
sql语句执行步骤详解
一、准备工作
先来一段伪代码,首先你能看懂么?
SELECT DISTINCT <select_list>
FROM <left_table>
<join_type> JOIN <right_table>
ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
ORDER BY <order_by_condition>
LIMIT <limit_number>
继续做以下的前期准备工作:
新建一个测试数据库TestDB;
create database TestDB;
创建测试表table1和table2;
CREATE TABLE table1
(
customer_id VARCHAR(10) NOT NULL,
city VARCHAR(10) NOT NULL,
PRIMARY KEY(customer_id)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
CREATE TABLE table2
(
order_id INT NOT NULL auto_increment,
customer_id VARCHAR(10),
PRIMARY KEY(order_id)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
插入测试数据;
INSERT INTO table1(customer_id,city) VALUES('163','hangzhou');
INSERT INTO table1(customer_id,city) VALUES('9you','shanghai');
INSERT INTO table1(customer_id,city) VALUES('tx','hangzhou');
INSERT INTO table1(customer_id,city) VALUES('baidu','hangzhou');
INSERT INTO table2(customer_id) VALUES('163');
INSERT INTO table2(customer_id) VALUES('163');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('tx');
INSERT INTO table2(customer_id) VALUES(NULL);
准备工作做完以后,table1和table2看起来应该像下面这样:
mysql> select * from table1;
+-------------+----------+
| customer_id | city |
+-------------+----------+
| 163 | hangzhou |
| 9you | shanghai |
| baidu | hangzhou |
| tx | hangzhou |
+-------------+----------+
4 rows in set (0.00 sec)
mysql> select * from table2;
+----------+-------------+
| order_id | customer_id |
+----------+-------------+
| 1 | 163 |
| 2 | 163 |
| 3 | 9you |
| 4 | 9you |
| 5 | 9you |
| 6 | tx |
| 7 | NULL |
+----------+-------------+
7 rows in set (0.00 sec)
准备SQL逻辑查询测试语句
SELECT a.customer_id, COUNT(b.order_id) as total_orders
FROM table1 AS a
LEFT JOIN table2 AS b
ON a.customer_id = b.customer_id
WHERE a.city = 'hangzhou'
GROUP BY a.customer_id
HAVING count(b.order_id) < 2
ORDER BY total_orders DESC;
使用上述SQL查询语句来获得来自杭州,并且订单数少于2的客户。
二、SQL逻辑查询语句执行顺序
还记得上面给出的那一长串的SQL逻辑查询规则么?那么,到底哪个先执行,哪个后执行呢?现在,我先给出一个查询语句的执行顺序:
(7) SELECT /* 处理SELECT列表,产生 VT7 */
(8) DISTINCT <select_list> /* 将重复的行从 VT7 中删除,产品 VT8 */
(1) FROM <left_table> /* 对FROM子句中的表执行笛卡尔积(交叉联接),生成虚拟表 VT1。 */
(3) <join_type> JOIN <right_table> /* 如果指定了OUTER JOIN(相对于CROSS JOIN或INNER JOIN),
保留表中未找到匹配的行将作为外部行添加到 VT2,生成 VT3。
如果FROM子句包含两个以上的表,
则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,
直到处理完所有的表位置。 */
(2) ON <join_condition>/* 对 VT1 应用 ON 筛选器,只有那些使为真才被插入到 VT2。 */
(4) WHERE <where_condition>/* 对 VT3 应用 WHERE 筛选器,只有使为true的行才插入VT4。 */
(5) GROUP BY <group_by_list> /* 按 GROUP BY子句中的列列表对 VT4 中的行进行分组,生成 VT5 */
(6) HAVING <having_condition> /* 对 VT5 应用 HAVING 筛选器,只有使为true的组插入到 VT6 */
(9) ORDER BY <order_by_condition> /* 将 VT8 中的行按 ORDER BY子句中的列列表顺序,生成一个游标(VC10),
生成表TV11,并返回给调用者。 */
(10)LIMIT <limit_number>
Oracle SQL语句执行顺序
(8)SELECT (9)DISTINCT (11)<Top Num> <select list>
(1)FROM [left_table]
(3)<join_type> JOIN <right_table>
(2)ON <join_condition>
(4)WHERE <where_condition>
(5)GROUP BY <group_by_list>
(6)WITH <CUBE | RollUP>
(7)HAVING <having_condition>
(10)ORDER BY <order_by_list>
以上每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只有最后一步生成的表才会会给调用者。如果没有在查询中指定某一个子句,将跳过相应的步骤。
逻辑查询处理阶段简介:
-
FROM:对 FROM 子句中的前两个表执行笛卡尔积(Cartesian product)(交叉联接),生成虚拟表VT1 -
ON:对VT1应用ON筛选器。只有那些使<join_condition>为真的行才被插入VT2。 -
OUTER(JOIN):如 果指定了OUTER JOIN(相对于CROSS JOIN或(INNER JOIN),保留表(preserved table:左外部联接把左表标记为保留表,右外部联接把右表标记为保留表,完全外部联接把两个表都标记为保留表)中未找到匹配的行将作为外部行添加到 VT2,生成VT3.如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,直到处理完所有的表为止。 -
WHERE:对VT3应用WHERE筛选器。只有使<where_condition>为true的行才被插入VT4. -
GROUP BY:按GROUP BY子句中的列列表对VT4中的行分组,生成VT5. -
CUBE|ROLLUP:把超组(Suppergroups)插入VT5,生成VT6. -
HAVING:对VT6应用HAVING筛选器。只有使<having_condition>为 true 的组才会被插入VT7. -
SELECT:处理SELECT列表,产生VT8. -
DISTINCT:将重复的行从VT8中移除,产生VT9. -
ORDER BY:将VT9中的行按RDER BY子句中的列列表排序,生成游标(VC10). -
TOP:从VC10的开始处选择指定数量或比例的行,生成表VT11,并返回调用者。
注:步骤10,按ORDER BY子句中的列列表排序上步返回的行,返回游标VC10.这一步是第一步也是唯一 一步可以使用SELECT列表中的列别名的步骤。这一步不同于其它步骤的 是,它不返回有效的表,而是返回一个游标。SQL是基于集合理论的。集合不会预先对它的行排序,它只是成员的逻辑集合,成员的顺序无关紧要。对表进行排序 的查询可以返回一个对象,包含按特定物理顺序组织的行。ANSI把这种对象称为游标。理解这一步是正确理解SQL的基础。
因为这一步不返回表(而是返回游标),使用了ORDER BY子句的查询不能用作表表达式。表表达式包括:视图、内联表值函数、子查询、派生表和共用表达式。它的结果必须返回给期望得到物理记录的客户端应用程序。例如,下面的派生表查询无效,并产生一个错误:
select *
from(select orderid,customerid from orders order by orderid) as d
下面的视图也会产生错误
create view my_view
as
select *
from orders
order by orderid
在 SQL 中,表表达式中不允许使用带有 ORDER BY 子句的查询,而在T—SQL中却有一个例外(应用TOP选项)。
所以要记住,不要为表中的行假设任何特定的顺序。换句话说,除非你确定要有序行,否则不要指定 ORDER BY 子句。排序是需要成本的,SQL Server需要执行有序索引扫描或使用排序运行符。
以上就是一条sql的执行过程,同时我们在书写查询sql的时候应当遵守以下顺序。
SELECT XXX FROM XXX WHERE XXX GROUP BY XXX HAVING XXX ORDER BY XXX LIMIT XXX;
上面标出了各条查询规则的执行先后顺序,那么各条查询语句是如何执行的呢?
(1)执行FROM语句
在这些 SQL 语句的执行过程中,都会产生一个虚拟表,用来保存 SQL 语句的执行结果(这是重点),我现在就来跟踪这个虚拟表的变化,得到最终的查询结果的过程,来分析整个 SQL 逻辑查询的执行顺序和过程。
第一步,执行FROM语句。我们首先需要知道最开始从哪个表开始的,这就是FROM告诉我们的。现在有了 <left_table> 和 <right_table> 两个表,我们到底从哪个表开始,还是从两个表进行某种联系以后再开始呢?它们之间如何产生联系呢?——笛卡尔积
关于什么是笛卡尔积,请自行 Google 补脑。经过 FROM 语句对两个表执行笛卡尔积,会得到一个虚拟表,暂且叫VT1(vitual table 1),内容如下:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 9you | shanghai | 1 | 163 |
| baidu | hangzhou | 1 | 163 |
| tx | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 2 | 163 |
| baidu | hangzhou | 2 | 163 |
| tx | hangzhou | 2 | 163 |
| 163 | hangzhou | 3 | 9you |
| 9you | shanghai | 3 | 9you |
| baidu | hangzhou | 3 | 9you |
| tx | hangzhou | 3 | 9you |
| 163 | hangzhou | 4 | 9you |
| 9you | shanghai | 4 | 9you |
| baidu | hangzhou | 4 | 9you |
| tx | hangzhou | 4 | 9you |
| 163 | hangzhou | 5 | 9you |
| 9you | shanghai | 5 | 9you |
| baidu | hangzhou | 5 | 9you |
| tx | hangzhou | 5 | 9you |
| 163 | hangzhou | 6 | tx |
| 9you | shanghai | 6 | tx |
| baidu | hangzhou | 6 | tx |
| tx | hangzhou | 6 | tx |
| 163 | hangzhou | 7 | NULL |
| 9you | shanghai | 7 | NULL |
| baidu | hangzhou | 7 | NULL |
| tx | hangzhou | 7 | NULL |
+-------------+----------+----------+-------------+
总共有28(table1的记录条数 * table2的记录条数)条记录。这就是VT1的结果,接下来的操作就在VT1的基础上进行。
(2)执行ON过滤
执行完笛卡尔积以后,接着就进行ON a.customer_id = b.customer_id条件过滤,根据ON中指定的条件,去掉那些不符合条件的数据,得到VT2表,内容如下:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
+-------------+----------+----------+-------------+
VT2就是经过ON条件筛选以后得到的有用数据,而接下来的操作将在VT2的基础上继续进行。
(3) JOIN 添加外部行
这一步只有在连接类型为OUTER JOIN时才发生,如LEFT OUTER JOIN、RIGHT OUTER JOIN和FULL OUTER JOIN。在大多数的时候,我们都是会省略掉OUTER关键字的,但OUTER表示的就是外部行的概念。
下面从网上找到一张很形象的关于‘SQL JOINS'的解释图
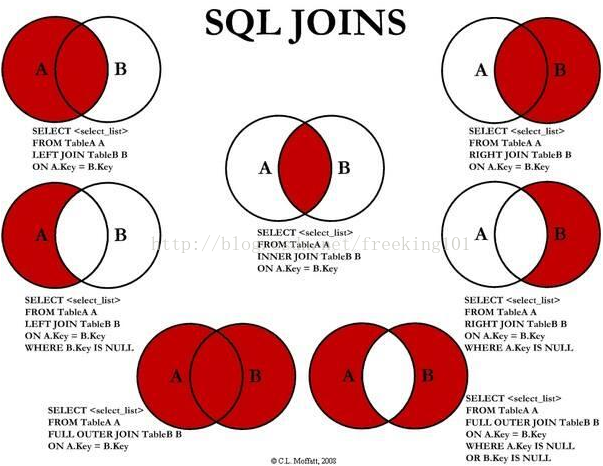
LEFT OUTER JOIN把左表记为保留表,得到的结果为:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
+-------------+----------+----------+-------------+
RIGHT OUTER JOIN把右表记为保留表,得到的结果为:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| NULL | NULL | 7 | NULL |
+-------------+----------+----------+-------------+
FULL OUTER JOIN把左右表都作为保留表,得到的结果为:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
| NULL | NULL | 7 | NULL |
+-------------+----------+----------+-------------+
添加外部行的工作就是在VT2表的基础上添加保留表中被过滤条件过滤掉的数据,非保留表中的数据被赋予NULL值,最后生成虚拟表VT3。
由于我在准备的测试SQL查询逻辑语句中使用的是LEFT JOIN,过滤掉了以下这条数据:
| baidu | hangzhou | NULL | NULL |
现在就把这条数据添加到VT2表中,得到的VT3表如下:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
+-------------+----------+----------+-------------+
接下来的操作都会在该VT3表上进行。
(4)执行WHERE过滤
对添加外部行得到的VT3进行WHERE过滤,只有符合<where_condition>的记录才会输出到虚拟表VT4中。当我们执行WHERE a.city = 'hangzhou'的时候,就会得到以下内容,并存在虚拟表VT4中:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
+-------------+----------+----------+-------------+
但是在使用WHERE子句时,需要注意以下两点:
由于数据还没有分组,因此现在还不能在WHERE过滤器中使用where_condition=MIN(col)这类对分组统计的过滤;
由于还没有进行列的选取操作,因此在SELECT中使用列的别名也是不被允许的,
如:SELECT city as c FROM t WHERE c='shanghai';是不允许出现的。
(5) 执行 GROUP BY 分组
GROU BY子句主要是对使用WHERE子句得到的虚拟表进行分组操作。我们执行测试语句中的GROUP BY a.customer_id,就会得到以下内容:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| baidu | hangzhou | NULL | NULL |
| tx | hangzhou | 6 | tx |
+-------------+----------+----------+-------------+
得到的内容会存入虚拟表VT5中,此时,我们就得到了一个VT5虚拟表,接下来的操作都会在该表上完成。
(6) 执行HAVING过滤
HAVING子句主要和GROUP BY子句配合使用,对分组得到的VT5虚拟表进行条件过滤。当我执行测试语句中的HAVING count(b.order_id) < 2时,将得到以下内容:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| baidu | hangzhou | NULL | NULL |
| tx | hangzhou | 6 | tx |
+-------------+----------+----------+-------------+
这就是虚拟表VT6。
(7) SELECT列表
现在才会执行到SELECT子句,不要以为SELECT子句被写在第一行,就是第一个被执行的。
我们执行测试语句中的SELECT a.customer_id, COUNT(b.order_id) as total_orders,从虚拟表VT6中选择出我们需要的内容。我们将得到以下内容:
+-------------+--------------+
| customer_id | total_orders |
+-------------+--------------+
| baidu | 0 |
| tx | 1 |
+-------------+--------------+
不,还没有完,这只是虚拟表VT7。
(8)执行 DISTINCT 子句
如果在查询中指定了DISTINCT子句,则会创建一张内存临时表(如果内存放不下,就需要存放在硬盘了)。这张临时表的表结构和上一步产生的虚拟表 VT7 是一样的,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以此来除重复数据。
由于我的测试SQL语句中并没有使用 DISTINCT,所以,在该查询中,这一步不会生成一个虚拟表。
(9)执行 ORDER BY 子句
对虚拟表中的内容按照指定的列进行排序,然后返回一个新的虚拟表,我们执行测试SQL语句中的ORDER BY total_orders DESC,就会得到以下内容:
+-------------+--------------+
| customer_id | total_orders |
+-------------+--------------+
| tx | 1 |
| baidu | 0 |
+-------------+--------------+
可以看到这是对 total_orders 列进行降序排列的。上述结果会存储在VT8中。
(10) 执行 LIMIT 子句
LIMIT子句从上一步得到的VT8虚拟表中选出从指定位置开始的指定行数据。对于没有应用ORDER BY的LIMIT子句,得到的结果同样是无序的,所以,很多时候,我们都会看到LIMIT子句会和ORDER BY子句一起使用。
MySQL数据库的LIMIT支持如下形式的选择:
LIMIT n, m
表示从第n条记录开始选择m条记录。而很多开发人员喜欢使用该语句来解决分页问题。对于小数据,使用LIMIT子句没有任何问题,当数据量非常大的时候,使用LIMIT n, m是非常低效的。因为LIMIT的机制是每次都是从头开始扫描,如果需要从第60万行开始,读取3条数据,就需要先扫描定位到60万行,然后再进行读取,而扫描的过程是一个非常低效的过程。所以,对于大数据处理时,是非常有必要在应用层建立一定的缓存机制(貌似现在的大数据处理,都有缓存哦)。各位,请期待我的缓存方面的文章哦。
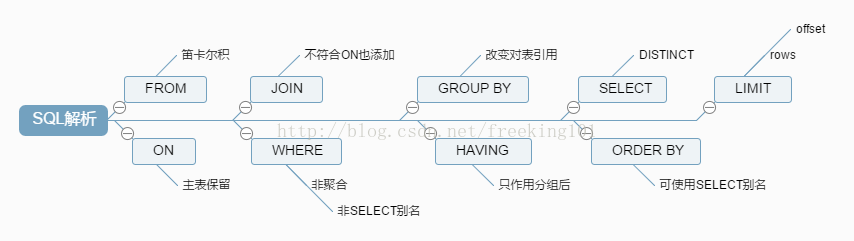
至此SQL的解析之旅就结束了,上图总结一下:
三、SQL书写习惯
了解了 SQL 执行顺序,那么我们就接下来进一步养成日常 sql好习惯,也就是在实现功能同时有考虑性能的思想,数据库是能进行集合运算的工具,我们应该尽量的利用这个工具,所谓集合运算实际就是批量运算,就是尽量减少在客户端进行大数据量的循环操作,而用SQL语句或者存储过程代替。
1.只返回需要的数据
返回数据到客户端至少需要数据库提取数据、网络传输数据、客户端接收数据以及客户端处理数据等环节。
如果返回不需要的数据,就会增加服务器、网络和客户端的无效劳动,其害处是显而易见的,避免这类事件需要注意:
(1)横向来看:
不要写SELECT * 的语句,而是选择你需要的字段。
当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上。这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
如有表table1(ID,col1)和table2 (ID,col2)
Select A.ID, A.col1, B.col2
-- Select A.ID, col1, col2 –不要这么写,不利于将来程序扩展
from table1 A inner join table2 B on A.ID=B.ID Where …
(2) 纵向来看
合理写 WHERE 子句,不要写没有 WHERE 的 SQL 语句。SELECT TOP N * --没有WHERE条件的用此替代
尽量少做重复的工作。控制同一语句的多次执行,特别是一些基础数据的多次执行是很多程序员很少注意的。
减少多次的数据转换,也许需要数据转换是设计的问题,但是减少次数是程序员可以做到的。
杜绝不必要的子查询和连接表,子查询在执行计划一般解释成外连接,多余的连接表带来额外的开销。
合并对同一表同一条件的多次 UPDATE,比如:
UPDATE EMPLOYEE SET FNAME='HAIWER'
WHERE EMP_ID=' VPA30890F' UPDATE EMPLOYEE SET LNAME='YANG'
WHERE EMP_ID=' VPA30890F'
-- 这两个语句应该合并成以下一个语句
UPDATE EMPLOYEE SET FNAME='HAIWER',LNAME='YANG' WHERE EMP_ID=' VPA30890F'
UPDATE操作不要拆成DELETE操作+INSERT操作的形式,虽然功能相同,但是性能差别是很大的。
2.注意 临时表 和 表变量 的用法
在复杂系统中,临时表和表变量很难避免,关于临时表和表变量的用法,需要注意:
如果语句很复杂,连接太多,可以考虑用临时表和表变量分步完成。
如果需要多次用到一个大表的同一部分数据,考虑用临时表和表变量暂存这部分数据。
如果需要综合多个表的数据,形成一个结果,可以考虑用临时表和表变量分步汇总这多个表的数据。
其他情况下,应该控制临时表和表变量的使用。
关于临时表和表变量的选择,很多说法是表变量在内存,速度快,应该首选表变量,
但是在实际使用中发现,主要考虑需要放在临时表的数据量,在数据量较多的情况下,临时表的速度反而更快。执行时间段与预计执行时间(多长)。
关于临时表产生使用SELECT INTO 和 CREATE TABLE + INSERT INTO 的选择。
一般情况下,SELECT INTO会比CREATE TABLE + INSERT INTO的方法快很多,
但是SELECT INTO会锁定TEMPDB的系统表SYSOBJECTS、SYSINDEXES、SYSCOLUMNS,
在多用户并发环境下,容易阻塞其他进程,
所以我的建议是,在并发系统中,尽量使用CREATE TABLE + INSERT INTO,而大数据量的单个语句使用中,使用SELECT INTO。
3.子查询的用法
子查询是一个 SELECT 查询,它嵌套在 SELECT、INSERT、UPDATE、DELETE 语句或其它子查询中。
任何允许使用表达式的地方都可以使用子查询,子查询可以使我们的编程灵活多样,可以用来实现一些特殊的功能。
但是在性能上,往往一个不合适的子查询用法会形成一个性能瓶颈。
如果子查询的条件中使用了其外层的表的字段,这种子查询就叫作相关子查询。
相关子查询可以用IN、NOT IN、EXISTS、NOT EXISTS引入。
关于相关子查询,应该注意:
1. NOT IN、NOT EXISTS的相关子查询可以改用LEFT JOIN代替写法。
比如:
SELECT PUB_NAME FROM PUBLISHERS WHERE PUB_ID NOT IN (SELECT PUB_ID FROM TITLES WHERE TYPE = 'BUSINESS')
可以改写成:
SELECT A.PUB_NAME FROM PUBLISHERS A LEFT JOIN TITLES B ON B.TYPE = 'BUSINESS' AND A.PUB_ID=B. PUB_ID WHERE B.PUB_ID IS NULL
又比如:
SELECT TITLE FROM TITLES
WHERE NOT EXISTS
(SELECT TITLE_ID FROM SALES
WHERE TITLE_ID = TITLES.TITLE_ID)
可以改写成:
SELECT TITLE
FROM TITLES LEFT JOIN SALES
ON SALES.TITLE_ID = TITLES.TITLE_ID
WHERE SALES.TITLE_ID IS NULL
2. 如果保证子查询没有重复 ,IN、EXISTS的相关子查询可以用INNER JOIN 代替。
比如:
SELECT PUB_NAME
FROM PUBLISHERS
WHERE PUB_ID IN
(SELECT PUB_ID
FROM TITLES
WHERE TYPE = 'BUSINESS')
可以改写成:
SELECT A.PUB_NAME --SELECT DISTINCT A.PUB_NAME
FROM PUBLISHERS A INNER JOIN TITLES B
ON B.TYPE = 'BUSINESS' AND
A.PUB_ID=B. PUB_ID
3. IN的相关子查询用EXISTS代替
比如
SELECT PUB_NAME FROM PUBLISHERS
WHERE PUB_ID IN
(SELECT PUB_ID FROM TITLES WHERE TYPE = 'BUSINESS')
可以用下面语句代替:
SELECT PUB_NAME FROM PUBLISHERS WHERE EXISTS
(SELECT 1 FROM TITLES WHERE TYPE = 'BUSINESS' AND
PUB_ID= PUBLISHERS.PUB_ID)
4. 不要用COUNT(*)的子查询判断是否存在记录,最好用LEFT JOIN或者EXISTS
比如有人写这样的语句:
SELECT JOB_DESC FROM JOBS
WHERE (SELECT COUNT(*) FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)=0
应该写成:
SELECT JOBS.JOB_DESC FROM JOBS LEFT JOIN EMPLOYEE
ON EMPLOYEE.JOB_ID=JOBS.JOB_ID
WHERE EMPLOYEE.EMP_ID IS NULL
还有
SELECT JOB_DESC FROM JOBS
WHERE (SELECT COUNT(*) FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)<>0
应该写成:
SELECT JOB_DESC FROM JOBS
WHERE EXISTS (SELECT 1 FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)
4.尽量使用索引
建立索引后,并不是每个查询都会使用索引,在使用索引的情况下,索引的使用效率也会有很大的差别。只要我们在查询语句中没有强制指定索引,索引的选择和使用方法是SQLSERVER的优化器自动作的选择,而它选择的根据是查询语句的条件以及相关表的统计信息,这就要求我们在写SQL语句的时候尽量使得优化器可以使用索引。为了使得优化器能高效使用索引,写语句的时候应该注意:
不要对索引字段进行运算,而要想办法做变换
SELECT ID FROM T WHERE NUM/2=100
应改为:
SELECT ID FROM T WHERE NUM=100*2
SELECT ID FROM T WHERE NUM/2=NUM1
如果NUM有索引应改为:
SELECT ID FROM T WHERE NUM=NUM1*2
如果NUM1有索引则不应该改。
发现过这样的语句:
SELECT 年,月,金额 FROM 结余表 WHERE 100*年+月=2010*100+10
应该改为:
SELECT 年,月,金额 FROM 结余表 WHERE 年=2010 AND月=10
不要对索引字段进行格式转换
日期字段的例子:
WHERE CONVERT(VARCHAR(10), 日期字段,120)='2010-07-15'
应该改为
WHERE日期字段〉='2010-07-15' AND 日期字段<'2010-07-16'
ISNULL转换的例子:
WHERE ISNULL(字段,'')<>''应改为:WHERE字段<>''
WHERE ISNULL(字段,'')=''不应修改
WHERE ISNULL(字段,'F') ='T'应改为: WHERE字段='T'
WHERE ISNULL(字段,'F')<>'T'不应修改
不要对索引字段使用函数
WHERE LEFT(NAME, 3)='ABC' 或者WHERE SUBSTRING(NAME,1, 3)='ABC'
应改为: WHERE NAME LIKE 'ABC%'
日期查询的例子:
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
应改为:WHERE 日期>='2010-06-30' AND 日期 <'2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')>0
应改为:WHERE 日期 <'2010-06-30'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')>=0
应改为:WHERE 日期 <'2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')<0
应改为:WHERE 日期>='2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')<=0
应改为:WHERE 日期>='2010-06-30'
不要对索引字段进行多字段连接
比如:
WHERE FAME+ '. '+LNAME='HAIWEI.YANG'
应改为:
WHERE FNAME='HAIWEI' AND LNAME='YANG'
5.多表连接的连接条件
多表连接的连接条件对索引的选择有着重要的意义,所以我们在写连接条件的时候需要特别注意。
多表连接的时候,连接条件必须写全,宁可重复,不要缺漏。
连接条件尽量使用聚集索引
注意ON、WHERE和HAVING部分条件的区别
ON是最先执行,WHERE次之,HAVING最后。因为ON是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,
WHERE也应该比 HAVING快点的,因为它过滤数据后才进行SUM,在两个表联接时才用ON的,所以在一个表的时候,就剩下WHERE跟HAVING比较了
6.考虑联接优先顺序
INNER JOIN LEFT JOIN (注:RIGHT JOIN 用 LEFT JOIN 替代) CROSS JOIN
其它注意和了解的地方有
在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数
注意UNION和UNION ALL的区别。--允许重复数据用UNION ALL好
注意使用DISTINCT,在没有必要时不要用
7.truncate table与 delete 区别
相同点:
1.truncate和不带where子句的delete、以及drop都会删除表内的数据。
2.drop、truncate都是DDL语句(数据定义语言),执行后会自动提交。
不同点:
1. truncate 和 delete 只删除数据不删除表的结构(定义)
drop 语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index);依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。
2. delete 语句是数据库操作语言(dml),这个操作会放到 rollback segement 中,事务提交之后才生效;如果有相应的 trigger,执行的时候将被触发。
truncate、drop 是数据库定义语言(ddl),操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。
3.delete 语句不影响表所占用的 extent,高水线(high watermark)保持原位置不动
drop 语句将表所占用的空间全部释放。
truncate 语句缺省情况下见空间释放到 minextents个 extent,除非使用reuse storage;truncate 会将高水线复位(回到最开始)。
4.速度,一般来说: drop> truncate > delete
5.安全性:小心使用 drop 和 truncate,尤其没有备份的时候.否则哭都来不及
使用上,想删除部分数据行用 delete,注意带上where子句. 回滚段要足够大.
想删除表,当然用 drop
想保留表而将所有数据删除,如果和事务无关,用truncate即可。如果和事务有关,或者想触发trigger,还是用delete。
如果是整理表内部的碎片,可以用truncate跟上reuse stroage,再重新导入/插入数据。
6.delete是DML语句,不会自动提交。drop/truncate都是DDL语句,执行后会自动提交。
7、TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE
语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。
DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。
TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
8、TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 DROP TABLE 语句。
9、对于由 FOREIGN KEY 约束引用的表,不能使用 TRUNCATE TABLE,而应使用不带 WHERE 子句的 DELETE 语句。由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
10、TRUNCATE TABLE 不能用于参与了索引视图的表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号