



python3-常用模块之re
正则表达式
定义:
正则表达式是对字符串操作的一种逻辑公式,用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
是一种独立的规则,独立的语言。只和字符串打交道。
能做什么?
例子1:把一个文件中所有的手机号码都找出来;
# open打开文件
# 读文件 str
# 从一长串的字符串中找到所有的11位数字
# 一个字符一个字符的读
例子2:爬虫,从网页的字符串中获取你想要的数据
例子3:提取特定日志内容
规则
字符组:
[] 写在中括号中的内容,都出现在下面的某一个字符的位置上都是符合规则的
[0-9] 匹配数字
[a-z] 匹配小写字母
[A-Z] 匹配大写字母
[4-9] 匹配4到9数字
[a-zA-Z] 匹配大小写字母
[a-zA-Z0-9] 匹配大小写字母+数字
[a-zA-Z0-9_] 匹配数字字母下滑线
转义符+元字符
\w 匹配数字字母下滑线 word关键字 [a-zA-Z0-9_]
\d 匹配所有的数字 digit [0-9]
\s 匹配所有的空白符 回车/换行符 制表符 空格 space [\n\t ]
\W \D \S 和\w \d \s取反
\b 表示单词的边界
[\s\S] [\d\D] [\w\W] 三组全集 意思是匹配所有字符
和转义字母相关的 元字符
\w \d \s(\n\t) \b \W \D \S
元字符
^ 匹配一个字符串的开始
$ 匹配一个字符串的结束
. 表示匹配除换行符之外的所有字符
[] 只要出现在中括号内的内容都可以被匹配
[^] 只要不出现在中括号中的内容都可以被匹配
a|b 或 符合a规则的或者b规则的都可以被匹配
# 如果a规则是b规则的一部分,且a规则比b规则要苛刻/长,就把a规则写在前面
# 将更复杂的\更长的规则写在最前面
() 分组 表示给几个字符加上量词约束的需求的时候,就给这些量词分在一个组
量词
{n}表示 这个量词之前的字符出现n次
{n,} 表示这个量词之前的字符至少出现n次
{n,m} 表示这个量词之前的字符出现n-m次
? 表示匹配量词之前的字符出现 0次 或者 1次 表示可有可无
+ 表示匹配量词之前的字符出现 1次 或者 多次
* 表示匹配量词之前的字符出现 0次 或者 多次
练习:
匹配整数 \d+
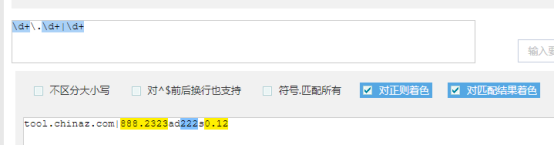
匹配小数 \d+\.\d+
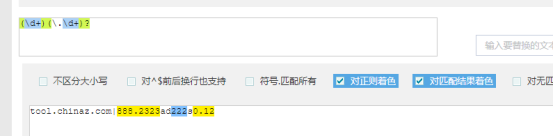
匹配小数或者整数 \d+\.\d+|\d+ \d+(\.\d+)?
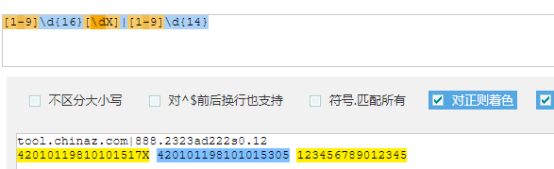
匹配身份证号(暂不考虑校验规则):
[1-9]\d{14}(\d{2}[\dX])?

[1-9]\d{16}[\dX]|[1-9]\d{14}
贪婪匹配
在允许的范围内取最长的结果
非贪婪模式/惰性匹配 : 在量词的后面加上?
.*?x 匹配任意非换行符字符任意长度 直到遇到x就停止
字符+量词 约束一个字符连续出现的次数
字符+量词+? 约束一个字符连续出现的最少次数
字符+量词+?+x 约束一个字符连续出现量词范围内的最少次数,遇到x就立即停止
以上都是正则表达式自身的规则,与python没有毛关系
Re模块
findall : 匹配所有 每一项都是列表中的一个元素

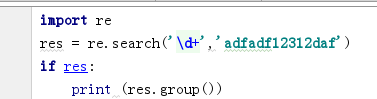
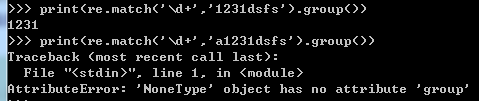
search : 只匹配从左到右的第一个,得到的不是直接的结果,而是一个变量,通过这个变量的group方法来获取结果

如果没有匹配到,会返回None,使用group会报错

程序中一般都是这样使用:
match:从头开始匹配,相当于search中的正则表达式加上一个^
字符串处理的扩展 : 替换 切割
split

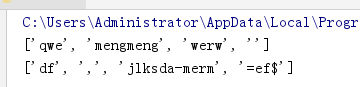
sub 旧的 新的 替换次数

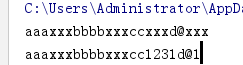
subn 返回一个元组,第二个元素是替换的次数


compile 模块 节省时间
直接把正则表达式编译成字节码,在多次使用的过程中,不会多次编译
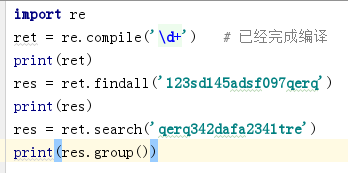
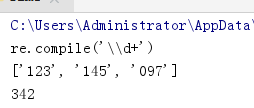
finditer 节省使用正则表达式解决问题的空间/内存
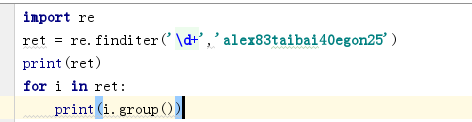
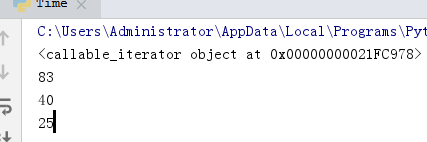
分组
group()表示总体匹配出的内容,group(num)表示匹配出第num个分组
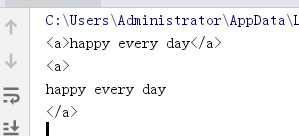
import re
s = "<a>happy every day</a>"
res = re.search('(<\w+>)([\w\W]+)(</\w+>)',s)
print(res.group()) # 所有结果
print(res.group(1)) # 数字代表第几个分组
print(res.group(2))
print(res.group(3))
输出
Findall 优先级
ret = re.findall('www.(baidu|sina).com', 'www.sina.com')
print(ret) # ['sina'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|sina).com', 'www.sina.com')
print(ret) # ['www.sina.com']
flags有很多可选值:
re.I(IGNORECASE)忽略大小写,括号内是完整的写法
re.M(MULTILINE)多行模式,改变^和$的行为
re.S(DOTALL)点可以匹配任意字符,包括换行符
re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用
re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag
re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释

