
掌握嵌入式Linux编程3引导程序
3引导程序
引导程序是嵌入式Linux的第二个要素。它是启动系统和加载操作系统内核的部分。在这一章中,我们将研究引导程序的作用,特别是它如何使用一种叫做设备树的数据结构将控制权从自身传递给内核,设备树也被称为扁平化设备树或FDT(flattened device tree)。我将介绍设备树的基本知识,因为这将帮助你遵循设备树中描述的连接,并将其与真实的硬件联系起来。
我将研究流行的开源引导程序U-Boot的,并向你展示如何使用它来引导目标设备,以及如何通过使用BeagleBone Black作为例子来定制它,使它能够运行在新设备上。
在本章中,我们将介绍以下内容:
- Bootloader是做什么的?
- 启动顺序
- 从引导程序转移到内核
- 设备树
- U-Boot
引导程序是做什么的?
在嵌入式Linux系统中,引导程序有两项主要工作:将系统初始化到基本level和加载内核。事实上,第一项工作在某种程度上是附属于第二项工作的,因为它只需要让系统工作到加载内核所需的程度。
当启动程序代码的第一行被执行时,在开机或复位之后,系统处于非常小的状态。DRAM控制器没有被设置,所以主存储器不能被访问。同样,其他接口也没有被配置,所以通过NAND闪存控制器、MMC控制器等访问的存储是不可用的。通常情况下,开始时唯一可以运行的资源是单个CPU核心、一些片上静态存储器和启动ROM。
系统引导由几个阶段的代码组成,每个阶段都会使更多的系统进入运行状态。引导程序的最终行为是将内核加载到RAM中并为其创造执行环境。引导程序和内核之间的接口细节是针对特定的架构的,但在每一种情况下,它都必须做两件事。首先,bootloader必须传递指针到包含硬件配置信息的结构。第二,它必须传递指向内核命令行的指针。
内核命令行是控制Linux行为的文本字符串。一旦内核开始执行,就不再需要bootloader了,它所使用的所有内存都可以被回收。
Bootloader 的一个附属工作是提供维护模式,用于更新 Boot 配置,将新的 Boot Image 加载到内存中,也可能用于运行诊断程序。这通常是由简单的命令行用户界面控制的,通常是通过串行控制台。
启动顺序
几年前,只需要在处理器的复位矢量处把引导程序放在非易失性存储器中。当时 NOR 闪存很普遍,由于它可以直接映射到地址空间,所以是理想的存储方法。下图显示了这样的配置,复位向量位于闪存区域的上端0xfffffffc处。Bootloader被连接起来,所以在这个位置有一条跳转指令,指向Bootloader代码的开始:
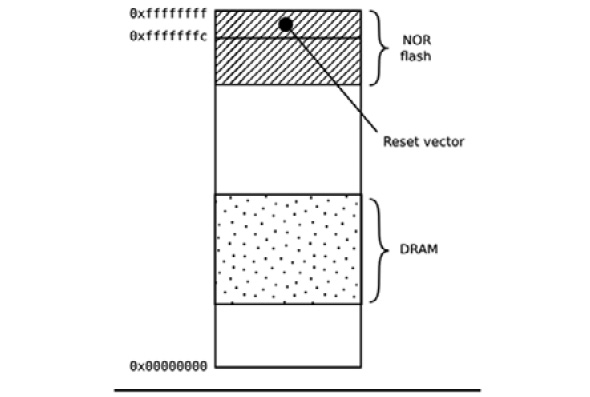
从那时起,在NOR闪存中运行的引导程序代码可以初始化DRAM控制器,使主存储器--DRAM--变得可用,然后将自己复制到DRAM中。一旦完全运行,引导程序可以将内核从闪存加载到DRAM中,并将控制权转移给它。
然而,一旦你离开了简单的可线性寻址的存储介质,如NOR闪存,启动序列就会变成复杂的多阶段程序。每个SoC的细节都是非常具体的,但它们一般都遵循以下各个阶段。
第1阶段--ROM代码
在没有可靠的外部存储器的情况下,复位或开机后立即运行的代码必须被存储起来。
复位或上电的过程必须存储在SoC的片上;这被称为ROM代码。它在制造时被加载到芯片中,因此,ROM代码是专有的,不能被开放源码的等同物所取代。通常,它不包括初始化存储器控制器的代码,因为DRAM的配置是高度特定于设备的,所以它只能使用静态随机存取存储器(SRAM Static Random Access Memory ),它不需要存储器控制器。
大多数嵌入式SoC设计都有少量的片上SRAM,大小从4KB到几百KB不等:
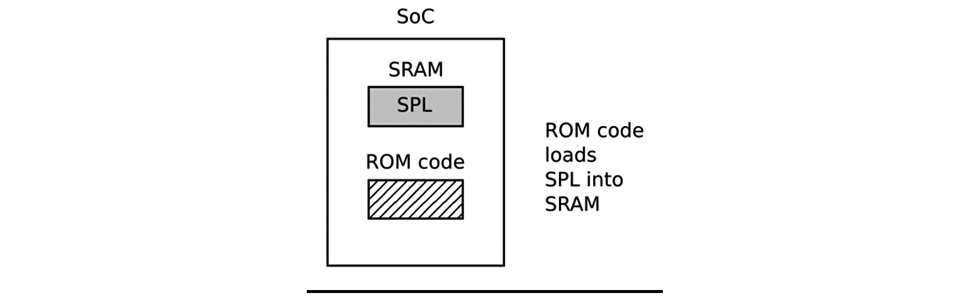
ROM代码能够从几个预编程的位置之一加载一小块代码到SRAM中。举例来说,TI OMAP和Sitara芯片试图从NAND闪存的前几页加载代码,或从通过串行外设接口(SPI Serial Peripheral Interface)连接的闪存,或从MMC设备(可能是eMMC芯片或SD卡)的第一个扇区,或从MMC设备的第一个分区上名为MLO的文件。如果它从所有这些存储器设备中读取失败,那么它就会尝试从以太网、USB或UART中读取字节流;后者主要是作为生产过程中向闪存加载代码的手段,而不是用于正常操作。大多数嵌入式SoC都有以类似方式工作的ROM代码。在SoC中,如果SRAM不够大,无法加载完整的引导程序,如U-Boot,就必须有一个中间的加载器,称为二级程序加载器(SPL)。
在ROM代码阶段结束时,SPL(secondary program loader)存在于SRAM中,ROM代码会跳到该代码的开头。
第2阶段--二级程序加载器
SPL必须设置内存控制器和系统的其他基本部分,以准备将三级程序加载器(TPL Tertiary Program Loader)加载到DRAM中。SPL的功能受限于SRAM的大小。它可以从存储设备的列表中读取程序,就像ROM代码一样,再次使用从闪存设备开始的预编程偏移量。如果SPL内置了文件系统驱动程序,它可以从磁盘分区中读取知名的文件名,如u-boot.img。SPL通常不允许任何用户互动,但它可以打印版本信息和进度信息,你可以在控制台看到。下图解释了第二阶段的结构:
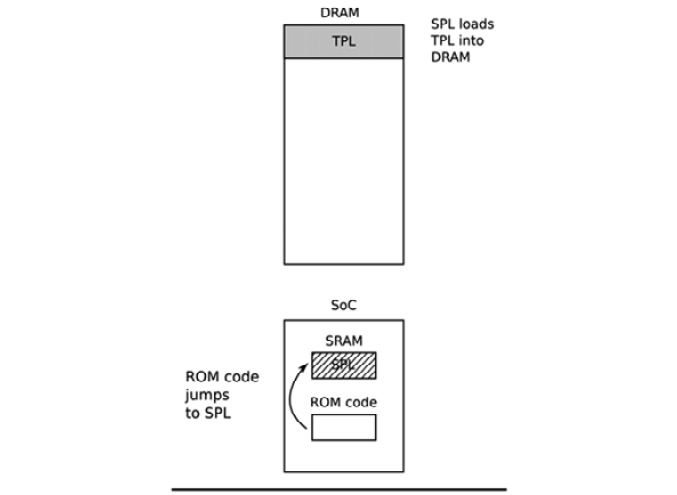
前面的图显示了从ROM代码跳到SPL的过程。当SPL在SRAM内执行时,它将TPL加载到DRAM中。在第二阶段结束时,TPL存在于DRAM中,而SPL可以跳转到该区域。
SPL可能是开源的,如TI x-loader和Atmel AT91Bootstrap的情况,但它包含由制造商提供的二进制blob的专有代码是很常见的。
第三阶段--TPL
在这一点上,我们正在运行一个完整的引导程序,例如U-Boot,我们将在本章的后面了解一下它。通常,有简单的命令行用户界面,可以让你执行维护任务,比如将新的引导和内核映像加载到闪存中,以及加载和启动内核,还有一种方法是自动加载内核而不需要用户干预。
下图解释了第三阶段的架构:
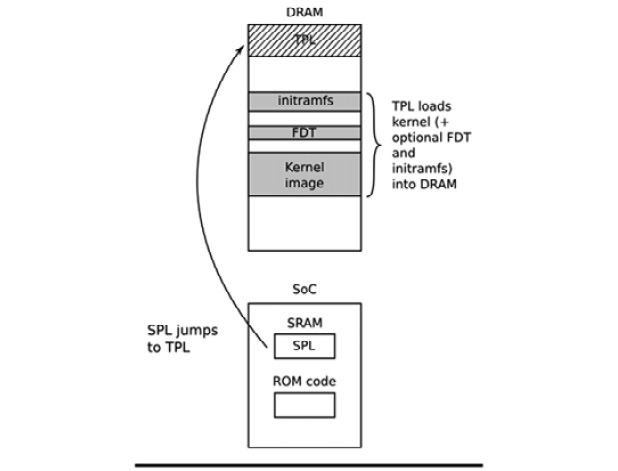
前面的图显示了从SRAM中的SPL到DRAM中的TPL的跳跃过程。随着TPL的执行,它将内核加载到DRAM中。如果我们愿意,我们还可以选择在DRAM中的映像上附加一个FDT和/或初始RAM磁盘。无论哪种方式,在第三阶段结束时,内存中都有一个内核,等待被启动。
一旦内核开始运行,嵌入式引导程序通常会从内存中消失,不再参与系统的运行。在这之前,TPL需要把启动过程的控制权交给内核。
从 Bootloader 转移到 kernel
当引导程序将控制权交给内核时,它必须传递一些基本信息,其中包括以下内容:
- 机器号,在不支持设备树的PowerPC和Arm平台上使用,用来识别SoC的类型。
- 到目前为止已经检测到的硬件的基本细节,包括(最起码)物理RAM的大小和位置以及CPU的时钟速度。
- 内核命令行。
- 可选的,设备树二进制的位置和大小。
- 可选,初始RAM磁盘的位置和大小,称为初始RAM文件系统(initramfs)。
内核命令行是一个普通的ASCII字符串,通过给出例如包含根文件系统的设备名称来控制Linux的行为。我们将在下一章讨论这个问题的细节。将根文件系统作为RAM盘提供是很常见的,在这种情况下,引导程序有责任将RAM盘镜像加载到内存中。我们将在第五章 "构建根文件系统 "中介绍如何创建初始RAM磁盘。
这种信息的传递方式取决于体系结构,并且在最近几年有所改变。例如,对于PowerPC,引导程序只是简单地传递一个指向电路板信息结构的指针,而对于Arm,它传递一个指向A标签列表的指针。在文档/arm/Booting的内核源中,对A标签的格式有一个很好的描述。
在这两种情况下,所传递的信息量都非常有限,大部分信息都是在运行时发现的,或者作为平台数据硬编码到内核中。平台数据的广泛使用意味着每个板子都必须有一个为该平台配置和修改的内核。我们需要一个更好的方法,这个方法就是设备树。在Arm世界中,随着Linux 3.8的发布,从A标签的转变开始认真进行。今天,几乎所有的Arm系统都使用设备树来收集硬件平台的具体信息,允许单一的内核二进制文件在广泛的这些平台上运行。
现在我们已经了解了引导程序的作用,引导序列的阶段是什么,以及它如何将控制权传递给内核,让我们学习如何配置引导程序,使其在流行的嵌入式SoC上运行。
介绍设备树
如果你正在使用Arm或PowerPC SoC,你几乎肯定会在某个时候遇到设备树。本节旨在让你快速了解它们是什么以及它们是如何工作的。在本书过程中,我们将反复讨论设备树的话题。
设备树是定义计算机系统硬件组件的一种灵活方式。请记住,设备树只是静态数据,不是可执行代码。通常,设备树由引导程序加载并传递给内核,尽管有可能将设备树与内核镜像捆绑在一起,以满足不能单独加载的引导程序。
这个格式来自于Sun Microsystems公司的OpenBoot的引导程序,它被正式确定为Open Firmware规范,也就是IEEE标准IEEE1275-1994。它被用于基于PowerPC的Macintosh电脑中,因此是PowerPC Linux端口的合理选择。从那时起,它已经被许多Arm Linux实现大规模采用,在较小的程度上,被MIPS、MicroBlaze、ARC和其他架构采用。
我建议访问https://www.devicetree.org,了解更多信息。
设备树基础知识
Linux内核在arch/$ARCH/boot/dts中包含了大量的设备树源文件,这是学习设备树的好的起点。在arch/$ARCH/dts的U-boot源代码中也有少量的源文件。如果你的硬件是从第三方购买的,dts文件是板卡支持包的一部分,所以你应该期望和其他源文件一起收到。
设备树将计算机系统表示为以层次结构连接在一起的组件的集合,如一棵树。设备树以根节点开始,根节点用正斜杠/表示,它包含代表系统硬件的后续节点。每个节点都有一个名称,并包含一些名称="值 "形式的属性。下面是简单的例子:
/dts-v1/;
/{
model = "TI AM335x BeagleBone";
compatible = "ti,am33xx";
#address-cells = <1>;
#size-cells = <1>;
cpus {
#address-cells = <1>;
#size-cells = <0>;
cpu@0 {
compatible = "arm,cortex-a8";
device_type = "cpu";
reg = <0>;
};
};
memory@0x80000000 {
device_type = "memory";
reg = <0x80000000 0x20000000>; /* 512 MB */
};
};
这里,我们有一个根节点,它包含一个cpus节点和一个内存节点。cpus节点包含一个名为cpu@0的CPU节点。这些节点的名字通常包括一个@,后面是一个地址,用来区分该节点和其他同类型的节点。如果节点有reg属性,@是必须的。
根节点和CPU节点都有一个兼容属性。Linux内核使用这个属性,通过与每个设备驱动程序在of_device_id结构中输出的字符串进行比较,找到一个匹配的设备驱动程序(更多信息请参见第11章,与设备驱动程序的接口)。
按照惯例,兼容属性的值由制造商名称和组件名称组成,以减少不同制造商制造的类似设备之间的混淆;因此,ti,am33xx和arm,cortex-a8。如果有一个以上的驱动程序可以处理这个设备,那么兼容属性有一个以上的值也是很常见的。它们被列在第一位,最合适的被提到。
CPU节点和内存节点有一个device_type属性,它描述了设备的类别。节点名称通常从device_type派生。
reg属性
前面显示的内存和CPU节点有一个reg属性,它指的是寄存器空间中的单位范围。reg属性由两个值组成,分别代表实际物理地址和范围的大小(长度)。这两个值都被写成零或多个32位整数,称为单元。因此,前面的内存节点指的是从0x80000000开始、长度为0x20000000字节的单组内存。
当地址或大小值不能用32位表示时,理解寄存器的属性就变得更加复杂。例如,在具有64位寻址的设备上,你需要为每个单元格设置两个:
/{
#address-cells = <2>;
#size-cells = <2>;
memory@80000000 {
device_type = "memory";
reg = <0x00000000 0x80000000 0 0x80000000>;
};
};
关于所需单元格数量的信息被保存在祖先节点的#address-cells和#size_cells属性中。换句话说,要理解一个reg属性,你必须在节点层次结构中向后看,直到找到#address-cells和#size_cells。如果没有的话,每一个的默认值都是1--但是对于设备树编写者来说,依赖默认值是不好的做法。
现在,让我们回到cpu和cpus的节点上。CPU也有地址;在一个四核设备中,它们可能被编为0、1、2和3。这可以被认为是没有任何深度的一维数组,所以大小为零。因此,你可以看到我们在cpus节点中有#address-cell = <1>和#size-cells = <0>,而在子节点cpu@0中,我们为reg属性分配了一个值,reg = <0>。
标签和中断
到目前为止,我们所描述的设备树的结构假定有单一的组件层次,而事实上,有几个。除了组件与系统其他部分之间明显的数据连接外,它还可能与中断控制器、时钟源和电压调节器相连接。为了表达这些连接,我们可以给节点添加一个标签,并从其他节点引用该标签。这些标签有时被称为phandles,因为当设备树被编译时,从另一个节点引用的节点被分配了一个独特的数值,这个属性称为phandle。如果你反编译设备树的二进制文件,你可以看到它们。
以一个包含可以产生中断的LCD控制器和一个中断控制器的系统为例:
/dts-v1/;
{
intc: interrupt-controller@48200000 {
compatible = "ti,am33xx-intc";
interrupt-controller;
#interrupt-cells = <1>;
reg = <0x48200000 0x1000>;
};
lcdc: lcdc@4830e000 {
compatible = "ti,am33xx-tilcdc";
reg = <0x4830e000 0x1000>;
interrupt-parent = <&intc>;
interrupts = <36>;
ti,hwmods = "lcdc";
status = "disabled";
};
};
在这里,我们有一个interrupt-controller@48200000节点,标签为intc。interrupt-controller属性将其标识为中断控制器。像所有的中断控制器一样,它有一个#interrupt-cell属性,它告诉我们需要多少个单元来表示中断源。在这种情况下,只有一个表示中断请求(IRQ)号码。其他中断控制器可能会使用额外的单元来描述中断的特征;例如,指示它是边缘触发还是电平触发。中断单元的数量和它们的含义在每个中断控制器的绑定中都有描述。设备树的绑定可以在Linux内核源文件/devicetree/bindings/目录下找到。
看一下lcdc@4830e000节点,它有interrupt-parent属性,使用标签引用它所连接的中断控制器。它还有一个interrupts属性,在这种情况下是36。注意,这个节点有它自己的标签,lcdc,它被用在其他地方:任何节点都可以有一个标签。
设备树包含文件
很多硬件在同一家族的SoC之间和使用同一SoC的板子之间是通用的。这反映在设备树中,就是将共同的部分分割成包含文件,通常以.dtsi为扩展名。开放固件标准将/include/定义为要使用的机制,如vexpress-v2p-ca9.dts中的这个片段:
/include/ "vexpress-v2m.dtsi"
不过,翻看内核中的.dts文件,你会发现一个从C语言中借用的替代性包含语句;例如,在am335x-boneblack.dts中:
#include "am33xx.dtsi"
#include "am335x-bon-common.dtsi"
下面是am33xx.dtsi的另一个例子:
#include <dt-bindings/gpio/gpio.h>
#include <dt-bindings/pinctrl/am33xx.h>
#include <dt-bindings/clock/am3.h>.
最后,include/dt-bindings/pinctrl/am33xx.h包含正常的C语言宏:
#define PULL_DISABLE (1 << 3)
#define INPUT_EN (1 << 5)
#define SLEWCTRL_SLOW (1 << 6)
#define SLEWCTRL_FAST 0
如果使用Kbuild系统构建设备树源码,所有这些都可以解决,该系统通过C预处理器CPP运行,其中的#include和#define语句被处理成适合设备树编译器的文本。这个动机在前面的例子中已经说明了;它意味着设备树源可以使用与内核代码相同的常量定义。
当我们包含文件时,使用任何一种语法,节点都会叠加在一起,形成复合树,外层扩展或修改内层。例如,am33xx.dtsi是所有am33xx SoC的通用文件,它定义了第一个MMC控制器接口,像这样:
mmc1: mmc@48060000 {
compatible = "ti,omap4-hsmmc";
ti,hwmods = "mmc1";
ti,dual-volt;
ti,needs-special-reset;
ti,needs-special-hs-handling;
dmas = <&edma_xbar 24 0 0
&edma_xbar 25 0 0>;
dma-names = "tx", "rx";
interrupts = <64>;
reg = <0x48060000 0x1000>;
status = "disabled";
};
请注意,status是禁用的,这意味着没有设备驱动程序应该被绑定到它,而且它的标签是mmc1。
BeagleBone和BeagleBone Black都有连接到mmc1的microSD卡接口。这就是为什么在am335x-bon-common.dtsi中,同一个节点被其标签所引用;也就是&mmc1:
&mmc1 {
status = "okay";
bus-width = <0x4>;
pinctrl-names = "default";
pinctrl-0 = <&mmc1_pins>;
cd-gpios = <&gpio0 6 GPIO_ACTIVE_LOW>;
};
状态属性被设置为OK,这使得MMC设备驱动在BeagleBone的两个变体上运行时与这个接口绑定。同时,在引脚控制配置mmc1_pins中添加了标签的引用。唉,这里没有足够的空间来描述引脚控制和引脚复用。你可以在Linux内核源码中的Documentation/devicetree/bindings/pinctrl目录下找到一些信息。
然而,mmc1接口在BeagleBone Black上连接到一个不同的电压调节器。这在am335x-boneblack.dts中表示,你会看到另一个对mmc1的引用,它通过vmmcsd_fixed标签将其与电压调节器联系起来:
&mmc1 {
vmmc-supply = <&vmmcsd_fixed>;
};
所以,像这样将设备树的源文件分层,给了我们灵活性,并减少了对重复代码的需求。
编译设备树
Bootloader和内核需要设备树的二进制表示,所以必须使用设备树编译器来编译,也就是DTC。结果是以.dtb结尾的文件,它被称为设备树二进制或设备树blob。
在Linux源代码中的scripts/dtc/dtc中有dtc的副本,它也可以作为软件包在许多Linux发行版中使用。你可以用它来编译简单的设备树(不使用#include的设备树),像这样:
$ dtc simpledts-1.dts -o simpledts-1.dtb
DTC: dts->dts on file "simpledts-1.dts"
要注意的是,DTC不会给出有用的错误信息,而且除了语言的基本语法外,不会做任何检查,这意味着调试源文件中的输入错误可能是一个漫长的过程。
要建立更复杂的例子,你必须使用Kbuild内核,如第4章 "配置和建立内核 "中所示。
像内核一样,引导程序可以使用设备树来初始化嵌入式SoC及其外围设备。当你从大容量存储设备(如QSPI闪存)加载内核时,这个设备树是至关重要的。虽然嵌入式Linux提供了多种引导程序的选择,但我们将只介绍一种。接下来我们将深入探讨这个引导程序。
U-Boot
我们将专门讨论U-Boot,因为它支持大量的处理器架构和大量的单板和设备。它已经存在了很长时间,并且有很好的社区来支持。
U-Boot,或者说它的全名是Das U-Boot,开始时是用于嵌入式PowerPC板的开放源码引导程序。然后,它被移植到基于Arm的板子上,后来又移植到其他架构上,包括MIPS和SH。它是由Denx软件工程公司主持和维护的。有很多关于它的信息,好的开始是https://www.denx.de/wiki/U-Boot。在u-boot@lists.denx.de,也有一个邮件列表,你可以通过填写和提交https://lists.denx.de/listinfo/u-boot 提供的表格来订阅。
构建U-Boot
从获取源代码开始。和大多数项目一样,推荐的方法是克隆.git档案,并查看你打算使用的标签--在这种情况下,它是编写时的版本:
$ git clone git://git.denx.de/u-boot.git
$ cd u-boot
$ git checkout v2021.01
另外,你也可以从ftp://ftp.denx.de/pub/u-boot,得到一个tarball。
在configs/目录下有超过1000个常见开发板和设备的配置文件。在大多数情况下,你可以根据文件名来猜测使用哪个文件,但你可以通过查看board/目录下每个板子的README文件来获得更详细的信息,或者你可以在适当的网络教程或论坛中找到信息。
以BeagleBone Black为例,我们会发现可能有一个名为configs/am335x_evm_defconfig的配置文件,以及文本 本板产生的二进制文件支持 ... Beaglebone Black在板子的README文件中的am335x芯片,board/ti/am335x/README。有了这些知识,为BeagleBone Black构建U-Boot就很简单了。你需要通过设置CROSS_COMPILE make变量来通知U-Boot你的交叉编译器的前缀,然后用make [board]_defconfig类型的命令来选择配置文件。因此,要使用我们在第2章 "学习工具链 "中创建的Crosstool-NG编译器来构建U-Boot,你应该输入以下内容:
$ source ../MELP/Chapter02/set-path-arm-cortex_a8-linux-gnueabihf
$ make am335x_evm_defconfig
$ make
``
编译的结果如下:
- u-boot: ELF对象格式的U-Boot,适合与调试器一起使用
- u-boot.map: 符号表
- u-boot.bin: 原始二进制格式的U-Boot,适合在你的设备上运行
- u-boot.img: 这是添加了U-Boot头的u-boot.bin,适合上传到正在运行的U-Boot副本中。
- u-boot.srec: 摩托罗拉S-记录(SRECORD或SRE)格式的U-Boot,适合通过串行连接传输。
BeagleBone Black还需要一个二级程序加载器(SPL secondary program loader),如前所述。这也是同时建立的,被命名为MLO:
```sh
$ ls -l MLO u-boot*
-rw-rw-r- 1 frank frank 108260 Feb 8 15:24 MLO
-rwxrwxr-x 1 frank frank 6028304 Feb 8 15:24 u-boot
-rw-rw-r- 1 frank frank 594076 Feb 8 15:24 u-boot.bin
-rw-rw-r- 1 frank frank 20189 Feb 8 15:23 u-boot.cfg
-rw-rw-r- 1 frank frank 10949 Feb 8 15:24 u-boot.cfg.configs
-rw-rw-r- 1 frank frank 54860 Feb 8 15:24 u-boot.dtb
-rw-rw-r- 1 frank frank 594076 Feb 8 15:24 u-boot-dtb.bin
-rw-rw-r- 1 frank frank 892064 Feb 8 15:24 u-boot-dtb.img
-rw-rw-r- 1 frank frank 892064 Feb 8 15:24 u-boot.img
-rw-rw-r- 1 frank frank 1722 Feb 8 15:24 u-boot.lds
-rw-rw-r- 1 frank frank 802250 Feb 8 15:24 u-boot.map
-rwxrwxr-x 1 frank frank 539216 Feb 8 15:24 u-boot-nodtb.bin
-rwxrwxr-x 1 frank frank 1617810 Feb 8 15:24 u-boot.srec
-rw-rw-r- 1 frank frank 211574 Feb 8 15:24 u-boot.sym
其他目标的程序也类似。
安装U-boot
第一次在板子上安装引导程序需要一些外部协助。如果板子有硬件调试接口,比如JTAG(联合测试行动组 Joint Test Action Group),通常可以把U-Boot的拷贝直接加载到RAM中并使其运行。在这一点上,你可以使用U-Boot命令,使它自己复制到闪存中。这方面的细节与电路板有关,不在本书的讨论范围之内。
许多SoC设计都有一个内置的引导ROM,可以用来从各种外部来源读取引导代码,如SD卡、串行接口或USB大容量存储。BeagleBone Black中的am335x芯片就是这种情况,这使得尝试新软件变得很容易。
你将需要SD卡读卡器来把image写入卡中。有两种类型:插入USB端口的外部读卡器,以及许多笔记本电脑上都有的内部SD读卡器。当卡被插入读卡器时,Linux会分配一个设备名称。lsblk命令是一个有用的工具,可以找出哪个设备已经被分配。例如,当我把一张标称8GB的microSD卡插入读卡器时,我看到的就是这个:
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 1 7.4G 0 disk
└─sda1 8:1 1 7.4G 0 part /media/frank/6662-6262
nvme0n1 259:0 0 465.8G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part /boot/efi
├─nvme0n1p2 259:2 0 16M 0 part
├─nvme0n1p3 259:3 0 232.9G 0 part
└─nvme0n1p4 259:4 0 232.4G 0 part /
在这种情况下,nvme0n1是我的512GB硬盘,sda是microSD卡。它有单一的分区,sda1,它被挂载为/media/frank/6662-6262目录。
在这种情况下,microSD卡显示为mmcblk0,分区为mmcblk0p1。注意,你使用的microSD卡的格式化方式可能与此不同,所以你可能会看到不同数量的分区和不同的挂载点。在格式化SD卡时,确定其设备名称是非常重要的。你真的不想把你的硬盘误认为是SD卡,而去格式化它。这种情况已经不止一次发生在我身上了。因此,我在本书的代码档案中提供了名为MELP/format-sdcard.sh的shell脚本,它有合理数量的检查以防止你(和我)使用错误的设备名称。参数是microSD卡的设备名,在第一个例子中是sdb,在第二个例子中是mmcblk0。下面是它的一个使用例子:
$ MELP/format-sdcard.sh mmcblk0
该脚本创建了两个分区:第一个是64 MiB,格式为FAT32,将包含引导程序;第二个是1 GiB,格式为ext4,你将在第5章建立根文件系统中使用它。当脚本应用于任何大于32GiB的驱动器时,它就会中止,所以如果你使用更大的microSD卡,要准备好修改它。
一旦你格式化了microSD卡,就把它从读卡器中取出来,然后重新插入,这样分区就会自动挂载。在当前版本的Ubuntu上,这两个分区应该被安装为/media/[user]/boot和/media/[user]/rootfs。现在,你可以把SPL和U-Boot复制到它,像这样:
$ cp MLO u-boot.img /media/frank/boot
最后,卸载它:
$ sudo umount /media/frank/boot
现在,在BeagleBone板上没有电源的情况下,将microSD卡插入读卡器。插上串行电缆。在你的电脑上应该出现一个串口,即/dev/ttyUSB0。启动一个合适的终端程序,如gtkterm、minicom或picocom,并以每秒115200比特(bps)的速度连接到该端口,没有流量控制。gtkterm可能是最容易设置和使用的:
$ gtkterm -p /dev/ttyUSB0 -s 115200
如果你得到权限错误,那么你可能需要把自己加入拨出组,并重新启动以使用这个端口。
按住BeagleBone Black上的启动开关按钮(离microSD插槽最近),使用外部5V电源连接器给电路板供电,大约5秒钟后释放按钮。你应该在串行控制台看到一些输出,然后是U-Boot提示:
U-Boot SPL 2021.01 (Feb 08 2021 - 15:23:22 -0800)
Trying to boot from MMC1
U-Boot 2021.01 (Feb 08 2021 - 15:23:22 -0800)
CPU : AM335X-GP rev 2.1
Model: TI AM335x BeagleBone Black
DRAM: 512 MiB
WDT: Started with servicing (60s timeout)
NAND: 0 MiB
MMC: OMAP SD/MMC: 0, OMAP SD/MMC: 1
Loading Environment from FAT... *** Warning - bad CRC, using default environment
<ethaddr> not set. Validating first E-fuse MAC
Net: eth2: ethernet@4a100000, eth3: usb_ether
Hit any key to stop autoboot: 0
=>
按键盘上的任意键,停止U-Boot在默认环境下的自动启动。现在我们面前有一个U-Boot的提示,让我们把U-Boot放在它的位置上。
使用U-Boot
在本节中,我将介绍一些常见的任务,你可以使用U-Boot来执行。
通常,U-Boot通过串口提供一个命令行接口。它提供为每个板子定制的命令提示。在这些例子中,我将使用=>。输入help会打印出所有在这个版本的U-Boot中配置的命令;输入help
BeagleBone Black的默认命令解释器是非常简单的。按左键或右键不能进行命令行编辑;按Tab键没有命令完成;按up键没有命令历史。按这些键中的任何一个都会打乱你目前正在尝试输入的命令,你将不得不输入Ctrl + C,然后重新开始。你唯一可以安全使用的行编辑键是退格键。作为一个选项,你可以配置一个不同的命令外壳,叫做Hush,它有更复杂的交互式支持,包括命令行编辑。
默认的数字格式是十六进制。考虑以下命令作为例子:
=> nand read 82000000 400000 200000
这将从NAND闪存开始的偏移量0x400000读取0x200000字节到RAM地址0x82000000。
U-Boot广泛地使用环境变量来存储和传递函数之间的信息,甚至用来创建脚本。环境变量是简单的name=value对,被存储在内存的一个区域。变量的初始数量可以在电路板配置头文件中编码,像这样:
#define CONFIG_EXTRA_ENV_SETTINGS
"myvar1=value1"
"myvar2=value2"
[…]
你可以使用setenv从U-Boot命令行创建和修改变量。例如,setenv foo bar用bar值创建foo变量。注意,在变量名称和数值之间没有=符号。你可以通过将一个变量设置为空字符串来删除它,setenv foo。你可以用printenv把所有的变量打印到控制台,或者用printenv foo把单个变量打印出来。
如果U-Boot已经配置了存储环境的空间,你可以使用saveenv命令来保存它。如果有原始的NAND或NOR闪存,那么可以为这个目的保留擦除块,通常另被用作冗余拷贝以防止损坏。如果有eMMC或SD卡存储,它可以被存储在保留的扇区阵列中,或存储在磁盘分区中名为uboot.env的文件中。其他选择包括将其存储在通过I2C或SPI接口连接的串行EEPROM或非易失性RAM中。
U-Boot没有文件系统。相反,它用64字节的头来标记信息块,这样它就可以跟踪内容。我们使用mkimage命令行工具为U-Boot准备文件,它与Ubuntu的u-boot-tools软件包捆绑在一起。你也可以通过在U-Boot源代码树中运行make tools来获得mkimage,然后以tools/mkimage的形式调用它。
下面是对该命令用法的简要总结:
$ mkimage
Error: Missing output filename
Usage: mkimage -l image
-l ==> list image header information
mkimage [-x] -A arch -O os -T type -C comp -a addr -e ep -n name -d data_file[:data_file...] image
-A ==> set architecture to 'arch'
-O ==> set operating system to 'os'
-T ==> set image type to 'type'
-C ==> set compression type 'comp'
-a ==> set load address to 'addr' (hex)
-e ==> set entry point to 'ep' (hex)
-n ==> set image name to 'name'
-d ==> use image data from 'datafile'
-x ==> set XIP (execute in place)
mkimage [-D dtc_options] [-f fit-image.its|-f auto|-F] [-b <dtb> [-b <dtb>]] [-i <ramdisk.cpio.gz>] fit-image
<dtb> file is used with -f auto, it may occur multiple times.
-D => set all options for device tree compiler
-f => input filename for FIT source
-i => input filename for ramdisk file
Signing / verified boot options: [-E] [-B size] [-k keydir] [-K dtb] [ -c <comment>] [-p addr] [-r] [-N engine]
-E => place data outside of the FIT structure
-B => align size in hex for FIT structure and header
-k => set directory containing private keys
-K => write public keys to this .dtb file
-c => add comment in signature node
-F => re-sign existing FIT image
-p => place external data at a static position
-r => mark keys used as 'required' in dtb
-N => openssl engine to use for signing
mkimage -V ==> print version information and exit
Use '-T list' to see a list of available image types
例如,要为Arm处理器准备一个内核镜像,你可以使用
下面的命令:
$ mkimage -A arm -O linux -T kernel -C gzip -a 0x80008000 \
-e 0x80008000
-n 'Linux' -d zImage uImage
在这个例子中,架构是arm,操作系统是linux,图像类型是kernel。此外,压缩方案是gzip,加载地址是0x80008000,入口点与加载地址相同。最后,图像
名称是Linux,图像数据文件被命名为zImage,正在生成的图像被命名为uImage。
通常情况下,你会从可移动的存储器中加载镜像,比如SD卡或网络。SD卡在U-Boot中是由MMC驱动处理的。典型的顺序是用来加载图像到内存中的,如下:
=> mmc rescan
=> fatload mmc 0:1 82000000 uimage
reading uimage
4605000 bytes read in 254 ms (17.3 MiB/s)
=> iminfo 82000000
## Checking Image at 82000000 ...
Legacy image found
Image Name: Linux-3.18.0
Created: 2014-12-23 21:08:07 UTC
Image Type: ARM Linux Kernel Image (uncompressed)
Data Size: 4604936 Bytes = 4.4 MiB
Load Address: 80008000
Entry Point: 80008000
Verifying Checksum ... OK
mmc rescan命令重新初始化了MMC驱动,也许是为了检测最近是否有SD卡被插入。接下来,fatload被用来从SD卡上FAT格式的分区中读取文件。其格式如下:
fatload <interface> [<dev[:part]> [<addr> [<filename> [bytes [pos]]]]]
如果
要通过网络加载映像文件,你必须使用琐碎的文件传输协议(TFTP)。这需要你在你的开发系统上安装一个TFTP守护程序,tftpd,并开始运行它。你还必须配置你的PC和目标板之间的任何防火墙,以允许UDP 69端口的TFTP协议通过。TFTP的默认配置只允许访问/var/lib/tftpboot目录。下一步是将你想传输到目标板的文件复制到该目录。然后,假设你使用的是一对静态IP地址,这样就不需要进一步的网络管理,加载一组内核镜像文件的命令序列应该是这样的:
=> setenv ipaddr 192.168.159.42
=> setenv serverip 192.168.159.99
=> tftp 82000000 uImage
link up on port 0, speed 100, full duplex
Using cpsw device
TFTP from server 192.168.159.99; our IP address is 192.168.159.42
Filename 'uImage'.
Load address: 0x82000000
Loading:
########################################################################################################################################################################################################################################################################################################################
3 MiB/s
done
Bytes transferred = 4605000 (464448 hex)
最后,让我们看看如何将图像编程到NAND闪存中并读回,这由nand命令来处理。这个例子通过TFTP加载一个内核镜像,并将其编程到闪存中:
=> tftpboot 82000000 uimage
=> nandecc hw
=> nand erase 280000 400000
NAND erase: device 0 offset 0x280000, size 0x400000
Erasing at 0x660000 -- 100% complete.
OK
=> nand write 82000000 280000 400000
NAND write: device 0 offset 0x280000, size 0x400000
4194304 bytes written: OK
现在,你可以使用nand read命令从闪存中加载内核:
=> nand read 82000000 280000 400000
一旦内核被加载到RAM中,我们就可以启动它。
引导Linux
bootm命令启动一个正在运行的内核镜像。其语法如下:
bootm [address of kernel] [address of ramdisk] [address of dtb].
内核映像的地址是必须的,但是如果内核配置不需要它们,ramdisk和dtb的地址可以省略。如果有dtb但没有initramfs,第二个地址可以用破折号(-)代替。这看起来就像这样:
=> bootm 82000000 – 83000000
很明显,每次开机时输入一长串命令来启动你的板子是不能接受的。让我们来看看如何使启动过程自动化。
U-Boot将一连串的命令储存在环境变量中。如果名为bootcmd的特殊变量包含一个脚本,它就会在开机时经过bootdelay秒的延迟而运行。如果你在串行控制台观察,你会看到延迟倒计时为零。你可以在这期间按任何一个键来终止倒计时,并进入与U-Boot的交互式会话。
创建脚本的方法很简单,虽然不容易读懂。你只需将命令用分号隔开,分号前面必须有一个/转义字符。因此,举例来说,要从闪存的偏移量中加载一个内核镜像并启动它,你可以使用下面的命令:
setenv bootcmd nand read 82000000 400000 200000\;bootm 82000000
我们现在知道如何使用U-Boot在BeagleBone Black上启动内核了。但是我们如何将U-Boot移植到一个没有BSP的新板子上呢?我们将在本章的其余部分介绍这个问题。
移植U-Boot到新板
让我们假设你的硬件部门已经创建了一个新的板子,叫做Nova,是基于BeagleBone Black的,你需要把U-Boot移植到它上面。你将需要了解U-Boot代码的布局以及板子的配置机制是如何工作的。在本节中,我将向你展示如何创建现有板子的变体--BeagleBone Black--你可以把它作为进一步定制的基础。有相当多的文件需要被修改。我把它们放在代码档案中的MELP/Chapter03/0001-BSP-for-Nova.patch中。你可以简单地把这个补丁应用到2021.01版的U-Boot的一个干净的拷贝上,像这样:
$ cd u-boot
$ patch -p1 < MELP/Chapter03/0001-BSP-for-Nova.patch
如果你想使用不同版本的U-Boot,你必须对补丁做一些修改,才能干净地应用。
本节的其余部分将描述如何创建该补丁。如果你想按部就班,你将需要一个没有Nova BSP补丁的U-Boot 2021.01的干净拷贝。我们要处理的主要目录如下:
- arch
包含arm、mips和powerpc目录中每个支持的架构的特定代码。在每个架构中,每个家族成员都有一个子目录;例如,在arch/arm/cpu/中,有架构变体的目录,包括amt926ejs、armv7和armv8。
- 板卡
包含特定于某个板卡的代码。如果有几个来自同一供应商的板子,它们可以被收集到一个子目录里。因此,对BeagleBone所基于的am335x EVM板的支持就在board/ti/am335x中。
- common
包含核心功能,包括命令外壳和可以从中调用的命令,每个都在一个名为cmd_[命令名称].c的文件中。
- doc
包含了几个README文件,描述了U-Boot的各个方面。如果你想知道如何进行你的U-Boot移植,这是一个好的开始。
- include
除了许多共享的头文件之外,这里还包含了非常重要的include/configs/子目录,在这里你可以找到大部分的板子配置设置。
Kconfig从Kconfig文件中提取配置信息并将全部系统配置存储在一个名为.config的文件中的方式将在第四章 "配置和构建内核 "中详细描述。每块板都有一个默认的配置,存储在configs/[板名]_defconfig中。对于Nova板,我们可以先为EVM制作一个配置的副本:
$ cp configs/am335x_evm_defconfig configs/nova_defconfig
现在,编辑configs/nova_defconfig并在CONFIG_AM33XX=y之后插入CONFIG_TARGET_NOVA=y,如图所示:
CONFIG_ARM=y
CONFIG_ARCH_CPU_INIT=y
CONFIG_ARCH_OMAP2PLUS=y
CONFIG_TI_COMMON_CMD_OPTIONS=y
CONFIG_AM33XX=y
CONFIG_TARGET_NOVA=y
CONFIG_SPL=y
[…]
注意 CONFIG_ARM=y 会导致 arch/arm/Kconfig 的内容被包含在内,而 CONFIG_AM33XX=y 会导致 arch/arm/mach-omap2/am33xx/Kconfig 被包含在内。
接下来,将CONFIG_SYS_CUSTOM_LDSCRIPT=y和CONFIG_SYS_LDSCRIPT=="board/ti/nova/u-boot.lds "插入到CONFIG_DISTRO_DEFAULTS=y之后的同一个文件,如图所示:
[...]
CONFIG_SPL=y
CONFIG_DEFAULT_DEVICE_TREE="am335x-evm"
CONFIG_DISTRO_DEFAULTS=y
CONFIG_SYS_CUSTOM_LDSCRIPT=y
CONFIG_SYS_LDSCRIPT="board/ti/nova/u-boot.lds"
CONFIG_SPL_LOAD_FIT=y
[...]
现在我们已经完成了对configs/nova_defconfig的修改。
每个板子都有一个名为board/[板名]或board/[供应商]/[板名]的子目录,它应该包含以下内容:
- Kconfig: 包含电路板的配置选项。
- MAINTAINERS: 包含板子目前是否被维护的记录,如果是的话,由谁维护。
- Makefile: 用来构建板子的特定代码。
- README: 包含任何关于U-Boot这个端口的有用信息;例如,包括哪些硬件变体。
此外,还可能有针对板卡功能的源文件。
我们的Nova板是基于BeagleBone的,而BeagleBone又是基于TI am335x EVM的。因此,我们应该复制am335x板的文件:
$ mkdir board/ti/nova
$ cp -a board/ti/am335x/* board/ti/nova
接下来,编辑board/ti/nova/Kconfig,将SYS_BOARD设置为 "nova",这样它就会在board/ti/nova中建立文件。然后,将SYS_CONFIG_NAME也设为 "nova",这样它就会使用include/configs/nova.h作为配置文件:
if TARGET_NOVA
config SYS_BOARD
default "nova"
config SYS_VENDOR
default "ti"
config SYS_SOC
default "am33xx"
config SYS_CONFIG_NAME
default "nova"
[…]
这里还有一个文件,我们需要修改。链接器脚本被放置在board/ti/nova/u-boot.lds,包含一个硬编码的引用,指board/ti/am335x/built-in.o:
{
*(.__image_copy_start)
*(.vectors)
CPUDIR/start.o (.text*)
board/ti/nova/built-in.o (.text*)
}
现在,我们需要将Nova的Kconfig文件链接到Kconfig文件链中。首先,编辑arch/arm/Kconfig,在source "board/tcl/sl50/Kconfig "之后插入source "board/ti/nova/Kconfig",如下图所示:
{
*(.__image_copy_start)
*(.vectors)
CPUDIR/start.o (.text*)
board/ti/nova/built-in.o (.text*)
}
然后,编辑arch/arm/mach-omap2/am33xx/Kconfig,在TARGET_AM335X_EVM后面紧接着添加一个TARGET_NOVA的配置选项,如图所示:
[…]
source "board/st/stv0991/Kconfig"
source "board/tcl/sl50/Kconfig"
source "board/ti/nova/Kconfig"
source "board/toradex/colibri_pxa270/Kconfig"
source "board/variscite/dart_6ul/Kconfig"
[…]
然后,编辑 arch/arm/mach-omap2/am33xx/Kconfig,在 TARGET_AM335X_EVM 之后添加 TARGET_NOVA 的配置选项,如图所示:
[…]
config TARGET_NOVA
bool "Support the Nova! board"
select DM
select DM_GPIO
select DM_SERIAL
select TI_I2C_BOARD_DETECT
imply CMD_DM
imply SPL_DM
imply SPL_DM_SEQ_ALIAS
imply SPL_ENV_SUPPORT
imply SPL_FS_EXT4
imply SPL_FS_FAT
imply SPL_GPIO_SUPPORT
imply SPL_I2C_SUPPORT
imply SPL_LIBCOMMON_SUPPORT
imply SPL_LIBDISK_SUPPORT
imply SPL_LIBGENERIC_SUPPORT
imply SPL_MMC_SUPPORT
imply SPL_NAND_SUPPORT
imply SPL_OF_LIBFDT
imply SPL_POWER_SUPPORT
imply SPL_SEPARATE_BSS
imply SPL_SERIAL_SUPPORT
imply SPL_SYS_MALLOC_SIMPLE
imply SPL_WATCHDOG_SUPPORT
imply SPL_YMODEM_SUPPORT
help
The Nova target board
[…]
所有 imply SPL_ 行都是必要的,这样 U-Boot 才能顺利编译,不会出错。
现在,我们已经复制并修改了 Nova 板的特定文件,接下来就看头文件了。
每块板都有一个头文件,位于 include/configs/ 中,其中包含大部分配置信息。该文件以电路板 Kconfig 文件中的 SYS_CONFIG_NAME 标识命名。该文件的格式在 U-Boot 源代码树顶层的 README 文件中有详细描述。对于我们的 Nova 板,只需将 include/configs/am335x_evm.h 复制到 include/configs/nova.h,然后做一些修改,如图所示:
[…]
#ifndef __CONFIG_NOVA_H
#define __CONFIG_NOVA_H
include <configs/ti_am335x_common.h>
#include <linux/sizes.h>
#undef CONFIG_SYS_PROMPT
#define CONFIG_SYS_PROMPT "nova!> "
#ifndef CONFIG_SPL_BUILD
# define CONFIG_TIMESTAMP
#endif
[…]
#endif /* ! __CONFIG_NOVA_H */
除了将 __CONFIG_AM335X_EVM_H 替换为 __CONFIG_NOVA_H,唯一需要做的改动是设置一个新的命令提示符,以便在运行时识别这个引导加载器。
这样我们就可以在运行时识别这个引导加载器。
完全修改了源代码树之后,我们现在就可以为定制板构建 U-Boot 了。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
构建和测试
要为 Nova 板构建 U-Boot,请选择刚刚创建的配置:
$ source ../MELP/Chapter02/set-path-arm-cortex_a8-linux-gnueabihf
$ make distclean
$ make nova_defconfig
$ make
将 MLO 和 u-boot.img 复制到之前创建的 microSD 卡启动分区,然后启动主板。你应该会看到这样的输出(注意命令提示符):
U-Boot SPL 2021.01-dirty (Feb 08 2021 - 21:30:41 -0800)
Trying to boot from MMC1
U-Boot 2021.01-dirty (Feb 08 2021 - 21:30:41 -0800)
CPU : AM335X-GP rev 2.1
Model: TI AM335x BeagleBone Black
DRAM: 512 MiB
WDT: Started with servicing (60s timeout)
NAND: 0 MiB
MMC: OMAP SD/MMC: 0, OMAP SD/MMC: 1
Loading Environment from FAT... *** Warning - bad CRC, using default environment
<ethaddr> not set. Validating first E-fuse MAC
Net: eth2: ethernet@4a100000, eth3: usb_ether
Hit any key to stop autoboot: 0
nova!>
您可以使用 git format-patch 命令为所有这些更改创建补丁:
$ git add .
$ git commit -m "BSP for Nova"
[detached HEAD 093ec472f6] BSP for Nova
12 files changed, 2379 insertions(+)
create mode 100644 board/ti/nova/Kconfig
create mode 100644 board/ti/nova/MAINTAINERS
create mode 100644 board/ti/nova/Makefile
create mode 100644 board/ti/nova/README
create mode 100644 board/ti/nova/board.c
create mode 100644 board/ti/nova/board.h
create mode 100644 board/ti/nova/mux.c
create mode 100644 board/ti/nova/u-boot.lds
create mode 100644 configs/nova_defconfig
create mode 100644 include/configs/nova.h
$ git format-patch -1
0001-BSP-for-Nova.patch
生成此补丁后,U-Boot 作为 TPL 的覆盖范围就结束了。U-Boot 也可以配置为完全绕过启动过程中的 TPL 阶段。接下来,让我们来看看启动 Linux 的另一种方法。
Falcon模式
我们习惯于认为,启动现代嵌入式处理器需要 CPU 引导 ROM 加载 SPL,SPL 加载 u-boot.bin,u-boot.bin 再加载 Linux 内核。你可能想知道是否有办法减少这些步骤,从而简化并加快启动过程。答案就是 U-Boot Falcon 模式。这个想法很简单:让 SPL 直接加载内核映像,省去 u-boot.bin。没有用户交互,也没有脚本。它只是将内核从闪存或 eMMC 中的已知位置加载到内存中,然后将预先准备好的参数块传递给它,并启动它运行。配置猎鹰模式的细节超出了本书的范围。如果你想了解更多信息,请查看 doc/README.falcon。
重要提示
猎鹰模式是以游隼命名的,游隼是所有鸟类中速度最快的一种,在俯冲中能达到每小时 200 英里以上的速度。
小结
每个系统都需要一个引导加载器来启动硬件和加载内核。U-Boot 支持各种有用的硬件,而且很容易移植到新设备上,因此受到许多开发者的青睐。在本章中,我们学习了如何通过串行控制台的命令行交互式检查和驱动 U-Boot。这些命令行练习包括使用 TFTP 通过网络加载内核,以实现快速迭代。最后,我们学习了如何通过为 Nova 板生成补丁,将 U-Boot 移植到新设备上。
在过去几年中,由于嵌入式硬件的复杂性和多样性不断增加,引入了设备树作为描述硬件的方法。设备树只是系统的文字表述,它被编译成设备树二进制文件(DTB),并在加载时传递给内核。内核负责解释设备树,并为其找到的设备加载和初始化驱动程序。
在使用中,U-Boot 非常灵活,可以从大容量存储器、闪存或网络加载映像,然后启动。在介绍了启动 Linux 的一些复杂之处后,我们将在下一章介绍该过程的下一阶段,即嵌入式项目的第三个元素--内核--的作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号