

Python数据类型
Python3 中有六个标准的数据类型:
1、字节bytes
2、数字Number --------不可变
3、字符串String --------不可变、有序、有下标、可遍历
4、列表(List)---------可变、有序、有下标、、可遍历、可更改 、允许重复的成员
5、元组(Tuple)-------不可变、有序、有下标、可遍历、不可更改、允许重复的成员
6、集合(Set)----------可变、无序、无下标、可遍历、无重复
7、词典(Dictionary)--可变、有序、无下标但有索引、可遍历、没有重复的成员(key不可重复,要唯一)
所谓有序,即有顺序,即先添加的在前后添加的在后,输出的顺序和存储是的顺序是一致的。Python3.6 之前字典是无序的,Python3.6 之后字典是有序的
list是链表实现,set是hash表实现。
Python中的变量可以指向任意对象,可以将变量都看成是指针,保存了所指向对象的内存地址(对象的引用),对于不可变对象,如果要更新变量引用的不可变对象的值,会创建新的对象,改变对象的引用。
#字符串不可变
s='iopuyu'
print(id(s))
s=s.replace('o', 'K')
print(id(s))
print(s)
'''
1181201176176
1181208851184
iKpuyu
'''
#列表可变
s=['io','pu','yu']
print(id(s))
s[1]='PP'
print(id(s))
print(s)
'''
1181208959744
1181208959744
['io', 'PP', 'yu']
'''
零、运算符与转义符
1、运算符优先级

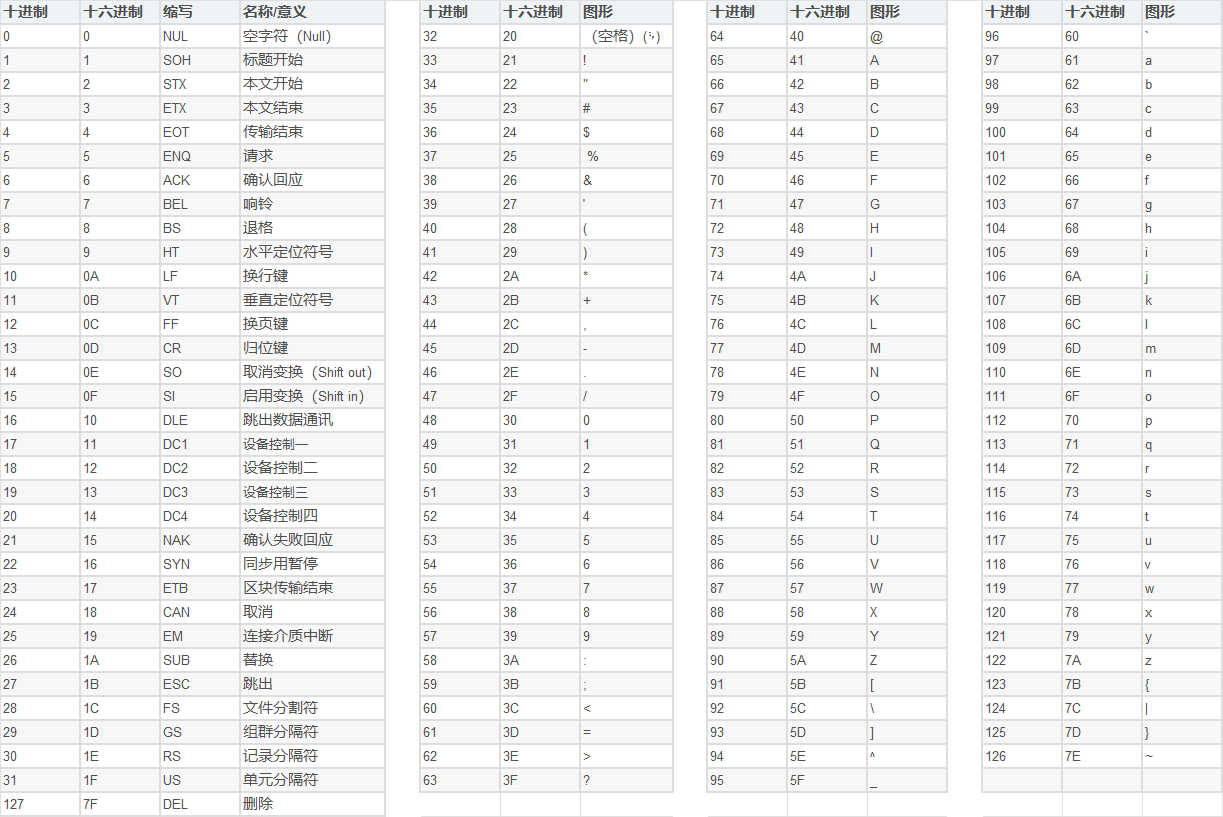
2、python中的字符串使用反斜杠(\)转义特殊字符
\(在行尾时) 续行符
\\ 反斜杠符号
\' 单引号
\" 双引号
\a ASCII响铃(BEL)
\b ASCII退格(BS)
\e ASCII转义
\000 空
\n 换行
\v 纵向制表符
\t 横向制表符
\r 回车
\f 换页
\oyy 八进制数yy代表的字符,例如:\o12代表换行
\xyy 十进制数yy代表的字符,例如:\x0a代表换行
\other 其它的字符以普通格式输出
如果不想让反斜杠发生转义,可以在字符串前面添加一个 r 或 R ,表示原始字符串。
一、字节bytes
Python 3对字符串和二进制数据流做了明确的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。bytes是不可变类型,一旦定义不可以修改。 Python有个内置函数bytes(),bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。除了bytes()外我们还可以用struct模块来执行字节到其它类型的转换。
b1 = bytes() # b" 空字节,一旦定义不可修改
print(b1) # b''
b2 = b''
print(b2) # b''
b2=1
print(bytes(b2)) # b'\x00'
b3=5
print(bytes(b3)) #b'\x00\x00\x00\x00\x00'
b3 = b'\x00\x00\x00\x00\x00'
print(b3) #b'\x00\x00\x00\x00\x00'
b4 = bytes('abc', 'utf-8')
print(b4) # b'abc'
b4 = b'abcd'
print(b4) #b'abcd'
b6 = bytes(range(10)) # bytes(iterable_of_ints)
print(b6 ) # 打印ascii表的前10个字符 b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t'
b6 = bytes(range(0x30, 0x3a)) #0x代表十六进制
print(b6) #b'0123456789'
b7=bytes(range(65, 91))
print(b7) #b'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
# 与字符串不同,字符串遍历出来的是字符类型,但bytes遍历出来的是int类型
b8 = bytes(range(65,91,2))
print(b8) #b'ACEGIKMOQSUWY'
print(b8[0]) #65
b9 = bytes(range(65,91,2))
for i in b9:
print(i, end="~") # 打印出来的是int类型,不是字符类型 65~67~69~71~73~75~77~79~81~83~85~87~89~
# 字符串的方法,bytes基本可以用。
ss1=b'a' + b'bcde'
print(ss1) #b'abcde'
ss2=b"a" in b'abc'
print(ss2) #True
ss3=b'abc'.index(b'a')
print(ss3) #0
ss4=b'abc'.find(b'bcd')
print(ss4) #-1
ss5=b'aabbccdd'.replace(b'bc',b'--')
print(ss5) #b'aab--cdd'
ss6=b'boygirlmanboywonmen'.split(b'boy')
print(ss6) # [b'', b'girlman', b'wonmen'] 切割出的结果也是bytes
ss7=b'abc'.partition(b'b') #(b'a', b'b', b'c')
print(ss7 )
ss8=b'abc'.startswith(b'a')
print(ss8 )#True
#整型int-->字节bytes
b1 = 5
print(b1.to_bytes(2, 'big')) #b'\x00\x05'
#字节bytes-->整型int
b2 = b'\xf1\xff'
print(int.from_bytes(b2, byteorder='little', signed=True)) #-15
#字符str-->字节bytes
b3=bytes('ertyuy', encoding='utf-8')
b4='ertyuy'.encode('utf-8')
print(b3) #b'ertyuy'
print(b4) #b'ertyuy'
#字节bytes-->字符str
b5=b'ertyuy'.decode('utf-8')
print(b5) #'ertyuy'
# 十六进制hex-->字节bytes
s3= bytes.fromhex('090d0a4142') # 注意,字符串的16进制前面无需加0x
print(s3) # b'\t\r\nAB'
#字节bytes-->十六进制hex
s4=b'\t\r\nAB'
print(s4.hex()) # 090d0a4142
二、数字 Number
Python3 支持数字型有 int、float、bool、complex(复数)。 int表示为长整型。
/除法计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数: //除法称为地板除,两个整数的除法仍然是整数: %表示余数运算 n**2 n的平方 n**3 n的立方 n**m n的m次方 n**(1/2) n的平方根 n**(1/3) n的立方根
1)数字类型
1)、布尔类型 布尔型是一种比较特殊的python数字类型,它只有True和False两种值(必须大写第一个字母) print(int(True)) # 1 print(int(False)) # 0 2)、整数 i=20; print(i) 3)、浮点数 fl=2.3; print(fl)
2)、数字类型转换
int(x) 将x转换为一个整数
float(x ) 将x转换到一个浮点数
complex(real [,imag]) 创建一个复数
str(x) 将对象x转换为字符串
eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象
chr(x) 将一个整数转换为一个字符,python3中chr()不仅支持Ascii的转换,也适用的Unicode转换
ord(x) 将一个字符转换为它的整数值
print(ord('a')) #97
print(chr(98)) #b
3)进制
# int(str,base)->int
# bin(int) -> str
# oct(int) -> str
# hex(int) -> str
#其他进制转10进制
print("2进制转10进制",int("0b101",2)) #2进制转10进制 5
print("2进制转10进制",int(0b101)) #2进制转10进制 5
print("8进制转10进制",int("0o12",8))
print("8进制转10进制",int(0o12))
print("16进制转10",int("0xff",16))
print("16进制转10",int(0xff))
#10进制转其他进制
n=62
print(bin(n)) # 0b111110
print(oct(n)) # 0o76
print(hex(n)) # 0x3e
#其他进制互转
print("8进制转2进制",bin(int('0o10',8))) # 8进制转2进制 0b1000
print("16进制转2进制",bin(int('0x10',16))) # 16进制转2进制 0b10000
print("2进制转8进制",oct(int('0b11',2))) # 2进制转8进制 0o3
print("16进制转8进制",oct(int('0x15',16))) # 16进制转8进制 0o25
print("2进制转16进制",hex(int('0b11',2))) # 2进制转16进制 0x3
print("8进制转16进制",hex(int('0o23',8))) # 8进制转16进制 0x13
#原理:先将读入的字符串 x 进行转换为十进制,再由十进制进行相关的转换
4)、数学函数
abs(x) 返回数字的绝对值,如abs(-10) 返回 10
fabs(x) 返回数字的绝对值,如math.fabs(-10) 返回10.0
ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5
floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4
max(x1, x2,...) 返回给定参数的最大值,参数可以为序列。
min(x1, x2,...) 返回给定参数的最小值,参数可以为序列。
modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。
round(x [,n]) 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。
pow(x, y) x**y 运算后的值。
sqrt(x) 返回数字x的平方根,数字可以为负数,返回类型为实数,如math.sqrt(4)返回 2+0j
log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0
log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0
cmp(x, y) 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1
exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045
三、字符串 String
1)使用单/双引号(')
#用单引号/双引号括起来表示字符串 str='this is string' print (str) #this is string str="this is string" print (str)#this is string str='' #生成一个空字符串 print (str) #
2)使用三引号(''')
利用三引号表示多行的字符串,可以在三引号中自由的使用单引号和双引号
str='''this is string 1 this is string 2 this is string 3'''
print (str)
3)字符串可以使用 + 运算符串连接在一起,或者用 * 运算符重复
text = 'ice'+' cream' print(text) #ice cream text = 'ice cream '*3 print(text) #ice cream ice cream ice cream
4) Python访问字符串中的字符
Python不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。访问子字符串,可以使用方括号来截取字符串:
var1 = 'Hello World!' var2 = "Python Runoob" print(var1[0]) # H print (var2[1:5]) #ytho
5)int与string之间的转化
int('12') #10进制string转化为int
int('12', 16) #16进制string转化为int
6)list与string之间的转化
str1 = "12345"
list1 = list(str1)
print(list1) #['1', '2', '3', '4', '5']
str3 = "www.google.com"
list3 = str3.split(".")
print(list3) #['www', 'google', 'com']
str5 = ".".join(list3)
print(str5) #www.google.com
7)常用字符串方法:(假设字符串变量名为s)

strip函数
print(s.strip("xx")) # 删除s字符串中开头、结尾处的xx字符 , 当xx为空时默认删除空白符(包括'\n', '\r', '\t', ' ')
1)字符串函数
str = "this is string example!";
print (str.startswith( 'this' ) )#true
print (str.startswith( 'is', 2 )) #true
a=input().lower() #将输入字符都转换为小写字符
b=input().upper()#将输入字符都转换为大写字符
print(a.count(b))#统计a字符串中有多少个b字符
i='hjUIkun'
print(i.swapcase()) #HJuiKUN 大写变小写,小写变大写
i='hjUIkun'
print(i.rfind('u')) #5
i='hjUIkun'
print(i.find('u')) #5
i='hjUIkun'
print(i.index('u')) #5
i='hjUIkun'
print(i.rindex('u')) #5
i='kl'
print(i.zfill(8)) #000000kl
i='hjUIkun'
print(i.rjust(12,'*')) #*****hjUIkun
i='hjUIkun'
print(i.ljust(12,'*')) #hjUIkun*****
#按长度划分
ls='0F04ABABABAB1001FF'
ll=[ls[i:i+3] for i in range(0,len(ls),3)]
print(ll) #['0F0', '4AB', 'ABA', 'BAB', '100', '1FF']
#split按字符分割,不带参数,默认是空白字符。
str = ('www.google.com')
print (str.split()) # ['www.google.com'] split函数返回的是一个列表
#split按字符分割,按某一个字符分割:
str = ('www.google.com')
print(str.split('.')) # ['www’,’google’,’com']
#split按字符分割,按某一个字符分割,且分割n次。
url = 'www.google.com'
print(url.split('.', 1)) #['www', 'google.com'] 按‘.’分割字符,且分割1次
# splitline()按行进行字符串分割
a = '''I have a pen
I have a apple
apple pen
'''
print(a.splitlines()) #['I have a pen','I have a apple','apple pen']
#partition() 方法用来根据指定的分隔符将字符串进行分割。只分一次。返回一个 3 元的元组,
# 第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。
ss1='abcefghijklmn'.partition('a') #('', 'a', 'bcefghijklmn')
print(ss1)
ss2='abcefghijklmn'.partition('b') #('a', 'b', 'cefghijklmn')
print(ss2)
ss3='abcefghijklmn'.partition('ab') #('', 'ab', 'cefghijklmn')
print(ss3)
s='asd'
print(set(s)) #{'a', 's', 'd'}
s='asd'
print(list(s)) #['a', 's', 'd']
#字符串去重
y='werwwwtre'
print(''.jion(set(y))) #rwet 顺序乱了
#字符串去重
s='werwwwtre'
ll=str()
for i in s:
if i not in ll:
ll+=i
print(ll) #wert 顺序正确
#字符串比较
s1='aw'
s2='wa'
s3='aw'
print(s1==s2) #False
print(s1==s3) #True
#字符串排序
s1='saertyt'
s1=''.join(sorted(s1))
print(s1) #aerstty
#删除字符串中的某个字符
n='wertyurewerthhhjh'
m = n.replace('h', "")
print(m)#wertyurewertj
k = n.replace('h', "",2)
print(k)#wertyurewerthjh 只替换掉2个
8)字符串切片(slice)
切片操作(slice)可以从一个字符串中获取子字符串(字符串的一部分)。
格式:[start:end:step] #一对方括号、起始偏移量start、终止偏移量end 、可选的步长step
• [start:] 从start 提取到结尾
• [:end] 从开头提取到end - 1
• [start:end] 从start 提取到end - 1
• [:] 提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串
• [start:end:step] 从start 提取到end - 1,每step 个字符提取一次
letter = 'abcdefghijklmnopqrstuvwxyz' print(letter[-3:]) #'xyz' 提取最后N个字符 从倒数第三个一直到结尾 print(letter[:-3]) #'abcdefghijklmnopqrstuvw' 从开始到倒数第三个 print(letter[::5]) #'afkpuz' 从开头到结尾,每隔5字符取一次 print(letter[::-1]) #'zyxwvutsrqponmlkjihgfedcba' 将字符串倒转
9)格式化输出 %
hostname = 'nihaowodepengyou'
print('%30s' % str(hostname) ) #右对齐
hostname = 'nihaowodepengyou'
print('%-30s' % str(hostname) )#左对齐
10)格式化输出 f-string (python3.6引入)
name = "Huang Wei"
print(f"my name is {name}") # my name is Huang Wei
name = "Huang Wei"
print(f"my name is {name.lower()}") # my name is huang wei
num = 2
print(f"I have {num} apples") # I have 2 apples
print(f"They have {2+5*2} apples") # They have 12 apples
print(f'I am "Huang Wei"') # I am "Huang Wei"
print(f"{{5}}{'apples'}" )# {5}apples
#乘法表
for i in range(1,10):
for j in range(1,i+1):
print(f"{j}*{i}={j*i}",end=" ")
# print('\n')
print()
name1 = "Huang Wei"
name2 = "Huang Wei werw werwerw ryeryty"
a = 123.456
b = 23545476569878078967554
#只指定宽度
print(f"{name1:20}") #'Huang Wei ' 当不满指定宽度时,左边用默认的空格填充
print(f"{name1:>20}") #' Huang Wei' 当不满指定宽度时,左边用默认的空格填充
print(f"{name2:>20}") #'Huang Wei werw werwerw ryeryty' 当超过指定宽度时,按实际输出
print(f"{name1:<20}") #'Huang Wei '
print(f"{name1:^20}") #' Huang Wei '
print(f"{a:10}") #' 123.456' 不满指定宽度时,用空格在左边填充
print(f'{b:10}') # 23545476569878078967554 超过指定宽度时,按实际输出
print(f'{a:<10}') #123.456
#宽度和填充
print(f"{a:*>10}") # ***123.456 居右,不满指定宽度时,用0在左边填充
print(f"{a:*^10}") # *123.456** 居中,不满指定宽度时,用0在两边边填充
print(f"{name1:_>20}") #'___________Huang Wei' 当不满指定宽度时,左边用指定字符填充
print(f"{name2:_>20}") #'Huang Wei werw werwerw ryeryty' 当超过指定宽度时,按实际输出
# 宽度和精度/截断
print(f"{name2:>10.2s}") #' Hu' 总宽度为10,只输出2个字符,左边边用默认的空格填充
print(f"{name1:_>10.3s}") #'_______Hua' 总宽度为10,只输出3个字符,左边边用的空指定的_填充
print(f"{name1:_<10.3s}") #'Hua_______' 总宽度为10,只输出3个字符,右边边用的空指定的_填充
print(f"{a:8.2f}") #' 123.46' 总宽度为8(包括小数点),其中小数为2位
print(f"{a:<8.2f}") #'123.46 ' 总宽度为8(包括小数点),其中小数为2位,不满8位时,右边用默认的空格填充
print(f"{a:*>8.2f}") #'**123.46' 总宽度为8(包括小数点),其中小数为2位,不满8位时,右边用指定的*填充
print(f"{a:.2f}") #'123.46' 没有总宽度,只精确2位小数
print(f"{a:f}") #'123.456000' 没有点号时表示补足小数点后的位数至默认精度6
#整数位始终会输出。宽度小于精度,以精度为准
print(f"{a:<4.5f}") # 123.45600 宽度小于精度,以精度为准
print(f"{b:<8.2f}") #'23545476569878077898752.00'总宽度为8(包括小数点)小于位数,按实际输出
3、f-string针对date、datetime和time对象,进行年月日、时分秒等信息提取
from datetime import *
a = date.today() # today()返回本地时间的一个date对象
print(f"{a:%Y-%m-%d}") #'2020-02-01'
四、列表 list---用[ ]符号表示
1)、初始化列表,例如:
ls1=[(4,3),('B','f','ui','o'),(8,9,0)]
print(ls1) #[(4, 3), ('B', 'f', 'ui', 'o'), (8, 9, 0)]
ls2=[{4,3},{'B','f','ui','o'},{8,9,0}]
print(ls2) #[{3, 4}, {'ui', 'B', 'f', 'o'}, {8, 9, 0}]
ls3=[{'A':3},{'B':2},{'C':0}]
print(ls3) #[{'A': 3}, {'B': 2}, {'C': 0}]
2)、访问列表中的值:
ls=[2,5,4,7,8,9] print(ls) #[2, 5, 4, 7, 8, 9] 输出整个列表 print(ls[:]) #[2, 5, 4, 7, 8, 9] 输出整个列表 print (ls[1:] ) #[5, 4, 7, 8, 9] 从下标1输出到最后 print( ls[2:5]) #[4, 7, 8] 从下标2输出到下标4 print( ls[2:9]) #[4, 7, 8, 9] 此种情况超出不会报错,默认以列表长度结束 print( ls[:-2]) #[2, 5, 4, 7] 从开始输出到倒数第3个 print( ls[:3]) #[2, 5, 4] 输出前3个 print( ls[-3:]) #[7, 8, 9] 从倒数第3个输出到结束,即最后3个 print(ls[::7]) #[2] 间隔长度大于等于列表长度时只输出第一个 print(ls[::2]) #[2, 4, 8] 隔一个输出
3)、更新列表:
#更新列表 nums=[1, 3, 5, 7, 8, 13, 20] nums[1]="tyu" print(nums) #[1, 'tyu', 5, 7, 8, 13, 20] #插入 lis=[1,10,100,1000,10000,100000] lis.insert(2,88) print(lis) #[1, 10, 88, 100, 1000, 10000, 100000]
4)、列表操作符
列表对+和*的操作符与字符串相似。+号用于组合列表,*号用于重复列表,例如:
num1=[1,2,3] num2=[4,5,6,7] print(num1+num2) # [1, 2, 3, 4, 5, 6, 7] print ( ['Hi!'] * 4) #['Hi!', 'Hi!', 'Hi!', 'Hi!'] print (3 in [1, 2, 3]) #True a = [1, 2, 3] a = [] #清空列表 a = [1] a = a + [1] print(a) #[1, 1]
#1. pop(index) 是按索引号来删除列表中对应的元素,也可以不传参这时将最后一个元素删除。(append是加到列表最后)
listA = ['a', 'b', 'c','a', 'b', 'c', 'a', 'b','c']
print(listA.pop(3)) #'a'
print(listA) #['a', 'b', 'c', 'b', 'c', 'a', 'b', 'c']
#2. remove(参数)根据值来删除,该函数的参数不能为空。
listA = ['a', 'b', 'c','a', 'b', 'c', 'a', 'b','c']
listA.remove('a')
print(listA) #['b', 'c', 'a', 'b', 'c', 'a', 'b', 'c']
#3.del根据索引来删除,可删除一个或多个
listA = ['a', 'b', 'c','a', 'b', 'c', 'a', 'b','c']
del listA[1]
print(listA) #['a', 'c', 'a', 'b', 'c', 'a', 'b', 'c']
del listA[1:4]
print(listA) #['a', 'c', 'a', 'b', 'c']
del listA
5)、列表截取与组合
#截取 L=['111', '222', '333','444']; print (L[0]) #111 print (L[2]) #333 print (L[-1]) #444 print (L[1:]) # ['222', '333', '444'] print (len(L)) #4 计算列表元素的个数 #组合 extend方法 c1 = ["Red","Green","Blue"] c2 = ["Orange","Yellow","Indigo"] c1.extend(c2) c1 #["Red","Green","Blue","Orange","Yellow","Indigo"] 直接相加 c1 = ["Red","Green","Blue"] c2 = ["Orange","Yellow","Indigo"] c3 = c1 + c2 c3 # ["Red","Green","Blue","Orange","Yellow","Indigo"]
x = [1,2,3,4,5,6] print(x[:3]) # 前3个[1,2,3] print(x[1:5]) # 中间4个[2,3,4,5] print(x[-3:] ) # 最后3个[4,5,6] print(x[::2]) # 奇数项[1,3,5] print(x[1::2]) # 偶数项[2,4,6] print(x[::-1]) #列表逆序 [6, 5, 4, 3, 2, 1] ll=[1,4,6,5,9,2,7] n=len(ll) print(ll[4:n+1]) #[9, 2, 7] 因为右边是取不到的,所以不会出现n+1超界的问题
#1,借用sum函数
a = [[1],[2],[3],[4],[5],[6]]
b = [[1,2],[3],[4,[5],6]]
print(a)
print(sum(a,[])) #[1, 2, 3, 4, 5, 6] sum函数将二维数组转换为一维
print(sum(b,[])) #[1, 2, 3, 4, [5], 6]
#2、把列表转为字符串,再将字符转为list
a = [[12,34],[57,86,1],[43,22,7],[1,[2,3]],6]
b = str(a) #[[12, 34], [57, 86, 1], [43, 22, 7], [1, [2, 3]], 6]
b = b.replace('[','') #替换掉[
b = b.replace(']','') ##替换掉]
print(b) #12, 34, 57, 86, 1, 43, 22, 7, 1, 2, 3, 6
a = list(eval(b)) #字符串转化成整数,再转化成列表
print(a) #[12, 34, 57, 86, 1, 43, 22, 7, 1, 2, 3, 6]
#3.for循环
b = [[1,2],[3],[4,[5],6]]
B=[x for y in b for x in y]
print(B) #[1, 2, 3, 4, [5], 6]
###一维转二维
ss=[1,2, 3]
tt=[4,5,6,7,8]
#zip(*)功能类似矩阵的行列转换
mm=list(zip(ss,tt))
print(mm) #[(1, 4), (2, 5), (3, 6)]
for i in range(len(mm)):
mm[i]=list(mm[i])
print(mm) #[[1, 4], [2, 5], [3, 6]]
###二维压缩
vv=[[1, 4], [2, 5], [3, 6]]
uu=[(1, 4), (2, 5), (3, 6)]
print(list(zip(*vv))) #[(1, 2, 3), (4, 5, 6)]
print(list(zip(*uu))) #[(1, 2, 3), (4, 5, 6)]
###二维列表排序
students = [[3,'Jack',14],[2,'Rose',16],[1,'Tom',18],[5,'Sam',15],[4,'Joy',20]]
#按学号顺序排序:
s1=sorted(students,key=lambda x:x[0])
print(s1) #[[1, 'Tom', 18], [2, 'Rose', 16], [3, 'Jack', 14], [4, 'Joy', 20], [5, 'Sam', 15]]
#要求对列表首先按身高排序,然后按体重排序.
#方法1
#两次排序都是针对整个序列的,所以要先排体重再排身高
players1 = [[181, 70],[182, 70],[183, 70], [184, 70], [185, 70], [186, 70], [180, 71], [180, 72], [180, 73], [180, 74], [180, 75]]
# 首先根据体重排序
players1.sort(key=lambda x:-x[1])
print(players1)
# 然后根据身高排序
players1.sort(key=lambda x:-x[0])
print(players1)
#[[186, 70], [185, 70], [184, 70], [183, 70], [182, 70], [181, 70], [180, 75], [180, 74], [180, 73], [180, 72], [180, 71]]
#方法2
#两次排序是不一样的,主关键字针对整个序列,次关键只针对主关键字相同的部分
players2 = [[181, 70],[182, 70],[183, 70], [184, 70], [185, 70], [186, 70], [180, 71], [180, 72], [180, 73], [180, 74], [180, 75]]
# 主关键字为身高,次关键字为体重
players2.sort(key=lambda x:(-x[0],-x[1]))
print(players2)
#[[186, 70], [185, 70], [184, 70], [183, 70], [182, 70], [181, 70], [180, 75], [180, 74], [180, 73], [180, 72], [180, 71]]
###用列表推导式的方法创建一个5行5列的二维列表:
s1 = [[j for j in range(5)] for i in range(5)]
print(s1) #[[0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4]]
#用列表推导式的方法创建一个3行5列的二维列表:
s2 = [[j for j in range(5)] for i in range(3)]
print(s2) #[[0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4]]
###二维列表按列取元素。
a=[[1,2,3], [4,5,6]]
b = [i[0] for i in a] # 从a中的每一行取第一个元素。
print(b) #[1, 4]
# python中列表增加元素有四种方式:
# append():在列表末尾添加一个元素
# extend():在列表末尾添加至少一个元素
# insert():在列表任意位置添加一个元素
# 切片:在列表任意位置添加至少一个元素
#切片添加
lst1 = ["KO", "no", "99", "da"]
lst2 = ["fg", "yyj"]
lst1[2:3] = lst2 #从索引为2的位置开始,使用lst2的元素填充
print(lst1) #['KO', 'no', 'fg', 'yyj', 'da']
#insert
k=['b','c']
k.insert(0,'a')
print(k) #['a','b','c']
9)Python中List的复制(直接复制、浅拷贝、深拷贝)
#直接赋值: #直接赋值为非拷贝方法。这两个列表是等价的,修改其中任何一个列表都会影响到另一个列表。 old = [1,[1,2,3],3] new = old new[0] = 3 new[1][0] =3 print(old) #[3, [3, 2, 3], 3] print(new) #[3, [3, 2, 3], 3] #浅拷贝: #对于List来说,其第一层,是实现了深拷贝,但对于其内嵌套的List,仍然是浅拷贝。 # 因为嵌套的List保存的是地址,复制过去的时候是把地址复制过去了,# 嵌套的List在内存中指向的还是同一个。 #for循环,分片,列表生成式等来进行的拷贝的也是浅拷贝
import copy old = [1,[1,2,3],3] new = old.copy() print(old) #[1, [1, 2, 3], 3] print(new) #[1, [1, 2, 3], 3] new[0] = 3 new[1][0] =3 print(old) #[1, [3, 2, 3], 3] print(new) #[3, [3, 2, 3], 3] #深拷贝: #如果用deepcopy()方法,则无论多少层,无论怎样的形式,得到的新列表都是和原来无关的,这是最安全最清爽最有效的方法。 import copy old = [1,[1,2,3],3] new = copy.deepcopy(old) print(old) #[1, [1, 2, 3], 3] print(new) #[1, [1, 2, 3], 3] new[0] = 3 new[1][0] =3 print(old) #[1, [1, 2, 3], 3] print(new) #[3, [3, 2, 3], 3]
10)、列表函数&方法

列表反转
L=[1,2,3,4,5,6,7] L.reverse() print(L) #[7, 6, 5, 4, 3, 2, 1]
列表去重
# 使用set方法, 会改变列表原顺序
t_list = [1, 0, 3, 7, 7, 5]
r_list = list(set(t_list))
print(r_list) # [0, 1, 3, 5, 7] 顺序乱了
# 使用keys()方法, 不改变列表原顺序
t_list = [1, 0, 3, 7, 7, 5]
r_list = list({}.fromkeys(t_list).keys())
print(r_list) # [1, 0, 3, 7, 5]
# 按照索引再次排序方法, 不改变列表原顺序
t_list = [1, 0, 3, 7, 7, 5]
r_list = list(set(t_list))
r_list.sort(key=t_list.index)
print(r_list) #[1, 0, 3, 7, 5]
根据值求索引
s1=['s','a','e','r','t','y','t']
print(s1.index('r')) #3
print(s1.index('r',2)) #3 指定从第三号索引处开始(索引是从0开始的)
print(s1.index('r',4)) #'r' is not in list
排序与其他
ll='1 3 5 7 2' num=[int(i) for i in ll.split()] #用列表生成表达式将字符转换为数字 num.sort() print(num) #[1, 2, 3, 5, 7] ll='1 3 5 7 2' arr=sorted(map(int,ll.split())) #用map高级函数将字符序列转换为数字 print(arr) #[1, 2, 3, 5, 7] ll='1 3 5 7 2' num=ll.split() num.sort() print(num) #['1', '2', '3', '5', '7'] S1=['1','4','3','5','2','7','6'] S1[::2] = sorted(S1[::2]) # 奇数位置从小到大排序 S1[1::2] = sorted(S1[1::2]) # 偶数位置从小到大排序 print(S1) #['1', '4', '2', '5', '3', '7', '6'] print(*[i for i in range(1,5)]) #1 2 3 4 print([i for i in range(1,5)]) #[1, 2, 3, 4]
五、元组tuple--- 用( )符号表示
元组与列表的区别在于列表是可变对象,而元组是不可变对象,元组的元素不能修改,元组一旦初始化就不能修改;
元组使用小括号();元组创建很简单,只需要在括号中添加元素,并使用逗号,隔开即可;
元组中只有一个元素时,需要在元素后面添加逗号
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
#创建
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = "a", "b", "c", "d"
tup3 = tuple((1,2,3,4,5,6))
tup4 = (50,) #元组中只有一个元素时,需要在元素后面添加逗号
tup5 = () #创建空元组
#访问
print(tup1) #('physics', 'chemistry', 1997, 2000)
print(tup2) #('a', 'b', 'c', 'd')
print(tup3) #(1, 2, 3, 4, 5, 6)
print(tup4) #(50,)
print(tup5) #()
print (tup1[0]) #physics
print (tup1[1:3]) # ('chemistry', 1997)
#修改------元组中的元素值是不允许修改的
tup1[0] = 100 #修改元组元素操作是非法的
#增加元素
ele = 555
demo1 = tup3 + (ele,)
print(demo1)
demo2 = tup1 + tup2
print (demo2) # ('physics', 'chemistry', 1997, 2000, 1, 2, 3, 4, 5)
demo3 = tup2 + tup1
print (demo3) # (1, 2, 3, 4, 5, 'physics', 'chemistry', 1997, 2000)
#删减元素
demo4=tup3[:1]+tup3[2:]
print (demo4) #(1, 3, 4, 5, 6)
#删除元组---删除整个元组
del tup2
print (tup2)
#切片,元组被称为只读列表,字符串的切片操作同样适用于元组
tu = ("span",[18,188,1888],["python",123,666],"金融","FX-EXchange")
tu[1][2] = 808 #将1888,改成808
print(tu) #('span', [18, 188, 808], ['python', 123, 666], '金融', 'FX-EXchange')
#在列表后面添加9999
tu[1].append(999)
print(tu) #('span', [18, 188,808,9999], ['python', 123, 666], '金融', 'FX-EXchange')
in 判断某个元素是否在序列中,在就返回True,不在就返回False
3 in (1, 2, 3, 4) => True
not in 判断某个元素是否不在序列中,不在就返回True, 在就返回False
3 not in(1, 2, 3, 4) => False
元组内置函数
cmp(tuple1, tuple2) 比较两个元组元素。
len(tuple) 计算元组元素个数。
max(tuple) 返回元组中元素最大值。
min(tuple) 返回元组中元素最小值。
tuple.count(x) 返回元组中x的个数
tuple()以一个序列作为参数,并把它转换为元组。
tuple([1, 2, 3]) => (1, 2, 3)
tuple('hello') => ('h','e', 'l', 'l', 'o')
tuple(('hello', 'world')) => ('hello', 'world')
六、集合Set 使用大括号 { }
集合是一个无序不重复元素的序列。不可像列表一样直接修改集合,可以先删除再添加
1、集合的创建和使用
创建有值集合使用{}或set(), 但创建空集合只能使用set(),因为{}用来创建空字典
a=set() #创建一个空集合
b= set('abracadabra')
print(b) #{'c', 'd', 'a', 'r', 'b'}
c= {'m', 'J', 'y', 'T', 'ack'}
print(c) #{'T', 'ack', 'm', 'J', 'y'}
d= {'alacazam'}
print(d) #{'alacazam'}
e= {'m', 'J', 'y', 'T', 'ack'}
e.add('2345')
print(e) #{'m', 'y', 'T', 'J', '2345', 'ack'}
f= {'alacazam'}
f.add('2345')
print(f) #{'alacazam', '2345'}
ss1={1,2,3,4,5,6}
print(len(ss1)) #6
2、集合取值
1、遍历取值
#注意集合与列表和元组不同,集合是无序的,所以无法通过数字进行索引获取某一个元素的值
ss2 = {'Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'}
for i in ss2:
print(i) #Jack Jim Mary Rose Tom 每次打印的顺序是不一致的(如果是list则每次都是与原来一样的顺序)
2、转化为列表再取值
list_a = {"张三", "李四", "王二"}
list_b = list(list_a) # 先把集合转成列表
print(list_b)
3、集合可以进行集合运算
^运算符(a和b中不同时存在的元素)
l1={1,2,3,4,5,6}
l2={7,8,9,10,11}
print(l1|l2) #{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11} 并集
l1={1,2,3,4,5,6}
l2={7,8,9,4,5}
print(l1|l2) #{1, 2, 3, 4, 5, 6, 7, 8, 9} 并集
l1={1,2,3,4,5,6}
l2={7,8,9,10,11}
print(l1&l2) #set() 交集
l1={1,2,3,4,5,6}
l2={7,8,9,10,1}
print(l1&l2) #{1} 交集
l1={1,2,3,4,5,6}
l2={7,8,9,10}
print(l1-l2) #{1, 2, 3, 4, 5, 6} 差集
l1={1,2,3,4,5,6}
l2={7,8,9,10,1}
print(l1-l2) #{2, 3, 4, 5, 6} 差集
l1={1,2,3,4,5,6}
l2={7,8,9,10}
print(l1^l2) #{1, 2, 3, 4, 5, 6, 7, 8, 9, 10} 补集
l1={1,2,3,4,5,6}
l2={7,8,9,10,1}
print(l1^l2) #{2, 3, 4, 5, 6, 7, 8, 9, 10} 补集
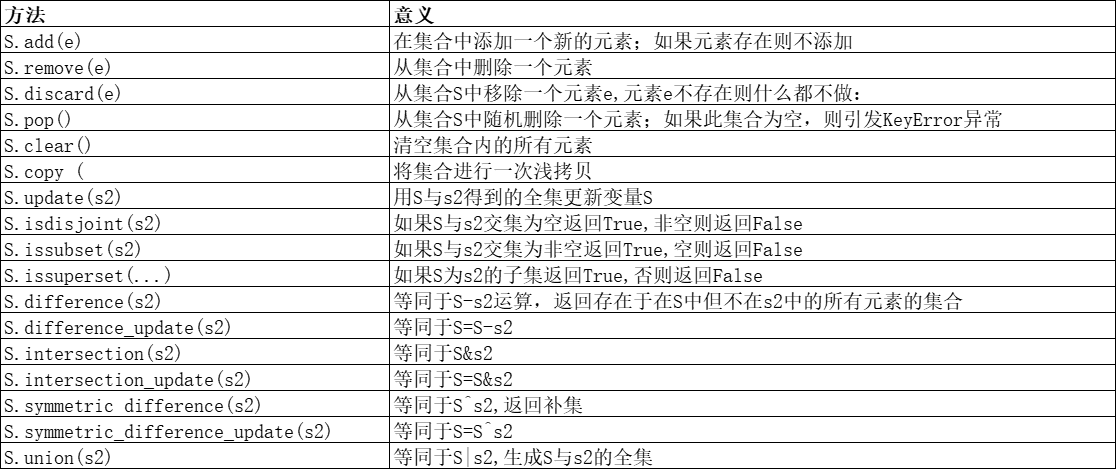
set1 = {'name', 19, 'python'}
set1.add('abc') # 可变集合,直接修改原来集合
print(set1) #{'python', 19, 'name', 'abc'}
set1.add('name') #添加已有的元素,集合不变
print(set1) #{'python', 19, 'name', 'abc'}
set1 = {'name', 19, 'python'}
set1.remove('python') # 删除指定元素,如果没有,返回错误
print(set1)
set1 = {'name', 19, 'python'}
set1.discard('name') # 删除指定元素,如果没有,返回原集合
print(set1)
set1 = {'name', 19, 'python'}
set1.pop() # 随机删除一个可变集合元素,因为集合无序
print(set1)
set1 = {'name', 19, 'python'}
set1.clear() # 清空可变集合中的所有元素
print(set1) #set()
set1 = {'name', 19, 'python'}
del set1 # 清除集合
print(set1) # NameError: name 'set1' is not defined
set1 = {'name', 19, 'python'}
a_tuple = ('a', 'b', 'c') #集合,列表,元组,字符串
set1.update(a_tuple)
print(set1)
七、字典 Dictionary用{ }符号表示
1)、字典简介
字典是有序的对象集合。字典也被称哈希表。字典是键(key) : 值(value)对的组合。
键(key)必须使用不可变类型且须独一无二;值(value)可以取任何数据类型,常见为字符串,数字,但也可以是:列表,元组,集合,字典。
dict 1= {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'} # 创建字典
dict2 = { 'abc': 123, 98.6: 37 } # 创建字典
dict3 = { } # 创建空字典
2)、使用字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对:
d={'rr':2,'j':43,'t':90}
print('rr' in d) # True
#输出整个字典
student ={'name': 'Zara', 'age': 7, 'class': 'First'}
print(student) #{'name': 'Zara', 'age': 7, 'class': 'First'}
dic = {'user1':67, 'user2':92,'user3':58}
key=list(dic.keys())[0]
print(key) # user1根据字典的索引号取key
#输出字典的所有key
student ={'name': 'Zara', 'age': 7, 'class': 'First'}
print(student.keys()) #dict_keys(['name', 'age', 'class'])
#输出字典的所有value
student ={'name': 'Zara', 'age': 7, 'class': 'First'}
print(student.values()) #dict_values(['Zara', 7, 'First'])
#通过key找值
student ={'name': 'Zara', 'age': 7, 'class': 'First'}
v1=student['name']
v2=student.get('name')
print(v1) # Zara
print(v2) # Zara
# 通过值查找键
my_dict = {"apple": 2, "banana": 3, "orange": 4}
value = 3
key1 = [k for k, v in my_dict.items() if v == value][0]
key2 = {val: key for key, val in my_dict.items()}.get(value)
key3=list(my_dict.keys())[list(my_dict.values()).index(value)]
print(key1) # 输出:banana
print(key2) # 输出:banana
print(key3) # 输出:banana
3)
#反转字典
my_dict_1 = {"brand": "Ford","model": "Mustang", "year": 1964}
my_dict_2 = dict(map(reversed, my_dict_1.items()))
print(my_dict_2) #{'Ford': 'brand', 'Mustang': 'model', 1964: 'year'}
#字典逆序
my_dict_1 = {"brand": "Ford","model": "Mustang", "year": 1964}
print(dict(reversed(my_dict_1.items()))) #{'year': 1964, 'model': 'Mustang', 'brand': 'Ford'}
for i in reversed(my_dict_1):
print(i)
dic = {'user1':67, 'user2':92,'user3':58}
print(list(dic)) # ['user1', 'user2', 'user3']
ll=[(21, 4), (16, 2), (10, 1), (11, 1), (19, 1), (17, 1), (18, 1)] # 元组列表
print(dict(ll)) # {21: 4, 16: 2, 10: 1, 11: 1, 19: 1, 17: 1, 18: 1}
ls=[[21, 4],[16, 2],[10, 1],[11, 1],[19, 1],[17, 1],[18, 1]] # 二维列表
print(dict(ls)) # {21: 4, 16: 2, 10: 1, 11: 1, 19: 1, 17: 1, 18: 1}
4)字典遍历
#遍历字典的所有key1
student ={'name': 'Zara', 'age': 7, 'class': 'First'}
for i in student:
print(i) # name age class
#遍历字典的所有key2
student = {'num': '123456', 'name': 'kelvin', 'age': 18}
for i in student.keys():
print(i) #num name age
#遍历字典中所有的键值对
dis={'A': 3, 'B': 1, 'C': 0, 'D': 1, 'E': 3}
for k,v in dis.items():
print(k,':',v)
# A : 3
# B : 1
# C : 0
# D : 1
# E : 3
5)修改字典
#修改已有键的值
dict = {'name': 'Zara', 'age': 7, 'class': 'First'}
dict["age"]=27
print(dict)#{'name': 'Zara', 'age': 27, 'class': 'First'}
#向字典中添加键值---[]
book_dict = {"price": 500, "bookName": "Python设计", "weight": "250g"}
book_dict["owner"] = "tyson"
print(book_dict) #{'price': 500, 'bookName': 'Python设计', 'weight': '250g', 'owner': 'tyson'}
#向字典中添加键值---使用update()方法,参数为字典对象
book_dict = {"price": 500, "bookName": "Python设计", "weight": "250g"}
temp_dict = {"name": "王员外", "age":18}
book_dict.update({"name": "王员外", "age":18})#key不存在则是添加元素,key存在则会覆盖掉key对应的value
book_dict.update(temp_dict)
print(book_dict) #{'price': 500, 'bookName': 'Python设计', 'weight': '250g', 'country': 'china'}
#通过 json 来转换
import json
user_info= '{"name" : "john", "gender" : "male", "age": 28}'
user_dict = json.loads(user_info)
# #json反序列化
print(user_dict) #{'name': 'john', 'gender': 'male', 'age': 28}
6)、删除字典
aa={"name" : "john", "gender" : "male", "age": 28}
del aa['name'] #删除某个值:使用del函数
print(aa) #{'gender': 'male', 'age': 28}
vv = aa.pop('age') #以key为线索删除某个值,并返回该值的value
print(vv) # 28
print(aa) # {'name': 'john', 'gender': 'male'}
aa.clear() #删除整个字典
print(aa) # {}
del aa # 删除字典
print(aa) # name 'aa' is not defined
7)字典排序
person1 = {"li":18,"wang":50,"zhang":20,"sun":22}
db=sorted(person1)
print(db) #['li', 'sun', 'wang', 'zhang'] 按key对字典进行排序,最后以列表形式输出key (key首字母升序)
da=sorted(person1,key=lambda x:x[1])
print(da) #['wang', 'zhang', 'li', 'sun'] 按key对字典进行排序,最后以列表形式输出key (key第二字母升序)
dic1 = {'d': 2, 'c': 1, 'a': 3, 'b': 4}
sort_value = sorted(dic1.items(), key=lambda x:x[0], reverse=False)
print(sort_value) #[('a', 3), ('b', 4), ('c', 1), ('d', 2)]
print(dict(sort_value)) #{'a': 3, 'b': 4, 'c': 1, 'd': 2} 按key排序
dic2 = {'d': 2, 'c': 1, 'a': 3, 'b': 4}
sort_value = sorted(dic2.items(), key=lambda x:x[1], reverse=False)
print(dict(sort_value)) # {'c': 1, 'd': 2, 'a': 3, 'b': 4} 按value排序
dic3 = {'d': 2, 'c': 1, 'a': 3, 'b': 4}
sort_value = sorted(dic3.items(), key=lambda x:(x[1],x[0]), reverse=False)
print(dict(sort_value)) # {'c': 1, 'd': 2, 'a': 3, 'b': 4} 按key为主排序,value为次排序
8)
l1 = ["eat", "sleep", "repeat"]
l2 = "geek"
l3={'张三':90,'王五':87,'李四':99}
print (list(enumerate(l1))) #[(0, 'eat'), (1, 'sleep'), (2, 'repeat')]
print (list(enumerate(l2))) #[(0, 'g'), (1, 'e'), (2, 'e'), (3, 'k')]
print (list(enumerate(l3))) #[(0, '张三'), (1, '王五'), (2, '李四')]
#利用enumerate()函数取出字典键的序号和键名。
dd={'张三':90,'王五':87,'李四':99}
for index1,key in enumerate(dd):
print(index1,key,dd[key])
'''
0 张三 90
1 王五 87
2 李四 99
'''
from collections import Counter
ll='bcdeabacdabcaba'
c = Counter(ll)
print(c) #Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
print(c.most_common()) #[('a', 5), ('b', 4), ('c', 3), ('d', 2), ('e', 1)]
print(c.most_common(3)) #[('a', 5), ('b', 4), ('c', 3)]
print(dict(c)) #{'b': 4, 'c': 3, 'd': 2, 'e': 1, 'a': 5}
print(list(c)) #['b', 'c', 'd', 'e', 'a']
print(sorted(c)) #['a', 'b', 'c', 'd', 'e']
print (list(enumerate(c))) #[(0, 'b'), (1, 'c'), (2, 'd'), (3, 'e'), (4, 'a')]
9)字典的赋值,浅拷贝,深拷贝
# 赋值
dict1 = {'user': 100, 'num': [1, 2, 3]}
dict2 = dict1
dict1['user']=200
print(dict1) #{'user': 200, 'num': [1, 2, 3]}
print(dict2) #{'user': 200, 'num': [1, 2, 3]}
#浅拷贝
import copy
dict1 = {'user': 100, 'num': [1, 2, 3]}
dict3 = dict1.copy()
dict1["user"] = 300 # 修改父级
dict1["num"].remove(1) # 修改子级
print(dict1) #{'user': 300, 'num': [2, 3]}
print(dict3) #{'user': 100, 'num': [2, 3]}
dict3["user"] = 400 # 改变父级
dict3["num"].remove(3) # 改变子级
print(dict1) #{'user': 300, 'num': [2]}
print(dict3) #{'user': 400, 'num': [2]}
#深拷贝
import copy
dict1 = {'user': 100, 'num': [1, 2, 3]}
dict4 = copy.deepcopy(dict1)
dict1["user"] = 500 # 改变父级
dict1["num"].remove(3) # 改变子级
print(dict1) #{'user': 500, 'num': [1, 2]}
print(dict4) #{'user': 100, 'num': [1, 2, 3]}
dict4["user"] = 600 # 改变父级
dict4["num"].remove(2) # 改变子级
print(dict1) #{'user': 500, 'num': [1, 2]}
print(dict4) #{'user': 600, 'num': [1, 3]}
10)、字典内置函数&方法
len(dict) 计算字典元素个数,即键的总数。
str(dict) 输出字典可打印的字符串表示。
type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。
cmp(dict1, dict2) 比较两个字典元素。
dict.copy() 返回一个字典的浅复制
dict.update(dict2) 把字典dict2的键/值对合并到dict里
dict.clear() 删除字典内所有元素
dict.pop(key) 移除键同时返回该键的值
dict.fromkeys(seq,val) 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值
dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并未该键将设default默认值
dict.has_key(key) 如果键在字典dict里返回true,否则返回false
dict.items() 以列表返回可遍历的(键, 值) 元组数组 aa={11 : "john", 13 : "male", 12: 28}---->dict_items([(11, 'john'), (13, 'male'), (12, 28)])
dict.keys() 以列表返回一个字典所有的键
dict.values() 以列表返回字典中的所有键的值
将字典传给可变参数时fun(*dict),处理后得到的只有字典的key,value是没有的
将字典放入链表再传给可变参数时fun(*dict),处理后得到是完整的字典
将字典传给关键字参数时fun(**dict),处理后得到是完整的字典
t_list = [1, 0, 3, 7, 7, 5]
print({}.fromkeys(t_list)) #{1: None, 0: None, 3: None, 7: None, 5: None}
print({}.fromkeys(t_list,2)) #{{1: 2, 0: 2, 3: 2, 7: 2, 5: 2}
print({}.fromkeys(t_list).keys()) #dict_keys([1, 0, 3, 7, 5])
print(list({}.fromkeys(t_list).keys())) #[1, 0, 3, 7, 5]
#1、值为列表的构造方法 dic.setdefault(key,[]).append(value)
dic = {}
dic.setdefault('a',[]).append(1)
dic.setdefault('a',[]).append(2)
print(dic) # {'a': [1, 2]}
dic = {}
dic['a']=[]
dic['a'].append(1)
dic['a'].append(2)
print(dic) # {'a': {1, 2}}
#2、值为元组的构造方法 dic[key].add(value) 或 dic[key]={value}
dic = {}
dic.setdefault('a',(1,3,4,5))
print(dic) # {'a': (1, 3, 4, 5)}
dic = {}
dic['a']=(1,3,4,5)
print(dic) # {'a': (1, 3, 4, 5)}
#3、值为集合的构造方法 dic[key].add(value) 或 dic[key]={value}
dic = {}
dic['a']=set() #或dic['a']={2}
dic['a'].add(2)
dic['a'].add(5)
print(dic) # {'a': {2, 5}}
#4、值为字典的构造方法 dic.setdefault(key,{})[value] =1
dic = {}
dic.setdefault('b',{})['f']=1
dic.setdefault('b',{})['h']=1
dic.setdefault('b',{})['g']=1
print(dic) #{'b': {'h': 1, 'g': 1, 'f': 1}}
dic = {}
dic['b']={}
dic['b']={'h': 1, 'g': 1, 'f': 1}
print(dic) #{'b': {'h': 1, 'g': 1, 'f': 1}}

