selenium 4(python)快速入门
Selenium历史
Selenium为浏览器自动化提供了先进的功能,从业者通常用它来实现网络应用的端到端测试。Selenium由三个核心组件组成: WebDriver, Grid, 和 IDE。
Jason Huggins和Paul Hammant于2004年在Thoughtworks工作时创建了Selenium。他们选择了 "Selenium "这个名字作为与惠普公司开发的现有测试框架Mercury的对应物。这个名字很有意义,因为化学物质硒以减少汞的毒性而闻名。
最初版本的Selenium(今天被称为Selenium Core)是一个JavaScript库,在网络应用中模拟用户操作。Selenium Core解释Selenese命令来实现任务。这些命令被编码为由三部分组成的HTML表格:命令(在网络浏览器中执行的动作,如打开URL或点击链接)、目标(识别网络元素的定位器,如特定组件的属性)和值(可选数据,如输入到网络表格字段中的文本)。
Huggins和Hammant在Selenium Remote Control(RC)的新项目中给Selenium Core增加了脚本层。Selenium RC遵循C-S架构。客户端使用一种绑定语言(如Python或JavaScript)通过HTTP向Selenium RC服务器的中间代理发送Selenese命令。该服务器按需启动网络浏览器,将Selenium Core库注入网站,并将客户的请求代理给Selenium Core。此外,Selenium RC服务器将目标网站掩盖在与注入的Selenium Core库相同的本地URL上,以避免同源策略问题。这种方法在当时是改变了浏览器自动化的游戏规则,但它有很大的局限性。首先,由于JavaScript是支持自动化的底层技术,有些操作是不允许的,因为JavaScript不允许--例如,上传和下载文件或处理弹出式窗口和对话框。此外Selenium RC引入的开销也影响性能。
与此同时,Simon Stewart在2007年创建了WebDriver项目。WebDriver和Selenium RC从功能的角度来看是相当的,也就是说,这两个项目都允许程序员使用编程语言来模拟用户。然而,WebDriver使用每个浏览器的原生支持来进行自动化,因此,其能力和性能远远优于RC。2009年,Jason Huggins和Simon Stewart在谷歌测试自动化会议上会面后,他们决定将Selenium和WebDriver合并为一个项目。这个新项目被称为Selenium WebDriver或Selenium 2。这个新项目使用基于HTTP的通信协议,结合浏览器上的本地自动化支持。这种方法仍然是Selenium 3(2016年发布)和Selenium 4(2021年发布)的基础。现在我们把Selenium RC和Core称为 "Selenium 1",而且不鼓励使用它,而是使用Selenium WebDriver。
Selenium WebDriver
Selenium WebDriver是自动控制浏览器的库。它提供了不同语言绑定的跨平台的API。Selenium WebDriver支持的官方编程语言有Python、Java、JavaScript、Ruby和C#。Selenium WebDriver使用每个浏览器实现的本地支持来执行自动化过程。我们需要在使用Selenium WebDriver API的脚本和浏览器之安装驱动。

驱动程序(如chromedriver、geckodriver等)是依赖于平台的二进制文件,接收来自WebDriver脚本的命令,并将其翻译成一些浏览器特定的语言。在Selenium WebDriver的第一个版本中(即在Selenium 2中),这些命令(也被称为Selenium协议)是通过HTTP的JSON消息(所谓的 JSON Wire Protocol)。如今,这种通信(仍然是通过HTTP的JSON)遵循W3C WebDriver的标准规范。从Selenium 4开始,该规范是首选的Selenium协议。
Chrome浏览器遵循DevTools协议。DevTools是一套用于基于Blink渲染引擎的浏览器的开发者工具,如Chrome、Chromium、Edge或Opera。DevTools协议基于JSON-RPC消息,可以对这些浏览器进行检查、调试和分析。在Firefox中,原生自动化支持使用Marionette协议。Marionette是基于JSON的远程协议,允许检测和控制基于Gecko引擎的网络浏览器(如Firefox)。
Selenium WebDriver允许像用户一样控制网络浏览器,但要以编程方式进行。为此,Selenium WebDriver的API提供了各种各样的功能,可以浏览网页,与网页元素互动,或者模拟用户操作,以及其他许多功能。目标应用是基于网络的,如静态网站、动态网络应用、单页应用(SPA)、具有网络界面的复杂企业系统等。
Selenium Grid
Selenium家族的第二个项目是Selenium Grid。Philippe Hanrigou在2008年开始开发这个项目。Selenium Grid是一组联网的主机,为Selenium WebDriver提供浏览器基础设施。这个基础结构使Selenium WebDriver脚本能够在多个操作系统的不同性质(类型和版本)的远程浏览器中(并行)执行。
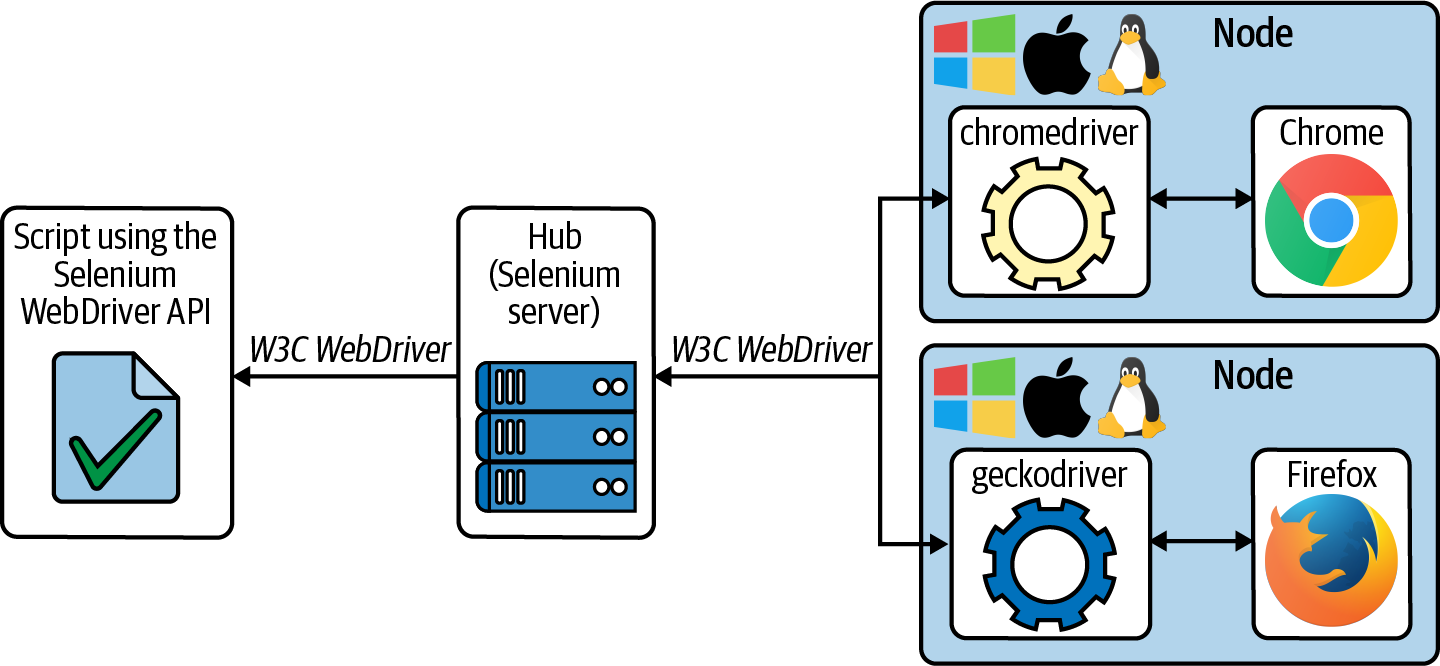
网格的中心入口是Hub(也被称为Selenium服务器)。这个服务器端的组件保持对节点的跟踪,并代理来自Selenium脚本的请求。和Selenium WebDriver一样,W3C WebDriver规范是这些脚本和Hub之间通信的标准协议。Selenium 4提供了完全分布式的Selenium Grid。这种架构实现了先进的负载平衡机制,以避免任何组件过载。
Selenium IDE
Shinya Kasatani在2006年创建了这个项目。Selenium IDE是记录和回放(R&P)自动化技术的工具。首先,在Selenium IDE中,记录部分捕获用户与浏览器的互动,将这些动作编码为Selenium命令。第二,我们使用生成的Selenium脚本来自动执行浏览器会话(回放)。
这个早期版本的Selenium IDE是一个Firefox插件,嵌入了Selenium Core来记录、编辑和播放Selenium脚本。这些早期版本是XPI模块(即用于创建Mozilla扩展的技术)。从55版(2017年发布)开始,火狐浏览器将对附加组件的支持迁移到了W3C浏览器扩展规范。因此,Selenium IDE被停用了,有一段时间无法使用它。Selenium团队按照浏览器扩展的建议重写了Selenium IDE,以解决这个问题。得益于此,我们现在可以在多个浏览器中使用Selenium IDE,如Chrome、Edge和Firefox。
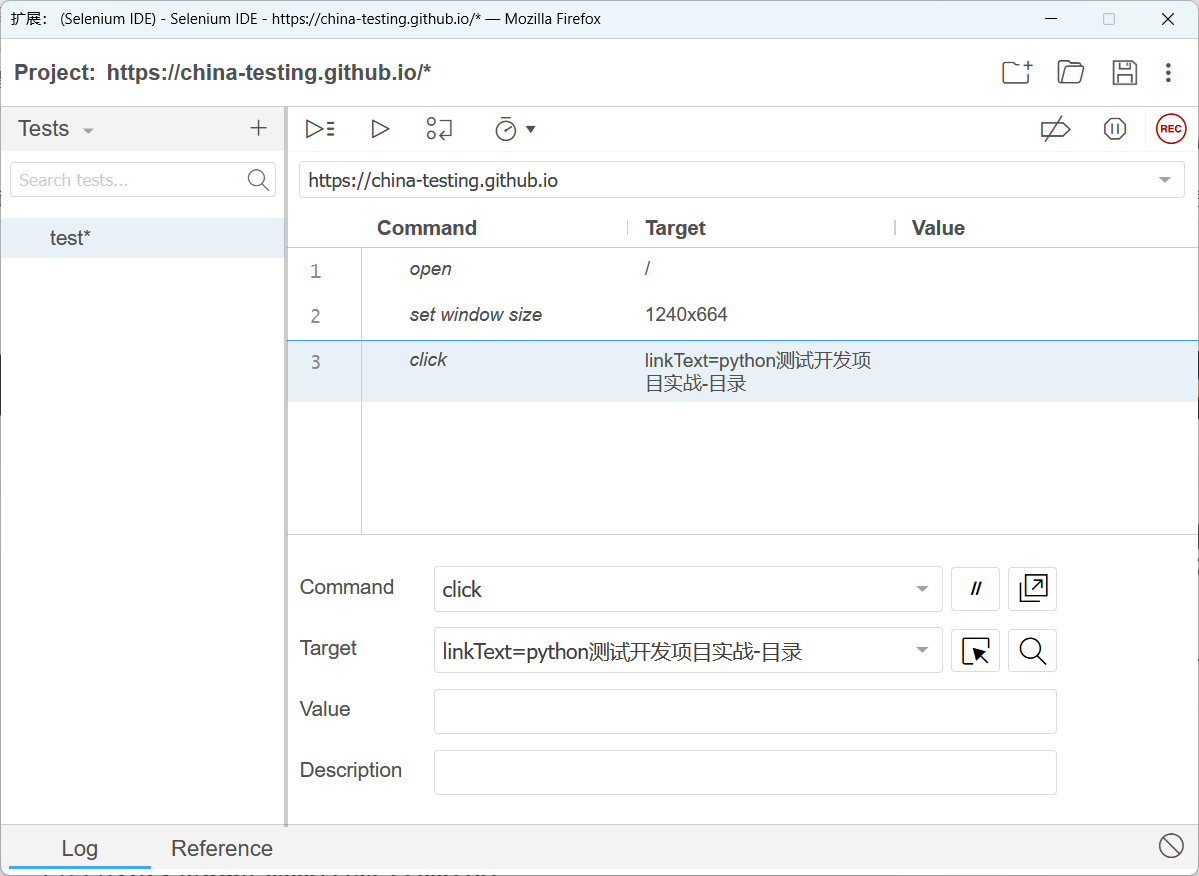
使用这个GUI,用户可以记录与浏览器的交互,编辑和执行生成的脚本。Selenium IDE将每个交互编码为不同的部分:命令(即在浏览器中执行的动作)、目标(即网络元素的定位器)和值(即处理的数据)。当然,我们也可以包括对命令的描述。Selenium IDE基于Electron。Electron是基于Chromium和Node.js的开源框架,允许桌面应用开发。
Selenium 生态系统
- API
Selenium项目为Selenium WebDriver维护着各种语言绑定:
Python、Java、JavaScript、Ruby和C#。
-
驱动
-
定位器工具
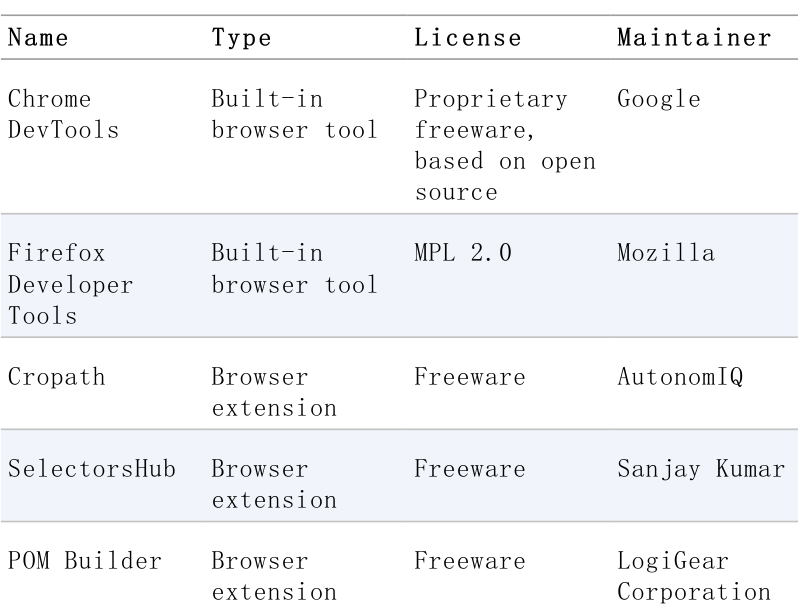
Selenium WebDriver API提供了不同的方法来定位Web元素(见第三章):通过属性(id、name或class),通过链接文本(完整或部分),通过标签名称,通过CSS(层叠样式表)选择器,或通过XML路径语言(XPath)。特定的工具可以帮助识别和生成这些定位器。
- 框架
python中有不少库对selenium进行了扩展,以下是一部分
https://github.com/mherrmann/selenium-python-helium
https://github.com/seleniumbase/SeleniumBase
https://github.com/cobrateam/splinter
- 浏览器基础设施
我们可以用Selenium WebDriver来控制安装在运行WebDriver脚本的机器上的本地浏览器。同时,Selenium WebDriver可以驱动远程网络浏览器(即在其他主机上执行的浏览器)。在这种情况下,我们可以使用Selenium Grid来支持远程浏览器的基础设施。尽管如此,这种基础设施在创建和维护方面可能具有挑战性。
另外,我们也可以使用云提供商,将支持浏览器基础设施的责任外包出去。在Selenium生态系统中,云提供商是为自动测试提供管理服务的公司或产品。这些公司通常提供网络和移动测试的商业解决方案。云提供商的用户要求按需提供不同类型、版本和操作系统的浏览器。此外,这些供应商通常提供额外的服务,以缓解测试和监测活动,如访问会话记录或分析能力,仅举几例。现在与Selenium最相关的一些云供应商是Sauce Labs、BrowserStack、LambdaTest、CrossBrowserTesting、Moon Cloud、TestingBot、Perfecto或Testinium。
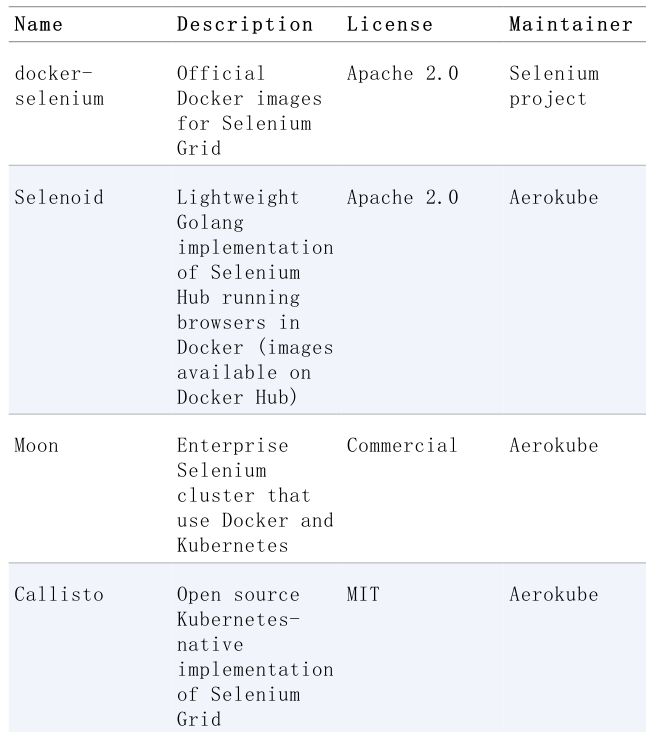
另一个我们可以用来支持Selenium的浏览器基础设施的解决方案是Docker。Docker是一种开源软件技术,允许用户将应用程序打包并作为轻量级、可移植的容器运行。Docker平台有两个主要组成部分:Docker引擎:用于创建和运行容器的工具,以及Docker Hub:用于分发Docker镜像的云服务。在Selenium领域,我们可以使用Docker来打包和执行容器化浏览器。表1-6列出了在Selenium生态系统中使用Docker的相关项目的摘要。
- 社区
由于其协作的性质,软件开发需要许多参与者的组织和互动。在开放源码领域,我们可以通过社区的相关性来衡量一个项目的成功。Selenium得到了全世界许多不同参与者的大型社区的支持。

Demo
from selenium import webdriver
from selenium.webdriver.common.by import By
# create webdriver object
driver = webdriver.Firefox()
driver.get("https://cn.bing.com")
driver.find_element(By.ID, "sb_form_q").send_keys("python selenium")
driver.find_element(By.CSS_SELECTOR, "#search_icon > svg").click()
快速入门
实例
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("http://www.python.org")
assert "Python" in driver.title
elem = driver.find_element_by_name("q")
elem.clear()
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
assert "No results found." not in driver.page_source
driver.close()
selenium.webdriver模块提供所有的WebDriver实现。目前支持的WebDriver实现有Firefox、Chrome、IE和Remote。Keys类提供键盘上的按键,如RETURN、F1、ALT等。By类用于定位文档中的元素。
driver.get方法将导航到URL。WebDriver将等待页面完全加载(即 "onload"事件已触发),然后再将控制权返回给你。请注意,如果您的页面在加载时使用了大量的AJAX,那么WebDriver可能不知道它何时已经完全加载。如果你需要确保此类页面完全加载,那么你可以使用waits。
WebDriver提供了许多使用find_element方法来寻找元素的方法。例如,可以使用find_element方法并使用By.NAME作为其第一个参数,通过其name属性来定位输入文本元素。
接下来,我们要发送按键,这类似于使用键盘输入按键。可以使用从selenium.webdriver.common.keys导入的Keys类来发送特殊按键。为了安全起见,我们首先要清除输入字段中任何预先填充的文本(如 "搜索"),这样就不会影响我们的搜索结果。
quit方法将退出整个浏览器,而close将关闭一个标签,但如果它是唯一打开的标签,默认情况下大多数浏览器将完全退出。
基于单元测试框架实例
Selenium主要用于编写测试案例。Selenium包本身并不提供测试工具/框架。你可以使用Python的unittest模块编写测试用例。工具/框架的其他选择是 pytest 和 nose。
下面是使用 unittest 模块的修改后的例子。这是对 python.org 搜索功能的测试:
import unittest
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
class PythonOrgSearch(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
def test_search_in_python_org(self):
driver = self.driver
driver.get("http://www.python.org")
self.assertIn("Python", driver.title)
elem = driver.find_element_by_name("q")
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
assert "No results found." not in driver.page_source
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()
导航
页面互动
WebDriver提供了许多寻找元素的方法。例如,已知元素定义如下::
<input type="text" name="passwd" id="passwd-id" />
你可以用以下方法找到它:
element = driver.find_element(By.ID, "passwd-id")
element = driver.find_element(By.NAME, "passwd")
element = driver.find_element(By.XPATH, "//input[@id='passwd-id']")
element = driver.find_element(By.CSS_SELECTOR, "input#passwd-id")
你也可以通过文本来寻找链接,但要小心!文本必须是完全匹配的!在WebDriver中使用XPATH时,如果有一个以上的元素符合查询,那么只有第一个会被返回。如果什么都找不到,将引发NoSuchElementException。
WebDriver有一个 "基于对象 "的API;我们使用相同的接口表示所有类型的元素。这意味着,尽管你在敲击IDE的自动完成组合键时可能会看到很多可能的方法,但并不是所有的方法都有意义或有效。不要担心!WebDriver会尝试去做!如果你调用一个没有意义的方法(例如在 "meta "标签上调用 "setSelected()"),就会出现异常。
element.send_keys("some text")
element.send_keys(" and some", Keys.ARROW_DOWN)
element.clear()
可以在任何元素上调用send_keys,这使得测试键盘快捷键成为可能,例如GMail上使用的快捷键。这样做的一个副作用是,在文本字段中输入东西不会自动清除它。相反,你输入的内容会被附加到已经存在的内容上。你可以用clear方法轻松地清除文本字段或文本区域的内容:
表单
我们已经看到了如何在文本框或文本字段中输入文本,但其他元素呢?你可以 "切换 "下拉菜单的状态,你也可以使用 "setSelected "来设置类似OPTION标签的东西被选中。处理SELECT标签也不是太糟糕:
你可以“切换”下拉框的状态,你可以使用setSelected方法去做一些事情,比如 选择下拉列表:
element = driver.find_element(By.XPATH, "//select[@name='name']")
all_options = element.find_elements(By.TAG_NAME, "option")
for option in all_options:
print("Value is: %s" % option.get_attribute("value"))
option.click()
这将找到页面上的第一个 "SELECT "元素,并依次循环浏览它的每个OPTION,打印出它们的值,并依次选择每一个。
正如你所看到的,这并不是处理SELECT元素的最有效的方法。WebDriver的 "Select "类提供了与这些元素交互的有用方法:
from selenium.webdriver.support.ui import Select
select = Select(driver.find_element(By.NAME, 'name'))
select.select_by_index(index)
select.select_by_visible_text("text")
select.select_by_value(value)
select = Select(driver.find_element(By.ID, 'id'))
select.deselect_all()
select = Select(driver.find_element(By.XPATH, "//select[@name='name'] ")
all_selected_options = select.all_selected_options
options = select.options
driver.find_element_by_id("submit").click()
element.submit()
另外,WebDriver对每个元素都有方便的方法 "submit"。如果你在表单中调用这个方法,WebDriver会在DOM上行走,直到找到最近的外层的表单,然后对其调用submit。如果该元素不在表单中,那么就会引发NoSuchElementException。
拖放
element = driver.find_element(By.NAME, "source")
target = driver.find_element(By.NAME, "target")
from selenium.webdriver import ActionChains
action_chains = ActionChains(driver)
action_chains.drag_and_drop(element, target).perform()
在不同的窗口和框架之间移动
driver.switch_to.window("windowName")
所有的 driver 将会指向当前窗口,但是你怎么知道窗口的名字呢,查看打开他的javascript或者连接:
<a href="somewhere.html" target="windowName">Click here to open a new window</a>
或者,你可以在”switch_to_window()”中使用”window handle”来打开它, 知道了这些,你就可以迭代所有已经打开的窗口了:
for handle in driver.window_handles:
driver.switch_to.window(handle)
你还可以在不同的frame中切换 (or into iframes):
driver.switch_to.frame("frameName")
通过“.”操作符你还可以获得子frame,并通过下标指定任意frame,就像这样:
driver.switch_to.frame("frameName.0.child")
将转到名为 "frameName "的框架的第一个子框架的 "child "的框架。
一旦我们完成了frame中的工作,我们可以这样返回父frame:
driver.switch_to.default_content()
弹框
alert = driver.switch_to.alert
导航:历史和位置
driver.forward()
driver.back()
请注意,这个功能完全取决于底层驱动。只是,如果你习惯了一个浏览器的行为而不是另一个浏览器的行为,当你调用这些方法时,可能会发生一些意外。
Cookies
# Go to the correct domain
driver.get("http://www.example.com")
# Now set the cookie. This one's valid for the entire domain
cookie = {'name' : 'foo', 'value' : 'bar'}
driver.add_cookie(cookie)
# And now output all the available cookies for the current URL
driver.get_cookies()
元素查找
-
find_element
-
find_elements 查找多个元素
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//button[text()="Some text"]')
driver.find_elements(By.XPATH, '//button')
By类的属性被用来定位页面上的元素。这些是By类可用的属性:
ID = "id"
NAME = "name"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
通过ID定位
返回第一个匹配id属性的元素。如果没有元素匹配,将引发NoSuchElementException。
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="密码" />
<input name="continue" type="submit" value="Login" />
</form>
</body>
</html>
login_form = driver.find_element(By.ID, 'loginForm')
通过name定位
返回第一个匹配的name属性的元素。如果没有元素匹配,将引发NoSuchElementException。
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="密码" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" /> <input name="continue" type="button" value="Clear" />
</form>
</body>
</html>
username = driver.find_element(By.NAME, 'username')
password = driver.find_element(By.NAME, 'password')
continue = driver.find_element(By.NAME, 'continue')
通过XPath定位
XPath是用来定位XML文档中的节点的语言。由于HTML可以是XML(XHTML)的实现,Selenium用户可以利用这种强大的语言来定位他们网络应用中的元素。XPath支持通过id或name属性定位的简单方法,并通过开辟各种新的可能性来扩展它们,如定位页面上的第三个复选框。
使用XPath的主要原因之一就是当你想获取一个既没有id属性也没有name属性的元素时, 你可以通过XPath使用元素的绝对位置来获取他(这是不推荐的),或相对于有一个id或name属性的元素 (理论上的父元素)的来获取你想要的元素。XPath定位器也可以通过非id和name属性查找元素。
绝对的XPath是所有元素都从根元素的位置(HTML)开始定位,只要应用中有轻微的调整,会就导致你的定位失败。 但是通过就近的包含id或者name属性的元素出发定位你的元素,这样相对关系就很靠谱, 因为这种位置关系很少改变,所以可以使你的测试更加强大。
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="密码" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" /> <input name="continue" type="button" value="Clear" />
</form>
</body>
</html>
表单元素可以像这样定位:
# 绝对路径(如果HTML只是稍作改变就会中断)
login_form = driver.find_element_by_xpath("/html/body/form[1]")
# HTML中的第一个表单元素
login_form = driver.find_element_by_xpath("//form[1]")
# 属性id设置为loginForm的表单元素
login_form = driver.find_element_by_xpath("//form[@id='loginForm']")
# 第一个form元素中包含name属性并且其值为 username 的input元素
username = driver.find_element_by_xpath("//form[input/@name='username']")
# id为 loginForm 的form元素的第一个input子元素
username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]")
# 第一个name属性为 username 的input元素
username = driver.find_element_by_xpath("//input[@name='username']")
# input,属性名称设置为continue,属性类型设置为button
clear_button = driver.find_element(By.XPATH, "//input[@name='continue'][@type='button']")
#form元素的第四个输入子元素,属性id设置为loginForm
clear_button = driver.find_element(By.XPATH, "//form[@id='loginForm']/input[4]")
参考资料:
- W3Schools XPath Tutorial
- [W3C XPath Recommendation](https://www.w3.org/TR/xpath/)
- XPath Tutorial - with interactive examples.
插件:
xPath Finder - 获取元素xPath的插件
XPath帮助器 - 用于谷歌浏览器
链接文本
返回具有与所提供的值相匹配的链接文本的第一个元素。如果没有元素有匹配,将引发NoSuchElementException。
例如,考虑这个页面源:
<html>
<body>
<p>Are you sure you want to do this?</p>
<a href="continue.html">Continue</a>
<a href="cancel.html">Cancel</a>
</body>
</html>
continue_link = driver.find_element(By.LINK_TEXT, 'Continue')
continue_link = driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti')
Tag
<html>
<body>
<h1>Welcome</h1>
<p>Site content goes here.</p>
</body>
</html>
heading1 = driver.find_element(By.TAG_NAME, 'h1')
类名
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
</html>
content = driver.find_element(By.CLASS_NAME, 'content')
CSS选择器
当你想用CSS选择器的语法来定位一个元素时,可以使用这个方法。使用这种策略,将返回与给定的CSS选择器相匹配的第一个元素。如果没有元素与所提供的CSS选择器相匹配,将引发NoSuchElementException。
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
</html>
content = driver.find_element(By.CSS_SELECTOR, 'p.content')
参考 https://saucelabs.com/resources/blog/selenium-tips-css-selectors
等待
大多数Web应用使用AJAX技术。当页面被浏览器加载时,页面中的元素可能在不同的时间间隔内加载。这使得定位元素很困难:如果元素还没有出现在DOM中,定位函数会引发ElementNotVisibleException异常。使用waits可以解决这个问题。等待提供了一些执行动作之间的空隙--主要是定位元素或对元素的任何其他操作。
Selenium Webdriver提供两种类型的等待--隐式和显式。显式等待使WebDriver在继续执行之前等待某个条件的发生。隐式等待使WebDriver在试图定位元素时在DOM上轮询一定的时间。
显式等待
显式等待是你定义的代码,用来等待某个条件的发生,然后再继续执行代码。这方面的极端情况是time.sleep(),它将条件设定时间段来等待。有一些方便的方法可以帮助你写代码,只需等待所需的时间即可。WebDriverWait与ExpectedCondition相结合是一种实现方式。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
在上面的代码中,Selenium将等待最多10秒,如果在这段时间内没有找到元素,就会抛出一个TimeoutException。默认情况下,WebDriverWait每500毫秒调用一次ExpectedCondition,直到它返回成功。ExpectedCondition在成功的情况下会返回true(布尔值),如果未能找到一个元素,则不会返回null。
常见预期条件
title_is
title_contains
presence_of_element_located
visibility_of_element_located
visibility_of
presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
element = wait.until(EC.element_to_be_clickable((By.ID, 'someid')))
你也可以创建自定义等待条件。自定义的等待条件可以使用有__call__方法的类来创建,当条件不匹配时返回False。
class element_has_css_class(object):
"""An expectation for checking that an element has a particular css class.
locator - used to find the element
returns the WebElement once it has the particular css class
"""
def __init__(self, locator, css_class):
self.locator = locator
self.css_class = css_class
def __call__(self, driver):
element = driver.find_element(*self.locator) # Finding the referenced element
if self.css_class in element.get_attribute("class"):
return element
else:
return False
# Wait until an element with id='myNewInput' has class 'myCSSClass'
wait = WebDriverWait(driver, 10)
element = wait.until(element_has_css_class((By.ID, 'myNewInput'), "myCSSClass"))
你也可以考虑使用polling2库。
隐式等待
隐式等待告诉WebDriver在试图找到任何不能立即使用的元素(或多个元素)时,在DOM上轮询一定的时间。默认设置是0(零)。
from selenium import webdriver
driver = webdriver.Firefox()
driver.implicitly_wait(10) # seconds
driver.get("http://somedomain/url_that_delays_loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
页面对象
本章是对页面对象设计模式的教程性介绍。页面对象代表了Web应用的用户界面中进行交互的区域。
使用页面对象模式的好处:
- 易于阅读的测试案例
- 可重复使用的代码,可以在多个测试案例中共享
- 减少了重复的代码量
- 用户界面发生变化,修复时只需要在一个地方进行修改
测试用例
下面是在python.org网站搜索一个词并保证一些结果可以找到的测试用例。
import unittest
from selenium import webdriver
import page
class PythonOrgSearch(unittest.TestCase):
"""A sample test class to show how page object works"""
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.get("http://www.python.org")
def test_search_in_python_org(self):
"""Tests python.org search feature. Searches for the word "pycon" then
verified that some results show up. Note that it does not look for
any particular text in search results page. This test verifies that
the results were not empty."""
#Load the main page. In this case the home page of Python.org.
main_page = page.MainPage(self.driver)
#Checks if the word "Python" is in title
self.assertTrue(main_page.is_title_matches(), "python.org title doesn't match.")
#Sets the text of search textbox to "pycon"
main_page.search_text_element = "pycon"
main_page.click_go_button()
search_results_page = page.SearchResultsPage(self.driver)
#Verifies that the results page is not empty
self.assertTrue(search_results_page.is_results_found(), "No results found.")
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()
页面对象类
页面对象模式意在为网页的每个部分创建一个对象。这种技术有助于在测试代码和与网页交互的实际代码之间分离。
page.py将看起来像这样:
from element import BasePageElement
from locators import MainPageLocators
class SearchTextElement(BasePageElement):
"""This class gets the search text from the specified locator"""
#The locator for search box where search string is entered
locator = 'q'
class BasePage(object):
"""Base class to initialize the base page that will be called from all
pages"""
def __init__(self, driver):
self.driver = driver
class MainPage(BasePage):
"""Home page action methods come here. I.e. Python.org"""
#Declares a variable that will contain the retrieved text
search_text_element = SearchTextElement()
def is_title_matches(self):
"""Verifies that the hardcoded text "Python" appears in page title"""
return "Python" in self.driver.title
def click_go_button(self):
"""Triggers the search"""
element = self.driver.find_element(*MainPageLocators.GO_BUTTON)
element.click()
class SearchResultsPage(BasePage):
"""Search results page action methods come here"""
def is_results_found(self):
# Probably should search for this text in the specific page
# element, but as for now it works fine
return "No results found." not in self.driver.page_source
页面元素
element.py将看起来像这样:
from selenium.webdriver.support.ui import WebDriverWait
class BasePageElement(object):
"""Base page class that is initialized on every page object class."""
def __set__(self, obj, value):
"""Sets the text to the value supplied"""
driver = obj.driver
WebDriverWait(driver, 100).until(
lambda driver: driver.find_element_by_name(self.locator))
driver.find_element_by_name(self.locator).clear()
driver.find_element_by_name(self.locator).send_keys(value)
def __get__(self, obj, owner):
"""Gets the text of the specified object"""
driver = obj.driver
WebDriverWait(driver, 100).until(
lambda driver: driver.find_element_by_name(self.locator))
element = driver.find_element_by_name(self.locator)
return element.get_attribute("value")
定位器
from selenium.webdriver.common.by import By
class MainPageLocators(object):
"""A class for main page locators. All main page locators should come here"""
GO_BUTTON = (By.ID, 'submit')
class SearchResultsPageLocators(object):
"""A class for search results locators. All search results locators should
come here"""
pass

 浙公网安备 33010602011771号
浙公网安备 33010602011771号