1、系统IO模型
1.1、消息通信机制
1、同步和异步
同步:进程发出请求调用后,进程会一直处于等待状态,直到内核返回响应消息以后才能进行下一步操作,如果内核一直不返回数据,那么进程就会一直等待内核响应消息。
异步:进程发出请求调用后,进程无需等待内核返回响应消息,会进行其他的操作或者发送下一个调用请求。
阻塞:IO操作需要彻底完成后才返回到用户空间,调用结果返回之前,调用者被挂起,无法进行其他操作,调用者只有在得到结果之后才会返回,该线程在此过程中不能进行其他处理。
非阻塞:IO操作被调用后立即返回给用户一个状态,无需等到IO操作彻底完成,最终的调用结果返回之前,调用者不会被挂起,可以去做别的事情。
1.2、同步阻塞型IO
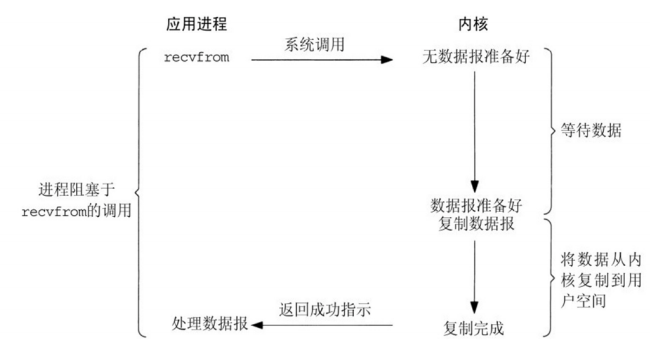
阻塞IO模型是最简单的IO模型,用户线程在内核进行IO操作师被阻塞,用户线程通过系统调用read发起IO操作,由用户空间转到内核空间。内核等到数据包到达后,然后将接收的数据cp到用户空间,完成read操作,用户空间需要等待read将数据读取到buffer后,才继续处理接受的数据。整个IO请求的过程中,用户线程是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够。
优点:程序简单,在阻塞等待数据期间进程/线程挂起,基本不会占用CPU资源
缺点:每个连接需要独立的进程/线程单独处理,这样虽然可以有效的利用CPU资源,但是代价就是多进程的大量内存开销。
同步阻塞:程序向内核发送IO请求后一直等待内核响应,如果内核处理请求的IO操作不能立即返回,则进程将一直等待并不再接收新的请求,并由进程轮询查看IO是否完成,完成后进程将IO结果返回给Client,在IO没有返回期间进程不能接收其他用户的请求,而且只有进程自己去查看IO是否完成。
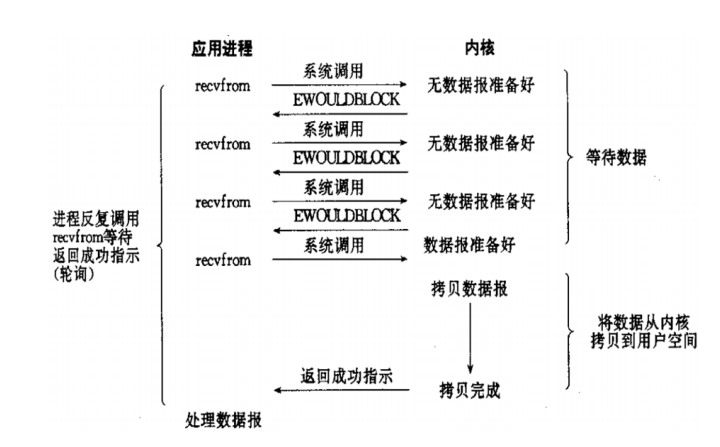
1.3、
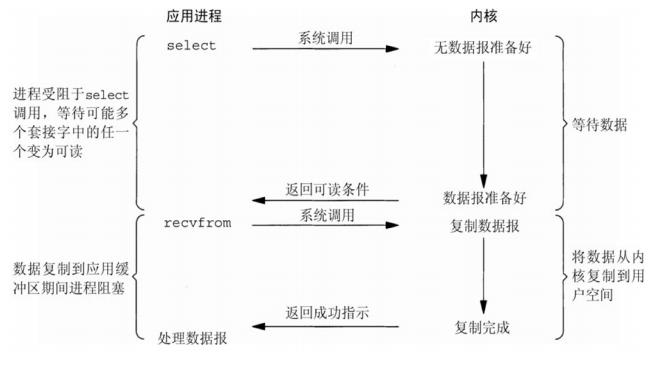
1.4、多路IO复用
select模型:select模型通过一个select()系统调用来监视包含多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行读写操作。select的一个缺点是单个进程能够监听的文件描述符的数量存在最大限制(Linux上一般为1024),所以加入使用select的服务器最多只能同时监听1024(64位操作系统默认为2048)个连接。由于nginx的prefork模型其底层所使用的的是select模型,因此nginx的prefork的最大连接数为1024。其次,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长;由于网络响应时间的延迟使得大量的TCP连接处于非活跃状态,但调用select()会对所有socket进行一次线性扫描,所以在一定程度上浪费CPU时间。