



python3-常用模块之序列化
序列化 : 把其他的数据类型转换成 字符串或者bytes
序列 : 列表、元组、字符串、bytes
为什么要把其他数据类型转换成字符串?
能够在网络上传输的只能是bytes,能够存储在文件里的只有bytes和str
网络传输过程
字典 -> 字符串 -通过网络去传输-> 字符串 -> 字典
序列化 字典 -> 字符串,可以直接使用str()
str_dic = str([1,2,3])
print(str_dic,type(str_dic))
输出:[1, 2, 3] <class 'str'>
反序列化 字符串 -> 字典 使用eval()(从文件中读出来的或者网络上接收来)
str_dic = str([1,2,3])
res = eval(str_dic)
print(res,type(res))
输出:[1, 2, 3] <class 'list'>
注意:eval()函数十分强大,但eval官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。
强大的函数有代价。安全性是其最大的缺点。
比如"删除文件"类似的破坏性语句,那么后果实在不堪设设想。
val('import os;os.remove('c:')')
所以,不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构),需要使用json、pickle做序列化
序列化的目的
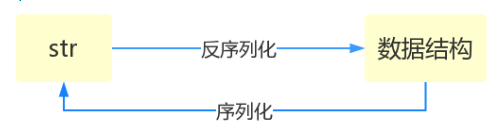
json
dumps loads
在内存中做数据转换 :
dumps 数据类型 转成 字符串 序列化
loads 字符串 转成 数据类型 反序列化
dump load
直接将数据类型写入文件,直接从文件中读出数据类型
dump 数据类型 写入 文件 序列化
load 文件 读出 数据类型 反序列化
json是所有语言都通用的一种序列化格式
只支持 列表 字典 字符串 数字
字典的key必须是字符串
序列化之后的json没有单引号,只有双引号,因为json只支持双引号
# import json
# 问题1 字典中的int类型,序列化及反序列化后变成字符串类型
# dic = {1: 'value', 2: 'value2'}
# ret = json.dumps(dic) # 序列化
# print(dic, type(dic))
# print(ret, type(ret))
# res = json.loads(ret) # 反序列化
# print(res, type(res))
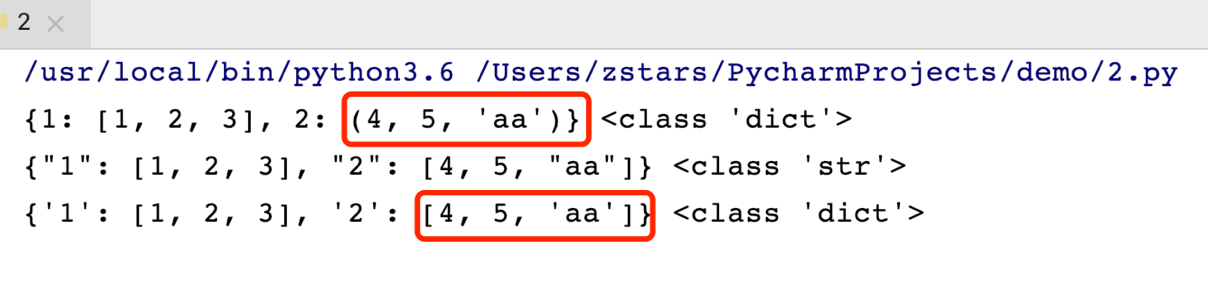
# 问题2 元组变成了列表
# dic = {1: [1, 2, 3], 2: (4, 5, 'aa')}
# ret = json.dumps(dic) # 序列化
# print(dic, type(dic))
# print(ret, type(ret))
# res = json.loads(ret) # 反序列化
# print(res, type(res))
# 问题3 集合类型不能作为键,序列化
# s = {1, 2, 'aaa'}
# json.dumps(s)
# 问题4 元组不能作为键 # TypeError: keys must be a string
# json.dumps({(1, 2, 3): 123})
# 向文件中记录字典
# dic = {'key1' : 'value1','key2' : 'value2'}
# ret = json.dumps(dic) # 序列化
# with open('json_file','w') as f:
# f.write(ret)
# # 从文件中读取字典
# with open("json_file") as f:
# content = f.read()
# ret = json.loads(content)
# print (ret,content)
# print (type(ret))
# print (type(content))
# load dump 直接操作文件
# dic = {'key1' : 'value1','key2' : 'value2'}
# with open("json_file","w") as f:
# json.dump(dic,f)
# with open("json_file") as f:
# ret = json.load(f)
# print (ret["key1"])
# 问题5 不支持连续的存 取
# dic = {'key1' : 'value1','key2' : 'value2'}
# with open('json_file','a') as f:
# json.dump(dic,f)
# json.dump(dic,f)
# json.dump(dic,f)
# with open('json_file','r') as f:
# dic = json.load(f)
# print(dic.keys())
# 需求 :强行要把一个一个的字典放到文件中,再一个一个取出来?
# dic = {'key1' : 'value1','key2' : 'value2'}
# with open('json_file','w') as f:
# str_dic = json.dumps(dic)
# f.write(str_dic+'\n')
# str_dic = json.dumps(dic)
# f.write(str_dic + '\n')
# str_dic = json.dumps(dic)
# f.write(str_dic + '\n')
# with open('json_file','r') as f:
# for line in f:
# dic = json.loads(line.strip())
# print(dic.keys())
json.dumps(),各个参数含义
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
Iindent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
sort_keys:将数据根据keys的值进行排序。
import json
data = {'username':['呜呜呜','奋斗奋斗'],'sex':'m','age':24}
json_dic = json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False)
print(json_dic)

pickle
1、支持在python中几乎所有的数据类型
2、dumps 序列化的结果只能是字节
3、只能在python中使用
4、在和文件操作的时候,需要用rb wb的模式打开文
5、可以多次dump 和 多次load
import pickle
dic = {(1,2,3):{'a','b'},1:'abc'}
ret1 = pickle.dumps(dic)
print(ret1)
ret2 = pickle.loads(ret1)
print (ret2)

with open('pickle_file','wb') as f:
pickle.dump(dic,f)
with open('pickle_file','rb') as f:
ret = pickle.load(f)
print(ret,type(ret))

用于序列化的两个模块
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
这既然pickle如此强大,为什么还要学json呢?
这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。
如果我们将一个字典或者序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。
但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了~
所以,如果你序列化的内容是列表或者字典,我们非常推荐你使用json模块
但如果出于某种原因你不得不序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,那么就可以使用pickle

