节,因此微小的内核本地缓存无法满足大多数请求。即使不考虑使用更远的缓存或主存储器所带来的额外成本,这也需要进行大量的边界框测试。与往常一样,有一些潜在的优化或变通方法,但与往常一样,它们也会带来一些复杂性方面的代价。
有一种非常简单的算法可以避免大部分工作。考虑两棵独立的边界树--互相测试根;如果它们相交,则测试它们的所有子树组合(对于一对二叉树,childA0-childA1、childA0-childB1、childB0-childA1、childB0-childB1);对于相交的树对,递归地继续相同的过程。结果就是树 A 和树 B 中叶子之间的所有重叠。
现在,我们可以更进一步:运行同样的过程,但树和树本身之间除外。需要注意的是,由于任何节点显然都会与自身重叠,因此无需进行大量的交集测试。与传统方法相比,我们不仅大大减少了交叉测试的次数,还消除了所有多余的节点负载。
这种算法的顺序性并不可怕--它以递归方式产生独立的工作,但也不是令人难堪的并行。换句话说,如果你有 64 个胖内核,你就可以创建足够多的工作任务,以低廉的价格填满硬件。但是,如果你的目标架构有成千上万个非常弱的线程,那么设置工作就会变得非常重要。
(值得一提的是,图形应用程序接口提供的 “线程 ”并不是 x86 CPU 上的那种线程。它们更像是宽 SIMD 单元中的通道。有时你可以利用这一点,但同样的,违背规律也会带来复杂性上的损失)。
那么这一切意味着什么呢?为了自然地适应 GPU,你通常需要选择适合其执行风格的算法。有时,这意味着要付出算法上的代价才能使用更并行的实现方式。在这种情况下,为了使用 GPU,你需要牺牲一些疯狂的计算能力。
当然,即使是残缺不全的 GPU 有时也能击败 CPU。
5 案例研究:记账
仿真中最不令人兴奋的部分有时也是最难在超宽硬件上实现的。考虑一下根据碰撞检测结果向求解器添加约束的过程。每个约束条件的添加都需要多个连续步骤,即使是将这些步骤分成若干并行任务,也会带来可怕的复杂性。
每个新约束条件都必须确定一个与新约束条件不共享任何体的求解器批次,然后必须为新约束条件找到(并可能创建或调整大小!)一个所属类型批次。然后,它必须进入每个体的约束列表,以确保可遍历的约束图。等等。这是我并列最不喜欢的引擎部分,这都是因为我试图在可用性极低的地方提取并行性。
还有更有趣的东西,比如睡眠和唤醒。除了添加一堆约束条件并更新所有相关的主体以匹配外,它还会同时移动一堆主体并更新大的阶段。(我本想链接一堆与此相关的内容,但我懒得去找所有的卷须)。
即使做了这么多努力,缩放仍然很糟糕。尤其是睡眠/唤醒,它在广泛的相位修改上遇到了严重的瓶颈。我的目标是在某个时候改善这个问题,但我真的非常不希望这样做。好的一面是,我们的大容量延迟优化 CPU 仍然表现出色。簿记很少占帧时间的很大一部分,除非你碰巧睡了一堆 16000 体。
如果没有大型 x86 内核来强行通过这些本地顺序块,这项工作就会成为一个严重的问题。试图在几个 GPU “线程”(HLSL 意义上的线程)上完成所有这些工作是不可能的。实际上,这需要完全不同的存储方法,或者将工作转移到更大的内核上。无论如何,这都不会令人愉快。
6 异步的痛苦
任何时候,如果你的仿真执行与某些交互系统(如游戏逻辑)不同步,就会产生复杂性。系统之间的所有交互都必须小心管理。这适用于 CPU 和 GPU 上的异步使用,但在 GPU 上运行仿真往往意味着更厚的障碍。即使只是在 PCIe 上移动数据也需要额外的时间。
游戏逻辑通常得益于与仿真的紧密结合。如果回调程序需要在 GPU 上执行,那么编写一个可以修改模拟状态或即时报告数据的回调程序就会变得非常困难。实际上,很多仿真状态只能间接访问。当然,你仍然可以使用它,但一切都会变得有点困难。
你也可以选择像 “Toilet Toilers ”那样完全接受它--甚至在 GPU 上执行大部分游戏逻辑。我可能会说你疯了,但你可以这么做。在 GPU 领域,工具的帮助、速度和稳定性通常难以达到在 CPU 领域工作时的预期......
如果模拟的唯一消费者是图形,并且图形和模拟是同步的,那么所有异步的痛苦都会消失。非交互式碎片、多种形式的布料、粒子和其他装饰性模拟都是 GPU 物理的绝佳用例,可以完全避免异步带来的痛苦。但这并不是我为 bepuphysics v2 设计的目标用例。
7 比较优势
在许多游戏中,GPU 所带来的超强马力已经得到了充分体现。使用光线追踪全局光照渲染 4K@120hz 的速度仍然超出了当前所有硬件的能力范围,而当我们拥有了相应的硬件时,我们已经在尝试为 VR 或其他设备渲染高密度光场了。
为了运行物理效果而降低一些图形的华丽程度是否值得?如果我们假设 GPU 的执行速度是 CPU 的 4 倍,并且上述所有问题都得到了解决,那么我们就可以将 6 毫秒的 CPU 仿真转移到 GPU 上,而只需 1.5 毫秒。如果模拟和渲染都以 144hz 为目标,那么你的渲染预算就会减少 20%,但 CPU 预算却会大幅增加!......现在你打算如何使用 CPU 预算?
我想,你可以在驱动程序中浪费更多时间,大量调用绘制调用。你可以使用 DX12 或 Vulkan 和多线程生成大量的绘制调用。或者使用间接渲染和 GPU 驱动的流水线......
或许你还可以做一些花哨的声音追踪和动态音频效果!但很多查询都非常适合模拟结构,而且每帧都通过 PCIe 拉动似乎很浪费,而实际涉及的数学运算则适合 GPU...
或者使用一些花哨的机器学习技术来制作角色动画,但这样 GPU(尤其是有专用硬件的 GPU)的推理速度就会比 CPU 快很多...
我的意思并不是说你不能把 CPU 的时间花在任何事情上,只是说很多繁重的工作都可以很好地映射到 GPU 上。尽管如此,让 CPU 闲置也是没有意义的。即使 GPU 在技术上可以更快地完成工作,也应该让 CPU 合理地完成工作,因为 GPU 已经在做其他事情了!
(后端使用案例可能会很有趣--服务器上没有渲染功能可以为更多工作打开空间。你仍然会遇到这里列出的许多其他问题,但至少你可以腾出计算资源)。
8 决定性因素
我已经阐述了 GPU 仿真的各种问题,但我也试图为每种情况提供一些解决方法。用 GPU 进行快速仿真绝对是可行的,毕竟已经有人这么做了。
但有一个问题我找不到解决方法。要在不同的硬件供应商、不同年代的硬件、不同的操作系统和不同版本的驱动程序之间可靠地运行复杂的 GPU 应用程序,是一件极其痛苦的事情。在复杂度达到一定程度后,如果不能直接联系到所有相关的工程团队,又没有几吨重的美元,我真的不相信能做到这一点。我没有那么多钱,也没有多少人知道我的存在;碰到一个特别危险的驱动程序错误,可能会扼杀整条研究线。
而且,即使我设法以某种方式实现了合理的稳定性,较新驱动程序的回归--尤其是在较旧的硬件上--也并不罕见。厕所工的命运只是稍微被夸大了一点,而且只是在时间密度上被夸大了一点。
我可以尝试向所有相关方报告所有问题,但老实说,如果他们在 5 年后仍不解决问题,我也不能责怪他们。有些问题只是一些奇怪的小角色。有些问题并不适用于任何现代硬件。把有限的开发资源用在真正能带来数百万或数十亿美元销售额的项目上,才是最合理的。(也许有一天!)。
你可能会注意到,这种思路几乎意味着任何 GPU 开发对于小公司来说都是失败的,而不仅仅是 GPU 物理。虽然这个生态系统令人沮丧,但我并不愿意走得那么远。图形和物理之间有一些重要的区别。
在物理模拟中,一个时间步骤的结果会反馈到下一个时间步骤,再反馈到下一个时间步骤,以此类推。如果任何阶段在任何时候出现故障,都会导致整个模拟失败。例如,一个 NaN 将在一两帧内通过约束图传播。再过一两帧,模拟可能就会崩溃。
图形的适应能力稍强一些。当然,仍有一些类型的错误会导致一切崩溃,但大多数较温和的错误是可以克服的。它们可能只是在这里或那里导致一点视觉损坏--一旦脱离任何时间累积窗口,问题就可能解决。
换句话说,在图形类任务中,数据依赖链往往很短。错误没有机会对自身产生灾难性的影响,或者错误是有边界的。
此外,图形引擎通常有大量的调节旋钮,或针对不同质量级别的效果有多种实现方式。有时可以通过摆弄这些旋钮来解决错误。物理模拟器通常没有这么多自由度。
最后,如果您是一名小型开发人员,正在开发图形处理程序,那么您很可能只针对一种应用程序接口和操作系统。比如说,在 Win10 上专注于 DX12 并不容易,但这并不像同时支持其他操作系统/API 那样是一场噩梦。(对于某些仅在客户端使用 GPU 的物理应用案例也是如此,但如果要在服务器端运行物理,则可能需要在非 Windows 系统上运行,因为服务器许可模式是唯一比驱动程序错误更糟糕的事情)。
但即使是图形引擎,情况也很糟糕,如果你打算在各种平台上运行,使用超级流行的图形引擎是明智之举。这是一条成千上万其他开发者已经走过的老路,他们已经为你吃尽了苦头。
9 结论
如果我将 bepuphysics v2 移植到 GPU 上运行,我可能会让它变得更快。虽然这需要很长时间。另外,V2 的性能已经接近(有时甚至超过)某些 GPU 刚体模拟器,所以我觉得没问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号