为什么你找不到的东西别人能找到?-让你高人一筹的搜索技巧
9 搜索引擎
许多研究人员的第一站都会选择流行的搜索引擎。美国的两大搜索引擎是 Google 和 Bing。本章将详细介绍使用这两个搜索引擎和其他搜索引擎的高级方法。这些技术大多适用于任何搜索引擎,但许多示例将专门针对这两个搜索引擎。
百度上充斥各种垃圾广告,魏则西等事件害死了一些年轻鲜活的生命。为了良知和避免误导,常规搜索请远离百度。除了google,还有一些可以直接访问的,相对较良心的搜索引擎存在的。
微软bing是世界第2大搜索引擎,本身做得并不差。但是首页的导航图片都晃得人眼花,所以我一般都直接让它默认进site:china-testing.github.io以避免图片出现。另外bing和病是一个音,有人说是微软有病。不过客观的说,bing的搜索结果通常还是强过国内这些引擎的。

9.1 谷歌(google.com)
有整本书专门介绍谷歌搜索和谷歌黑客。其中大部分侧重于渗透测试和计算机网络安全。这些书信息量很大,但对于寻找快速个人信息的调查人员来说,往往是大材小用。一些简单的规则可以帮助找到更准确的数据。
- 引号
将目标名称放在引号内,对快速查找信息有很大的帮助。
在不加引号的情况下搜索我的名字,结果是包含 “Michael ”和 “Bazzell ”的 147,000 页。搜索 “Michael Bazzell”(包括引号),搜索结果会减少到 31800 个。
在搜索 “michael@inteltechniques.com”的电子邮件地址时,如果不加引号,我会收到 14,200 个结果。加引号只收到 7 个实际包含该电子邮件地址的结果(我的收件箱中没有该电子邮件地址)。搜索xurongzhong#126.com也是如此。
- 搜索操作符
大多数搜索引擎允许在搜索字段中使用命令。这些命令实际上不是搜索条件的一部分,被称为操作符。大多数操作符搜索分为两个部分,每部分之间用冒号隔开。冒号左边是操作符的类型,如 “site”(网站)或 “ext”(文件搜索引擎)。右边是运算符的规则,如目标域或文件类型。下面将解释每个运算符及其最合适的用途。
- 网站操作符
谷歌和其他搜索引擎允许在搜索字符串中使用操作符。操作符是添加到搜索中的文本,用于执行某种功能。我最喜欢的操作符是 “site: ”功能。这个运算符对搜索结果有两个好处。首先,它只会提供位于特定域的网页结果。

在进行私人背景调查时,我经常使用站点操作符。通过搜索 “site:amazon.com ”和目标名称,可以发现一些有趣的信息。以前曾对一名签署了宣誓书声明以前没有毒品或酒精依赖症的申请人进行过背景调查,结果发现了一些有危害性的信息。搜索结果提供了用户提交的评论,这些评论是他在亚马逊上留下的,涉及他购买的帮助他戒除对受控物质持续上瘾的书籍。
- 文件类型操作符
谷歌和必应的另一个操作符是文件类型过滤器。它允许你通过单个文件类型扩展名过滤任何搜索结果。谷歌允许将该操作符简称为 “ext”,而必应则不允许。因此,我将在搜索示例中使用原始的 “文件类型 ”运算符。请看下面的搜索,尝试查找与 Cisco 公司相关的 PowerPoint 演示文稿文件:"Cisco" "PowerPoint", 结果是内容中包含 Cisco 和 PowerPoint 字样的网站超过 10,000,000 个。不过,这些并不都是实际的 PowerPoint 文档。为了保证准确性,下面的搜索对我们的示例进行了细化:"Cisco" filetype:ppt,搜索结果是 15,200 份内容中包含 Cisco 的 Microsoft PowerPoint 演示文稿。这次搜索只找到了较早的 Power Point 格式 PPT,但没有找到扩展名为 PPTX 的较新文件。因此,以下两种搜索方式会更彻底:"Cisco" filetype:ppt ; "Cisco" filetype:pptx。
以前,谷歌和必应按 MP3、MP4、AVI 和 otl1ers 等类型索引媒体文件。由于反盗版,这种做法已不再奏效。我发现以下扩展名可被索引并提供有价值的结果。

- 减号(-):减法
前面提到的搜索运算符是包含特定数据的过滤器。相反,您可能希望将某些内容排除在搜索结果之外。减号 (-) 会告诉大多数搜索引擎和社交网络从任何结果中排除紧随其后的文本。记住减号和过滤文本之间不要有空格。
比如:"xurongzhong#126.com"返回5页,‘"xurongzhong#126.com" -37391319’则只返回2页。
最后的搜索剔除了包含任何限制词的结果。剩下的页面则引用了与我同名的其他人。我使用搜索过滤器的目的是将搜索结果总数减少到可控范围内。当你被搜索结果淹没时,可以慢慢添加排除项,从而对需要分析的数据量产生影响。
- InURL 操作符
我们还可以指定只关注网站 URL 或地址内数据的操作符。
之前讨论的操作符适用于网页内容。我最喜欢使用这种技术搜索允许匿名连接的文件传输协议(FTP)服务器。下面的搜索可以找出任何拥有包含 OSINT 术语的 PDF 文件的 FTP 服务器。
inurl:ftp -inurl(http I https) filetype:pdf "OSINT”
下面将剖析这种搜索的工作原理和原因。
inurl:ftp - 指示 Google 只显示 URL 中包含 “ftp ”的地址。-inurl(http I https) - 指示 Google 忽略 URL 中包含 http 或 https 的任何地址。分隔符是位于反斜杠键上方的管道符号 (I)。它告诉谷歌 “或”。这将确保我们排除任何标准网页。
- InTitle 操作符
与 InURL 类似,“InTitle ”操作符也可以通过页面实际内容以外的细节过滤网页。该过滤器只会显示网页标题中有特定内容的网页。实际上,互联网上的每个网页都有一个正式的网页标题。这通常包含在网页的源代码中,可能不会出现在内容的任何地方。大多数网站管理员都会精心设计一个最适合搜索引擎索引的标题。如果你在谷歌上搜索 “osint 视频培训”,你会收到 2,760 个结果。但是,下面的搜索会将这些结果过滤为 5 个。这些结果只包括在页面标题的有限空间内包含搜索词的网页。
intitle:"osint video training"
allintitle:training osint video
intitle:index.of OSINT
- OR 运算符
您的搜索条件可能不是确定的。您的目标可能有一个经常拼写错误的独特姓氏。OR"(大写)运算符会返回只有 A、只有 B 或同时有 A 和 B 的页面。
"Michael Bazzell" OSINT 61,200
"Mike Bazzell" OSINT 1,390
"Michael Bazzell" OR "Mike Bazzell" OSINT 18,600
"Michael Bazell" OR "Mike Bazell" OSINT 1,160
"Michael Bazzel" OR "Mike Bazzel" OSINT 582
- *通配符
Google 将 “*”视为搜索字符串中一个或多个单词的占位符。例如,“osint * training ”可让 Google 查找包含以 “osint ”开头,后面跟一个或多个单词,再后面跟 “training”的短语的网页。
- 范围运算符( .)
范围运算符 "可让 Google 在两个标识符之间进行搜索。这些标识符可以是连续的数字或年份。例如,“OSINT 培训 2015 ... 2018 ”将导致包含 OSINT 和培训这两个术语的页面,同时还包括 2015 至 2018 之间的任何数字。我曾用它来过滤包含评论系统的在线新闻文章结果,读者可以在评论系统中表达自己的观点。以下搜索可识别包含有关邦妮-伍德沃德(失踪人员)的信息,以及页面内 1 至 999 条评论的网站。
"bonnie woodward" "1..999 comments"
- Related
在过去一年中,该选项已被证明非常有用。它收集一个域名,并尝试提供与该地址相关的在线内容。例如,我使用以下语法在 Google 上进行了搜索。
related:inteltechniques.com
结果中没有提到该域名,但却与我的其他网站、我的 Twitter 页面、我的黑帽课程和我在亚马逊上的书相关联。在我的调查中,这已经将一个人的个人网站转化为多个社交网络和朋友的网站。
- 谷歌搜索工具
每个谷歌搜索结果页面的顶部都有一个文本栏。通过它可以在图片、地图、购物、视频等其他谷歌服务中搜索当前搜索词。该栏的最后一个选项是 “工具 ”链接。点击该链接后,正下方会出现一排新的选项。它提供了新的筛选器,帮助你只关注所需的结果。每种 Google 搜索类型的筛选器都有所不同。
任何时间 "下拉菜单允许你选择可见搜索结果的时间范围。默认设置为 “任何时间”,不会过滤任何结果。选择 “过去一小时 ”将只显示一小时内索引的结果。日、周、月和年的其他选项也是如此。最后一个选项是 “自定义范围”。这将弹出一个窗口,允许你指定想要搜索的确切日期范围。当你想分析已知时间内发布的在线内容时,这将很有帮助。

- 谷歌可编程搜索引擎(programmablesearchengine.google.com )
现在,您已经准备好释放谷歌的力量,您可能想考虑创建自己的自定义搜索引擎,谷歌已将其重新命名为可编程搜索引擎。谷歌允许你指定要进行搜索的具体类型,然后根据你的需要创建一个单独的搜索引擎。许多声称只搜索社交网络内容的专业网站只是在使用谷歌的自定义搜索引擎。

登录谷歌账户后,导航到上面列出的网站。如果您从未创建过引擎,系统会提示您创建第一个引擎。输入要搜索的第一个网站。在我的例子中,我将搜索 inteltechniques.com。当你输入任何要搜索的网站时,Google 会自动创建另一个字段来输入其他网站。我要搜索的第二个网站是 inteltechniques.net。输入自定义引擎的名称,然后选择 “创建”。现在你就有了一个自定义搜索引擎。您既可以将该搜索引擎嵌入到网站中,也可以在任何网络浏览器中查看公共 URL 以访问该搜索引擎。

一些示例:


- 谷歌快讯(google.com/ alerts)
当您在搜索引擎上搜索完一个目标后,您会想知道是否有新内容发布。每周检查同一目标的谷歌搜索结果,看看是否有新的内容发布,这样会变得很无聊。利用 Google Alerts 可以让 Google 查找新信息。登录任何谷歌服务(如 Gmail)后,创建一个新的谷歌快讯,并指定搜索词、发送选项和发送快讯的电子邮件地址。在我的一个警报中,谷歌每天都会发送一封电子邮件,因为它找到了在网站任何地方提到 “开源情报技术 ”的新网站。我的另一个警报是针对我的个人网站的。现在,当其他网站提到或链接到我的网站时,我就会收到一封电子邮件。
如果孩子在网站或博客中被提及,家长也可以使用此功能收到通知。不断寻找目标信息的调查人员会发现这很有用。
9.2 必应(bing.com)
谷歌并不是唯一优秀的搜索引擎。虽然谷歌是当今搜索引擎的首选,但其他网站也不容忽视,尤其是在难以找到任何相关信息时。
必应是微软与谷歌的竞争者,提供了很好的搜索体验。2009 年,雅虎搜索(yahoo.com)开始使用必应搜索引擎生成搜索结果。如果已经进行了必应搜索,那么雅虎搜索就会变得多余。前文和众多谷歌书籍中描述的策略同样适用于任何搜索引擎。网站操作符和引号的使用在必应上的效果与在谷歌上完全一样。必应还引入了时间过滤搜索功能,可以只显示过去 24 小时、一周或一个月的搜索结果。还有几个重要的操作符只适用于必应。必应提供了一个选项,可以列出目标网站链接到的每个网站,必应是唯一提供此项服务的搜索引擎。
- 必应 LinkFromDomain
我在 Bing 上搜索了 “LinkFromDomain:inteltechniques.com”。请注意,整个搜索字符串中没有空格,引号也应省略。该操作符创建的结果包括我网站内任何页面上有链接的所有网站。这对调查人员很有用。当发现目标网站时,该网站可能很大,包含数百个页面、博客条目等。虽然可以点击浏览所有这些内容,但有时链接是隐藏的,无法通过直观查看页面看到。该操作符允许必应从网站的实际代码中快速提取链接。
- 必应包含
之前,我讨论过在 Google 上搜索具有特定文件扩展名的文件。之前解释过的 “filetype ”和 “ext ”运算符在必应上的工作方式是一样的。不过,必应还提供了一个新选项:Contains。“包含 "操作符允许你扩展文件类型搜索的参数。例如,必应搜索 “filetype:ppt site:cisco.com ”会返回 13,200 个结果。这些结果包括存储在 cisco.com 域中的 PowerPoint 文件。但是,这些结果并不一定包括 cisco.com 网站上指向存储在其他网站上的 PowerPoint 文件的链接。在必应上搜索 “contains:ppt site:cisco.com ”会返回 36,200 个结果。这些结果包括从 cisco.com 域名上的网页链接到的 PowerPoint 文件,即使这些文件存储在其他域名上。这可能包括 cisco.com 上链接到 hp.com 上 PowerPoint 文件的页面。在大多数情况下,这种搜索无需进行文件类型搜索,但两种搜索都应尝试。
9.3 谷歌图片(images.google.com)
谷歌图片会根据搜索词在网上搜索图形图像。Google 根据图像的关键字获取这些图像。这些关键字取自图片的文件名、指向图片的链接文本以及与图片相邻的文本。这并不能完整列出与某个主题相关的所有图片,而且几乎总是能找到与目标完全无关的图片。如果是普通姓名,则应将姓名用引号括起来,并在引号后注明目标人物居住的城市、工作地点、家乡或个人兴趣。这将有助于筛选出更有可能与目标相关的结果。显示结果后,单击 “工具 ”按钮将显示五个新的过滤菜单。通过该菜单,您可以过滤结果,使其只包括特定尺寸、颜色、时间范围、图片类型或许可证类型的图片。谷歌图片最有用的功能是反向图片搜索选项。本书稍后将对此进行详细介绍。
9.4 必应图片(bing.com/images)
与谷歌类似,必应也提供出色的图片搜索功能。这两个网站都会在当前结果快结束时自动加载更多图片。这样就不需要继续加载额外的页面,从而加快了浏览速度。必应还提供 Google 上的高级选项,并增加了只过滤指定布局(如正方形或宽幅)文件的功能。必应在搜索结果的最右侧提供了一个 “过滤 ”选项,可提供扩展功能。人物 “选项卡提供了对 ”仅脸部 “和 ”头部和肩部 "图片的限制。它还会在每次图片搜索时提供建议过滤器。点击图片搜索链接可根据列出的标准提供特定目标的其他照片。这些信息可以帮助搜索到更多以前未知的关联信息。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
9.5 国际搜索引擎
总部设在美国的搜索引擎并非所有国家的主要搜索网站。访问美国以外的搜索网站可以获得不会出现在 Google 或 Bing 上的结果。在俄罗斯,Yandex 是首选搜索引擎。Yandex 提供英文版 yandex.com。这些搜索结果通常与谷歌搜索结果相似,但优先级不同。过去,当谷歌让我失望时,我曾从这个网站上发现了独特的情报。在中国,因为管制不少人人使用百度(虽然整体水平比较糟糕)。在谷歌或必应上看不到的新结果可能很少,但偶尔看看这些网站还是有必要的。主要非主流搜索引擎如下:

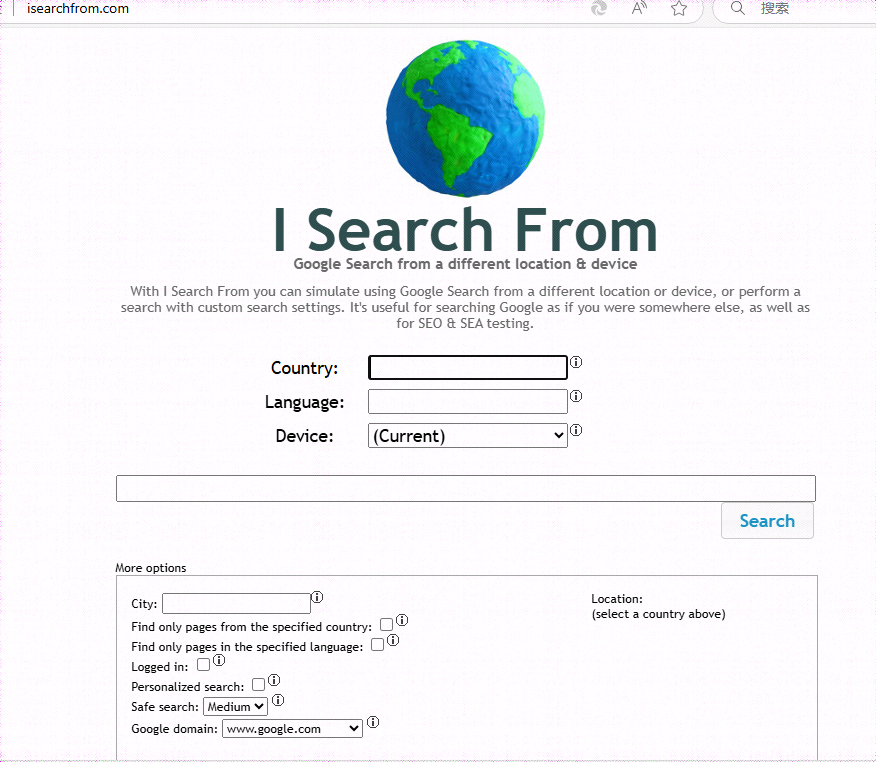
- Search From (isearchfrom.com)
如果您想在另一个国家指定的版本内搜索 Google,该网站可以简化搜索过程。
选择国家和语言,剩下的就交给这个工具吧。在测试这项服务时,我将日本作为我的国家,英语作为我的语言,iPad 作为我的设备,OSINT 作为我的搜索词。我看到了一个平板电脑视图的 google.co.jp 搜索页面。许多结果与美国版本类似,但所有结果的顺序都是独一无二的。我发现这在搜索国际目标时非常有用,因为我不想偏向美国用户。
国外搜索的 “新闻 ”标签通常是针对该地区受众的。这可以显示新闻文章的重点,否则这些文章就会被埋没在典型的谷歌搜索结果页面中。
9.6 网络档案
有时,你试图访问一个网站,但你要找的信息已经不在那里了。可能是某些内容被删除或修改了,也可能是整个页面被永久删除了。网络档案或“缓存 "可以解决这个问题。我认为,在进行任何类型的在线研究时,这些网站的历史副本都是最重要的资源之一。本节将按照从最有效到最无效的顺序解释当前的选择。
- 谷歌缓存 (google.com)
进行 Google 搜索时,请注意网站链接正下方的结果地址。你会看到一个绿色的向下箭头,点击后会出现一个菜单。该菜单包括一个名为 “缓存 ”的链接。点击它将加载感兴趣网页的前一个版本。
如果你想查看某个网站的特定页面的缓存版本,请在 Google 中输入确切的网站链接到缓存页面。例如,如果我想查看有关电话恶作剧的音频档案 “电话秀”(The Phone Show)播客的上一版本,我会在 Google 上搜索该网站
“www.phonelosers.org/snowplowshow"。这将返回主登陆页面以及子页面,每个子页面都有一个缓存视图。如果其中任何一个页面完全离线,谷歌将保留最后获得的版本以供查看。我也可以在任何谷歌搜索页面直接输入以下内容,直接导航到缓存页面。
cache:www.phonelosers.org/ snowplowshow
- 必应缓存(bing.com)
与谷歌类似,必应也提供许多网站的缓存视图。搜索域名(如 phonelosers.org)会出现许多结果。第一个结果应链接到实际网站。网站名称旁边有一个绿色的向下箭头。点击它将显示 “缓存页面 ”选项。点击该链接将显示必应收集的目标网站以前的版本。
- Yandex 缓存 (yandex.com)
俄罗斯搜索引擎 Yandex 将在后面详细介绍,但现在有必要指出的是,它也拥有一个缓存选项。与谷歌和必应非常相似,Yandex 在搜索结果标题的正下方显示了一个绿色的下拉菜单。andex 缓存的最大优点是无需更新。虽然这听起来有悖常理,但较早的缓存对调查很有帮助。你通常可以在百度上找到比 Yandex 版本更早的缓存页面。
- 百度缓存 (baidu.com)
就缓存的网站副本而言,该中文搜索引擎的效率最低,但也不应忽视。我们将在后面关于国际引擎的讨论中进一步解释它。在百度上搜索的结果大多是中文,但对那些无法阅读文本的人来说仍然很有价值。每个搜索结果的底部都有一个绿色链接,指向该结果内容所在的网站。
- Wayback Machine(archive.org/web/web.php)
Wayback Machine 可提供更多查看网站历史记录的选项。
搜索 phonelosers.org,会显示从 1997 年 12 月 21 日到 2019 年 10 月 6 日期间该网站的总共 1,280 个截图(图 9.08)。点击链接后,网站的变化一览无余。图片也被存档,这证明我们在向互联网发布照片时应该三思而后行。每次浏览存档页面时,用户都可以点击链接,就像在原始网络服务器上浏览实时页面一样。点击每个页面顶部的时间轴,将加载所选日期出现的页面。
- Wayback搜索
直到 2016 年,您还不能在 Wayback Machine 数据中搜索关键字。您必须知道目标网站的准确 URL,或者至少是域名。如今,我们可以搜索任何想要的关键词,并直接连接到存档数据。在撰写本文时,每个 Wayback Machine 页面的顶部都有一个搜索栏。
如果情况有变,您也可以通过直接 URL 进行搜索。以下地址可在整个信息档案中搜索 “迈克尔-巴泽尔”。
https://web.archive.org/web/*/Michael Bazzell
结果发现有二十多个网站包含这些术语。在这些网站中,每个网站都有几十个存档副本。这些数据代表了数十年来您触手可及的内容。其中大部分内容已经离线,在当前的公共互联网上无法获取。许多域名已经完全关闭。此外,我拥有的网站也出现在搜索结果中,尽管我通过服务器上的配置文件明确阻止了这些网站的存档。通过 Wayback Machine 直接搜索域名是找不到这些网站的。这提醒我们,在完成调查之前,应该检查所有可用资源。
- 搜索所有资源
偶尔会有一些网站声称能够从在线缓存中提取并重建整个网站。根据我的经验,与手动方法相比,这些网站都无法提供完整的历史记录。必应和 Yandex 等引擎会在显示缓存时生成一个唯一的代码。这一操作会阻止大多数自动搜索工具收集存档信息。我认为,除了导航到每个资源外,没有任何其他方法能为您提供所需的内容。我将每项服务都收藏在一个名为 “档案 ”的单独文件夹中,当我将某个域作为目标时,就会打开每个标签页。我还创建了一个在线工具,可以收集目标域并将您转到相应的档案页面。稍后在讨论域名搜索时将对此进行解释。
最后,必须承认的是,当网站上的所有内容似乎都存在且未被更改时,这些资源就会发挥作用。虽然缓存对那些已被删除且完全清空的网站效果很好,但它们也会对那些看似正常的网站产生不同的影响。每当我发现一个感兴趣的网站、个人资料或博客时,我都会立即查看缓存,希望能发现内容的变化。这些细微的改动可能非常重要。它们会突出显示本应永远删除的信息。这些细节可能是调查拼图中至关重要的部分。大多数人都不知道这种技术的存在。


9.7 翻译
并非所有对您有用的信息都能在英文网站上通过标准搜索获得。您的目标可能来自另一个国家,或者在另一个国家有合作伙伴和附属机构。
虽然谷歌和必应都在努力捕捉这一点,但技术并不完善。谷歌的搜索网站和算法会因地点而改变。例如,google.fr 显示的是 Google 的法文搜索页面。虽然这可能会产生相同的总体结果,但它们的顺序通常与 google.com 上的不同。谷歌不再维护一个链接到其搜索的每个国际版本的页面,但我有一个首选方法。
- 2Lingual (2lingual.com)
通过该页面,您可以在谷歌的两个国家网站上进行一次搜索。谷歌搜索将显示一个普通搜索框和两个国家的选择。搜索结果将以单列形式显示。此外,外国结果将自动翻译成英文。如果需要,可以禁用此功能。前几个赞助商搜索结果(广告)会很相似,但后面的正式搜索结果会有所不同。
在向他人展示通过多个国家搜索目标的重要性时,该网站也很有帮助。
- 谷歌翻译器(translate.google.com)
许多网站都有非英语语言版本。作为互联网爱好者,我们往往只关注自己所在地区的网站。但在其他国家的网站上,却有大量以其他语言呈现的信息。谷歌翻译器可以将任何网站或文档中的文本翻译成多种语言。通常,该服务会自动识别复制和粘贴文本的语言。选择所需的输出将提供翻译。此外,您还可以一键翻译整个网站,从而获得网站布局的本地视图。请输入或粘贴您要翻译的网站的准确 URL(地址),而不是将单个文本复制到搜索框中。单击 “翻译 ”按钮将加载一个新的网站页面,该页面将被翻译成英文。这种翻译很少是完美的。不过,您可以通过它了解页面上的内容。这也适用于 Twitter 和 Instagram 等社交网站。
- 必应翻译器(bing.com/ translator)
在谷歌推出免费翻译服务几年后,必应也推出了自己的产品。乍一看,它就像是谷歌产品的翻版。不过,必应的翻译结果通常与谷歌略有不同。与谷歌类似,您也可以输入或粘贴整个外国网站,对目标页面上的所有内容进行翻译。
- DeepL ( deepl.com/ translator)
虽然规模小于谷歌或必应,但这可能是我发现的最准确的翻译服务。该页面的显示和功能与前面的选项相同,但结果可能有很大不同。
- PROMT 在线翻译器(online-translator.com)
还有几十种在线翻译工具可供使用。几乎所有这些工具都允许一次翻译少量文本的翻译。有些工具使用谷歌或必应翻译服务。最后一个在线翻译工具值得一提的是 PROMT 在线翻译工具。与其他几十种选择相比,它的独特之处在于它可以翻译整个网站,与谷歌和必应类似。这项服务提供独立的翻译,可以被视为第三来源。
在培训期间,经常有人问我在调查过程中使用了哪些服务。我的回答是全部。这一点很重要,原因有二。一个显而易见的好处是,您将收到四份非常相似的独特译文。细微的差别可能很重要,尤其是在翻译推文和其他简短信息时,这些信息在任何语言中都可能语法不正确。第二个原因是我在调查过程中尽职尽责。我总是希望超越要求。通过四种不同的服务翻译一个外国网页强调了我进行公正调查的愿望。
- 谷歌输入工具(google.com/inputtools/try)
在外语搜索方面,我还发现了最后一个有用的功能。谷歌输入工具允许你输入任何你选择的语言。进入上述网站后,选择目标搜索语言。在图 9.09 中,我选择了阿拉伯语作为语言,并在标准英语键盘上输入了 “在线调查”。结果就是该文本在阿拉伯语传统字母中的显示效果。我在 Twitter 上使用这种技术最成功。在 Twitter 上提供任何搜索词时,搜索结果都会根据输入关键词的存在情况进行过滤,而且只使用所提供的语言。在 Twitter 上搜索只能得到包含该单词英文拼写的结果。然而,搜索阿拉伯语输出则会提供包含所选单词阿拉伯语拼写的推文。这种技术在查找外语用户名时非常重要。

谷歌新闻档案(news.google.com)
这可能是有关目标信息的惊人资源。过去,如果某人搬迁到一个新的地理区域,他或她可以抛开过去,重新开始。如今,这已经很难做到了。谷歌的新闻档案正在不断添加来自在线档案和新闻档案合作伙伴计划的数字化内容。资料来源包括大城市和小城镇的报纸,以及介于两者之间的任何报纸。通过上面提到的链接,可以对目标名称进行详细搜索,筛选条件包括日期、语言和具体出版物。要显示该菜单,请单击搜索框右侧的向下箭头。这可以快速查找目标人物的一些历史信息,如以前的居住地、通过讣告查找家庭成员,以及通过事件、奖项或组织查找相关人员。
9.8 报纸档案
- 谷歌报纸档案(news.google.com/newspapers)
前一个选项只关注数字内容,如本地报纸网站。谷歌报纸档案拥有印刷报纸的内容。该网站上的所有结果都是高分辨率的扫描报纸页面。根据我的经验,该网站收集的内容不如下一个选项广泛。
不过,它绝对值得一看,而且很可能会继续增加。
- 报纸档案 (newspaperarchive.com)
这项付费服务提供世界上最大的报纸档案收藏。整份日报的高分辨率 PDF 扫描件的日期从 19 世纪至今不等。本书的前四版介绍了一种使用谷歌网站操作员和缓存结果的方法,几乎可以在不付费或不订阅的情况下获得该报纸合集的任何页面。这些漏洞都已被修补,如今这些技术都无法使用。幸运的是,Newspaper Archive 仍然提供为期 14 天的免费试用,可以无限制地访问每个档案。虽然可以多次试用,但每次试用都需要唯一的信用卡号和电子邮件地址。许多图书馆已要求这项服务扫描其全部缩微胶片档案,并在网上免费提供。在他们的主页上找不到任何关于这种免费替代方法的介绍,但稍加搜索就能找到正确的地方。在谷歌上进行以下搜索,可以找到数百家付费供您访问其档案的公共图书馆。
site:newspaperarchive.com "This archive is hosted by" "create free account"
搜索的第一部分告诉谷歌只查看 newspaperarchive.com 网站。第二部分要求 “本档案由......托管 ”这一精确短语出现在搜索结果中。最后一部分则是仅将无需信用卡即可免费获取的报纸合集分离出来。这就确定了免费提供其馆藏的各个图书馆的登陆页面。虽然您仍然需要通过服务注册,但这些藏书无需付费。考虑一下下面的用法,您可能会在需要时随时免费浏览报纸档案。
2017 年 12 月 13 日,我浏览了 newspaperarchive.com/advancedsearch/,并对爱荷华州锡达拉皮兹市名叫迈克尔-威廉姆斯(Michael Williams)的人进行了高级搜索。Newspaper Archive 显示了来自《锡达拉皮兹公报》的几条结果。点击其中任何一个结果都会提示我创建一个账户,并强迫我输入有效的信用卡号才能继续。在没有付款的情况下,我无法在任何网页上创建账户。相反,我进行了以下谷歌搜索。
site:newspaperarchive.com "This archive is hosted by" "cedar rapids gazette"
第一个结果是直接连接到 crpubliclibrary.newspaperarchive.com。点击该链接后,出现了一个页面,专门用于搜索锡兹拉皮兹和得梅因地区的 40 多份报纸。右上角有一个名为 “创建免费账户 ”的链接。我点击了这个链接,并提供了通用的详细信息和一个空闲的电子邮件地址。现在的会员选择包括一个完全免费的选项,只允许访问爱荷华州的报纸。创建免费在线账户后,我返回到 crpubliclibrary.newspaperarchive.com 门户网站,重复搜索我的目标。每个链接都允许我完全无限制地访问高分辨率图像。
当我仍然登录这个账户时,我浏览了 delawarecolib.newspaperarchive.com,这是与特拉华县图书馆相关的直接页面(我是通过本节最初的谷歌搜索找到的)。
我没有被授权查看这个 ne-wspaper 系列。不过,在点击该页面上的 “创建免费账户 ”后,我输入了与之前向爱荷华州报纸提供的相同数据。在验证了我的电子邮件地址后,我被允许立即访问这一系列报纸。
这种方法无法访问报纸档案馆的所有收藏。不过,它可以为国际上大量的馆藏提供令人惊讶的免费访问。在一个小时的停机时间里,我在能找到的每一个图书馆收藏上都创建了一个免费账户,并在每个账户上使用了相同的凭据。现在,我可以登录到我的单一报纸档案馆账户,并从任何页面浏览网站。当我搜索到感兴趣的报纸时,如果该报纸是免费收藏的,我就可以完全访问。这一切都要归功于当地的图书馆,它们向该网站支付了费用,以便向公众提供免费访问。如果报纸档案馆的免费试用版或图书馆的免费馆藏不能提供足够的内容,可以考虑以下选项。

所有这些选项的搜索功能充其量只能算一般。请务必考虑使用 Google 搜索,如 site:stparchive “michael bazzell”。
9.9 高级搜索
- 谷歌高级搜索(google.com/ advanced_search)
如果本章讨论的搜索运算符看起来过于专业,Google 提供的高级搜索页面可以简化搜索过程。访问上述网站将在网页中显示与输入运算符相同的选项。这将帮助你熟悉这些选项,但了解操作符对以后使用也有好处。高级搜索页面允许你指定搜索的短语,就像搜索中的引号一样。在该页面输入所需的过滤器,就可以使用前面使用过的网站和文件类型运算符。需要注意的是,该页面上的文件类型选项仅限于常用文件类型,而文件类型操作符可以处理许多其他文件扩展名。
- 必应高级搜索(search.yahoo.com/web/advanced)
从技术上讲,必应并不提供与 Google 类似的高级搜索页面。不过,由于雅虎使用必应的搜索,你可以使用雅虎的高级搜索页面作为替代。该页面可以让你轻松创建一个搜索,按照单个术语、精确短语、省略术语、特定域、文件格式和语言进行过滤。
9.10 其他谷歌引擎
谷歌将一些搜索结果分离到专门的小型搜索引擎中。每个搜索引擎都专注于一种独特的互联网搜索类型。以下引擎可能会提供标准谷歌或必应搜索中找不到的结果。虽然这些独特搜索的部分结果会出现在标准的谷歌搜索结果中,但大部分结果会隐藏在主页中。
- 谷歌传记(google.com)
谷歌在 2014 年撤下了最初的博客搜索。它曾经相当有用,主要针对个人网站,尤其是那些拥有博客平台的网站。如今,这只不过是谷歌新闻的一个分节。您可以在任何谷歌新闻结果页面的 “工具 ”选项中的 “新闻 ”菜单下加载 “博客 ”选项。或者,你也可以访问以下地址,用你的搜索条件替换 TEST。
google.com/search?q=TEST&tbm=nws&tbs=nrt:b
上面的网站显示了一个标准的谷歌搜索选项,但搜索结果却大相径庭。在标准的谷歌搜索中,我的名字会出现在第一条结果中,包括我的网站、推特和亚马逊网页。谷歌博客选项显示了几个提到我名字的个人和专业(媒体)博客。这些结果很可能被隐藏在标准的谷歌搜索中。
- 谷歌专利 (google.com/?tbm=pts)
谷歌拥有互联网上最好的专利搜索选项。它允许你在专利的任何领域内搜索整个专利数据库。这对于搜索与专利相关的名称或专利本身的任何细节都很有用。如果您需要更多帮助,谷歌还提供高级专利搜索,网址是 google.com/advanced_patent_search。
- 谷歌学者(scholar.google.com)
Google Scholar 是一个可免费访问的网络搜索引擎,可索引各种出版格式的学术文献全文。它包括欧美最大学术出版商的大多数同行评审在线期刊,以及许多书籍和其他非同行评审期刊。我最喜欢的功能是判例法和法庭记录搜索。我通过这个免费网站找到了许多法院记录,而如果从私人服务机构获得这些记录则需要花钱。
9.11 其他引擎
- 关键词工具(keywordtool.io)
Keyword Tool 显示来自 Google、Bing、YouTube 和 App Store 的自动完成数据。您可能已经注意到,当您输入搜索时,谷歌会迅速提供建议。这就是所谓的自动完成。如果我在 Google 中输入 “macb”,它会提示我从人们输入这些字母时最热门的搜索中进行选择。这些信息可能会引导您搜索与调查相关的新术语。与 Google 相比,Keyword Tool 的优势在于 Google 只提供最热门的五个词条。而 Keyword Tool 则提供十个最受欢迎的词条。此外,您还可以选择不同的国家/地区来区分热门词条。您还可以看到 Google 不显示的类似搜索结果。
- Searx (searx.be)
该网站被视为元爬虫,因为它提供来自谷歌、必应和其他网站的结果。它经常被认为是另一个比较搜索网站,但使用这项服务还有很多其他好处。首先,进行搜索时会提供来自主要搜索引擎的结果,但会删除重复的条目。仅凭这一点,您就可以通过检查谷歌和必应快速进行尽职调查。接下来,在最上面一行的选项中,您可以通过检查图片、新闻和视频部分的结果来重复这一减少重复的选项。任何搜索页面的每个结果旁边都有一个 “缓存 ”链接。点击该链接将通过 Wayback Machine 打开目标网站的缓存页面,而不是打开谷歌或必应的缓存。最后,每个搜索结果旁边的 “代理 ”选项将通过 Searx 提供的代理服务连接到目标网站。这基本上是一层隐私保护,防止网站所有者收集有关你的数据,如你的 IP 地址。
从技术上讲,Searx.me 打开了目标网站,他们的数据将被跟踪,而不是你的数据。对手有办法绕过这种 “匿名性”,但对大多数网站来说,这是一种不错的保护。
与其他服务相比,这项服务的最后一个优点是可以轻松地将搜索结果导出为文件。链接部分显示了下载 csv、json 或 rss 结果文件的选项。csv 选项是一个简单的电子表格,其中包含所有搜索结果的描述和直接链接。我发现当我在短时间内要进行多次搜索,而我又无法在稍后才对结果进行分析时,这个功能很有帮助。
- Exalead (exalead.com/search)
该搜索引擎总部位于巴黎,在美国颇受欢迎。主搜索引擎提供许多热门搜索结果。我发现,没有强大互联网影响力的个人目标在该网站上获得的结果并不多,甚至没有。不过,该网站在两个方面表现出色。它能很好地搜索到包含在文件中提到的目标的文件。其他引擎中使用的 “文件类型 ”运算符在这里也同样有效。Voxalead 是一个 Exalead 搜索引擎,可在音频和视频文件中搜索特定词语。这要归功于语音转文本技术。Voxalead 会在文件的所有语音音频中搜索与所搜索文本相关的内容。搜索结果以时间轴的形式显示。目前,这一新产品的大部分结果都链接到新闻媒体和公共新闻视频文件。
- DuckDuckGo (duckduckgo.com)
这款界面简洁的搜索引擎提供两种独特的服务。它之所以广受欢迎,是因为它不会跟踪用户的任何信息。谷歌等搜索引擎会记录并保存用户的所有搜索历史和访问过的网站。这可能会引起隐私倡导者和敏感调查者的担忧。此外,它还使用维基百科和 Wolfram Alpha 等众包网站的信息来增强传统搜索结果并提高相关性。与更受欢迎的搜索引擎相比,您在这里得到的结果会更少,但结果的准确性会提高。
- startpage(startpage.com)
与 DuckDuckGo 类似,Start Page 也是一个注重隐私的搜索引擎,它不会向传统搜索引擎透露你的连接信息。与 DuckDuckGo 不同的是,Start Page 只包含谷歌搜索结果,而 DuckDuckGo 则是多源协作。这样做的好处是可以使用 Google 的高级搜索选项,同时还能保护你的身份。这包括按日期、图片和视频进行过滤。
另一个好处是可以通过 “代理 ”链接打开任何结果。该选项在每个搜索结果旁边标有 “代理 ”字样,通过 Start Page 的服务器打开链接页面,并在其网站上显示内容。
这样就可以保护你的 IP 地址,防止任何人监控目标网站的连接。虽然这种技术并非万无一失,但它提供了一层有效的保护。我的搜索策略是,每当我需要进行敏感搜索,而又不想将其与我的电脑或互联网连接联系起来时,我就会使用 Start Page。这可能包括涉及高度敏感话题的调查,如精通技术的跟踪者嫌疑人。
- Qwant (qwant.com)
Qwant 试图将多种类型搜索引擎的搜索结果整合到一个页面中。它于 2013 年经过两年的研究。它有一个易于理解的界面,按网页、新闻、图片、视频、Nfaps 和音乐等栏目显示搜索结果。它给人一种谷歌的 “感觉”,布局可以根据自己的喜好进行更改。默认情况下,搜索我自己的名字会得到与谷歌和必应类似的结果。
点击顶部的标签则会出现其他引擎没有的新结果。搜索结果包括 Twitter、Facebook、Linkedin 和 Myspace 上与我同名的人最近发布的帖子。
- millionhort(millionhort.com)
该网站提供了其他搜索引擎所没有的独特功能。您可以选择删除链接到最热门的 100 万个网站的结果。这将消除热门结果,并将重点放在不太知名的网站上。您还可以选择删除排名前 100,000、10,000、1,000 或 100 的结果。
9.12 Tor 搜索引擎
Tor 是一款实现匿名通信的免费软件。其名称是由最初的软件项目名称 “洋葱路由器”(The Onion Router)缩写而来。Tor 引导互联网流量通过一个由六千多个中继器组成的免费的全球志愿者网络,以隐藏用户的位置和使用情况,防止任何人进行网络监控或流量分析。使用 Tor 可以使互联网活动更难被追踪到用户。这也适用于托管在 Tor 网络上的网站。通常,这些网站包括非法毒品商店、儿童色情交换和武器销售。由于这些网站不托管在可公开访问的网络上,因此很难定位和连接。基于 Tor 的搜索引擎和代理可以帮助完成这一过程。
- Ahmia (ahmia.fi)
这是一个非常强大的 Tor 搜索引擎。虽然没有一个引擎可以索引和定位每一个 Tor 网站,但这是我见过的最全面的选择。在搜索 Tor 相关网站时,它应该是第一个使用的引擎。如果通过标准浏览器和连接进行搜索,结果中的链接将无法加载。使用前面讨论过的 Tor 浏览器是使用这项服务的理想方式。
- Tor 链接(tor.link)
该引擎出现于 2022 年,颇有前途。当我搜索 “OSINT”“'1.thin Ahmia ”时,我收到了 5 条结果。同样查询 Tor Link 得到的结果更多。它似乎能很好地索引 Tor 网站,当我查询目标的电子邮件地址时,我收到了许多结果。在我的许多基于 Tor 的调查中,它对 Ahmia 起到了很好的补充作用。
- 洋葱地搜索(onionlandsearchengine.com)
这项服务依赖于谷歌对拥有 URL 代理链接的 Tor 网站的索引。不过,我通过这项工具找到了一些 “隐藏 ”的网站,而这些网站是之前的选项所没有的。
- Tor2Web(www.tor2web.org / onion.ly)
只要你看到 libertygb2nyeyay.onion 这样的 URL,它就是一个 Tor 洋葱网站。如前所述,如果没有连接到 Tor nenvork,就无法直接连接到这些链接。不过,你可以将地址中的
将地址中的“.onion ”替换为“.onion.ly ”即可查看内容。在上例中,导航到 libertygb2nyeyay.onion.ly 网站将使用 Tor2Web 代理服务器显示内容。这会将你与 Tor2web 连接起来,然后 Tor2web 会通过 Tor 与洋葱服务对话,并转发回响应。这对在 Twitter 上查找 Tor 链接很有帮助。
- Tor 搜索网站
我相信一些最强大的 Tor 搜索引擎只存在于 Tor 网络中。你无法通过标准互联网连接访问它们,而且需要使用 Tor 浏览器才能使用。我最喜欢的是 “Torch”,如果连接到 Tor,可以在以下地址找到。
http://torch4st4l57l2u2vr5wqwvwyueucvnrao4xajqr2klmcmicrv7ccaad.onion
由于 Tor2Web 允许我们使用他们的代理,因此我们可以直接导航到以下 Tor2Web 代理地址,连接到 “Torch”,而无需使用 Tor 浏览器。
http://torch4st4l57l2u2vr5wqwvwyueucvnrao4xajqr2klmcmicrv7ccaad.onion.ly这将显示搜索网站的主页,并允许进行关键字搜索。不过,在通过 Tor2Web 代理连接的情况下通过该门户进行搜索会有困难。相反,可以考虑在提交的 URL 中进行搜索。在下面的网址中,我连接到 Tor2Web 搜索引擎的代理,并请求 OSINT 一词的搜索结果页面。
http://torch4st4l57l2u2vr5wqwvwyueucvnrao4xajqr2k1mcmicrv7ccaad.onion.ly/index.php?q=OSINT
这种提交方式要比依靠代理进行搜索并返回一个额外的代理交付页面可靠得多。Torch 的另一个替代品是 Haystack,访问网址是 http://haystak5njsmn2hqkewecpaxetahtwhsbsa64jom2k22z5afxhnpxfid.onion。与前面的查询类似,我们也可以不使用 Tor 浏览器,通过以下标准 URL 搜索该 Tor 服务。
http://torch4st4l57l2u2vr5wqwvwyueucvnrao4xajqr2klmcmicrv7ccaad.onion.ly/index.php?q=OSINT我还在以下 URL 使用 Tor66 取得了有限的成功。
http:// haystak5njsmn2hqkewecpaxetahtwhsbsa64jom2k22z5afxhnpxfid.onion.ly/?q=osint这里介绍的所有选项,以及其他一些选项,都可以在自定义搜索工具中进行自动查询,稍后介绍。请注意,这些网站会经常出现、消失和重新出现。
9.13 搜索引擎集合
我相信我可以用几章的篇幅来介绍当今数以百计的搜索引擎。不过,我还是要向你推荐我所发现的两个最好的搜索引擎集。
- 搜索引擎巨像(searchenginecolossus.com)
该网站几乎收录了所有国家的所有搜索引擎。主页按字母顺序提供了国家列表。每个链接都连接到该国活跃的搜索引擎列表。在搜索美国的主题时,我不会使用这项服务。不过,如果我的目标与某个特定国家关系密切,我总是会通过该网站研究该地区使用的引擎。
- 费根搜索器(faganfinder.com)
该网站提供一个交互式搜索页面,可将您的查询填充到数百个选项中。在字段中输入搜索词,点击数百个按钮中的任何一个即可开始搜索。许多搜索服务都是针对小众用途的,但你可能会在这里找到本章末尾提供的自定义离线搜索工具中没有的有价值的东西。
9.14 FTP 搜索
我认为,文件传输协议 (FTP) 服务器搜索是大多数在线研究人员忽略的互联网最大领域之一。FTP 服务器是具有公共 IP 地址的计算机,用于存储文件。
虽然这些服务器可以通过规定的访问凭证来确保安全,但这种情况很少发生。大多数 FTP 服务器都是公开的,可以通过网络浏览器访问。与十年前相比,使用 FTP 传输文件的总体情况已微乎其微,但服务器仍然大量存在。我更喜欢用手动方式在谷歌上搜索 FTP信息。如前所述,谷歌和必应索引了大多数 FTP 服务器上的公开数据。
为了过滤不需要的信息,需要自定义搜索字符串。如果我要查找标题中包含 “机密 ”一词的任何文件,我会在 Google 和 Bing 上进行以下搜索。
inurl:ftp -inurl (http|https) "confidential"
搜索结果将只包括来自 ftp 服务器的文件(inurl:ftp);不包括任何网页(-inurl: (http I https));并强制要求出现 “机密 ”一词(“”)。我用这个查询找到了目标公司的许多敏感文件。上述搜索得到了 107,000 个 FTP 结果。然而,这些具体的搜索结果并不是唯一有价值的数据。请看下面的例子。我想查找存储在 FTP 服务器上、标题或内容中包含 “cisco ”的 PDF 文档,并在 Google 上进行了如下搜索。
inurl:ftp -inurl (http|https) "cisco" filetype:pdf
结果在多个域托管的多个 FTP 服务器中找到了 20,000 个选项。第一个结果托管在西南数码港 FTP 服务器上,并连接到以下地址的 PDF 文档。它似乎是教科书的一个章节。
ftp://ftp.swcp.com/pub/cisco/03chap01.pdf
手动将最后一个 “01 ”改为 “02”,即可加载该书的第二章。不过,更简单的方法是完全去掉文档名称,浏览名为 “cisco ”的目录。以下第一个地址显示的是该文件夹的内容,第二个地址显示的是 “pub ”文件夹的内容。将这些地址直接复制到网络浏览器中即可查看结果。
ftp://ftp.swcp.com/pub/cisco/
ftp://ftp.swcp.com/pub/
这种手动导航方式往往能发现大量传统搜索无法发现的公开文件。我已经找到了由公司、政府机构和军方托管的极其敏感的文件。
大多数文件传输协议(FTP)服务器都已被谷歌收录,但还有其他值得探索的第三方选择。在每条描述的末尾,我都会标明搜索结果的数量"Cisco" "PDF"。
- Napalm FTP(searchftps.org)
这个 FTP 搜索引擎经常提供最新的内容。在每个结果之后,它都会显示数据在所披露位置的最后确认日期。这有助于查找服务器上仍然存在的相关信息。在所有四项服务中,该引擎生成的结果最多,但其中许多结果在目标 FTP 服务器上已不可用。有些可以通过缓存副本重建,但并非全部。
"Cisco" "PDF": 3,384
- NMamoht (mmnt.ru)
通过这个俄罗斯 FTP 服务器,您可以根据托管内容的国家隔离搜索结果。这可能是由 IP 地址决定的。虽然大多数过滤后的结果都是准确的,但我建议在排除任何外国选项之前先搜索一下全球结果。我最喜欢这个引擎的功能是 “结果内搜索 ”选项。在进行搜索后,我选中了该选项,搜索栏被清空。我输入 “路由器”,然后再次点击搜索。在我最初的搜索结果中,出现了 436 个也包含路由器一词的结果。虽然这本可以手动复制,但我还是很感谢这个选项。
"Cisco" "PDF": 789
相比之下,Google 找到了 19,600 个 inurl:ftp -inurl: (http I https) “Cisco” “PDF” 的结果。
- FreewareWeb (freewareweb.com/ftpsearch.shtml)
这项服务不如前面的选项那么强大,但也不容忽视。2022 年,我在搜索具有唯一文件扩展名的文档。这是唯一能提供我所需文件的服务,这些文件是我的目标签署的合同。
- Nerdy Data(nerdydata.com/reports/new)
谷歌、必应和其他搜索引擎搜索网站内容。它们关注的是网页中直观呈现的数据。Nerdy Data 搜索的是网站的程序代码。最终用户通常看不到这些代码,它们存在于大多数用户并不熟悉的 HTML 代码、JavaScript 和 CSS 文件中。在某些情况下,这些代码对研究极有价值。右击页面背景并选择 “查看源代码”,即可查看网站的源代码。下面的两个示例可以说明这项服务的一小部分功能。
在后面的章节中,你将了解到一些免费服务,这些服务可以尝试识别与目标网站相关的其他网站。这些服务的支柱依赖于网站编程数据的索引。
Nerdy Data 可能是搜索这些数据的最纯粹的方法。如果你查看我以前的一个网站(已不在网上)的源代码,你会在底部看到我使用了一种名为 Google Analytics 的服务。这项服务可以识别网站的访客数量以及访客所在的大致区域。
以下是实际存在的代码。
<script type="text/javascript">
try {var pageTracker = _gat._getTracker("UA-8231004-3");
pageTracker._trackPageview();
} catch(err) {}</script>
这里的重要数据是“UA-8231004-3”。这是我在 Google Analytics 中得到的唯一编号。任何我使用该服务的网站都需要在页面源代码中包含该编号。如果您几年前在 Nerdy Data 上搜索该编号,您会得到有趣的结果。Nerdy Data 之前确定了三个使用该编号的网站,包括 computercrimeinfo.com 和我为一家律师事务所维护的另外两个网站。您通常可以在目标网站的源代码中找到有价值的信息。
许多网页设计师和程序员会从其他网站窃取代码。在过去,如果不知道可疑网站,很难识别这种情况。使用 Nerdy Data,您可以搜索相关代码并确定在其源代码中包含数据的网站。2013 年,我在 YGN 道德黑客小组找到了一个自定义搜索网站,这启发了我创建自己的类似搜索服务。我很好奇是否还有其他搜索网站拥有这个基本代码,这可能会给我更多的想法。
我查看了该网站的源代码,并找到了一小段代码,该代码似乎是该服务所特有的。我在 Nerdy Data 上搜索了以下代码。
但是,四个结果确定了类似的搜索服务,它们也使用搜索到的编程代码。这揭示了与我感兴趣的网站相关的新搜索服务。
同样的技术可用于识别窃取专有代码的网站;找到那些试图欺骗受害者使用克隆网站的页面;或者验证全球黑客网站上使用的特定编程功能的流行程度。
- IntelTechniques 搜索引擎工具
此时,您可能会被大量的搜索选项所淹没。我对此深有体会,而且我不会在每次调查中都利用每个选项。在对目标进行初步搜索时,我喜欢依靠基本功能。我首先搜索 Google、Bing、Yandex 和较小的搜索引擎。为了协助进行初步搜索,我创建了一个自定义工具,可让您快速了解基础知识。下图显示了此工具的当前状态,您可以在下载中或在 https:/ /inteltechniques.com/tools 上找到该工具。搜索选项将允许您直接通过 Google、Bing、Yahoo、Searx、Yandex 和许多其他网站进行单独搜索。
在所有选项中,您进行的每次搜索都将在浏览器的新选项卡中打开。搜索全部
在您的计算机上的浏览器中进行,直接搜索来源。
“提交全部”选项将允许您提供将在列出的所有服务中进行搜索的任何搜索词。每项服务都将在您的互联网浏览器的新选项卡中填充结果。无论您使用哪种浏览器,都必须允许弹出窗口才能使该工具正常工作。您还可以使用此工具中之前讨论过的任何搜索运算符,包括引号。我在大多数章节的末尾都提供了一个类似的搜索工具,它总结并简化了所解释技术的查询过程。我鼓励您熟悉其中的每一个。一旦熟练,您可以在几分钟内查询所有选项的目标数据。这每周为我节省了几个小时。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号