索引的创建与设计原则
1. 索引的声明与使用
1.1 索引的分类
1.2 创建索引
1. 创建表的时候创建索引
CREATE TABLE dept ( dept_id INT PRIMARY KEY AUTO_INCREMENT, dept_name VARCHAR ( 20 ) ); CREATE TABLE emp ( emp_id INT PRIMARY KEY AUTO_INCREMENT, emp_name VARCHAR ( 20 ) UNIQUE, dept_id INT, CONSTRAINT emp_dept_id_fk FOREIGN KEY ( dept_id ) REFERENCES dept ( dept_id ) );
CREATE TABLE table_name [ col_name data_type ] [ UNIQUE | FULLTEXT | SPATIAL ] [ INDEX | KEY ] [ index_name ] ( col_name [ length ] ) [ ASC | DESC]
- UNIQUE 、 FULLTEXT 和 SPATIAL 为可选参数,分别表示唯一索引、全文索引和空间索引;
- INDEX 与 KEY 为同义词,两者的作用相同,用来指定创建索引;
- index_name 指定索引的名称,为可选参数,如果不指定,那么MySQL默认col_name为索引名;
- col_name 为需要创建索引的字段列,该列必须从数据表中定义的多个列中选择;
- length 为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度;
- ASC 或 DESC 指定升序或者降序的索引值存储。
1. 创建普通索引
CREATE TABLE book ( book_id INT, book_name VARCHAR ( 100 ), AUTHORS VARCHAR ( 100 ), info VARCHAR ( 100 ), COMMENT VARCHAR ( 100 ), year_publication YEAR, INDEX ( year_publication ) );
2. 创建唯一索引
CREATE TABLE test1 ( id INT NOT NULL, NAME VARCHAR ( 30 ) NOT NULL, UNIQUE INDEX uk_idx_id ( id ) );
SHOW INDEX FROM test1 \G
3. 主键索引
- 随表一起建索引:
CREATE TABLE student ( id INT ( 10 ) UNSIGNED AUTO_INCREMENT, student_no VARCHAR ( 200 ), student_name VARCHAR ( 200 ), PRIMARY KEY ( id ) );
- 删除主键索引:
ALTER TABLE student drop PRIMARY KEY ;
- 修改主键索引:必须先删除掉(drop)原索引,再新建(add)索引
4. 创建单列索引
- 举例:
CREATE TABLE test2( id INT NOT NULL, name CHAR(50) NULL, INDEX single_idx_name(name(20)) );
SHOW INDEX FROM test2 \G
5. 创建组合索引
CREATE TABLE test3( id INT(11) NOT NULL, name CHAR(30) NOT NULL, age INT(11) NOT NULL, info VARCHAR(255), INDEX multi_idx(id,name,age) );
SHOW INDEX FROM test3 \G
6. 创建全文索引
CREATE TABLE test4 ( id INT NOT NULL, NAME CHAR ( 30 ) NOT NULL, age INT NOT NULL, info VARCHAR ( 255 ), FULLTEXT INDEX futxt_idx_info ( info ) ) ENGINE = MyISAM;
|
在MySQL5.7及之后版本中可以不指定最后的ENGINE了,因为在此版本中InnoDB支持全文索引。
|
CREATE TABLE articles ( id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY, title VARCHAR ( 200 ), body TEXT, FULLTEXT INDEX ( title, body ) ) ENGINE = INNODB;
举例3:
CREATE TABLE `papers` ( `id` INT ( 10 ) UNSIGNED NOT NULL AUTO_INCREMENT, `title` VARCHAR ( 200 ) DEFAULT NULL, `content` text, PRIMARY KEY ( `id` ), FULLTEXT KEY `title` ( `title`, `content` ) ) ENGINE = MyISAM DEFAULT CHARSET = utf8;
SELECT * FROM papers WHERE content LIKE ‘%查询字符串%’;
SELECT * FROM papers WHERE MATCH(title,content) AGAINST (‘查询字符串’);
|
注意点
1. 使用全文索引前,搞清楚版本支持情况;
2. 全文索引比 like + % 快 N 倍,但是可能存在精度问题;
3. 如果需要全文索引的是大量数据,建议先添加数据,再创建索引。
|
7. 创建空间索引
CREATE TABLE test5 (
geo GEOMETRY NOT NULL,
SPATIAL INDEX spa_idx_geo ( geo )
) ENGINE = MyISAM;
2. 在已经存在的表上创建索引
ALTER TABLE table_name ADD [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name[length],...) [ASC | DESC]
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name ON table_name (col_name[length],...) [ASC | DESC]
1.3 删除索引
ALTER TABLE table_name DROP INDEX index_name;
DROP INDEX index_name ON table_name;
|
提示 删除表中的列时,如果要删除的列为索引的组成部分,则该列也会从索引中删除。如果组成
索引的所有列都被删除,则整个索引将被删除。
|
2. MySQL8.0索引新特性
2.1 支持降序索引
CREATE TABLE ts1(a int,b int,index idx_a_b(a,b desc));
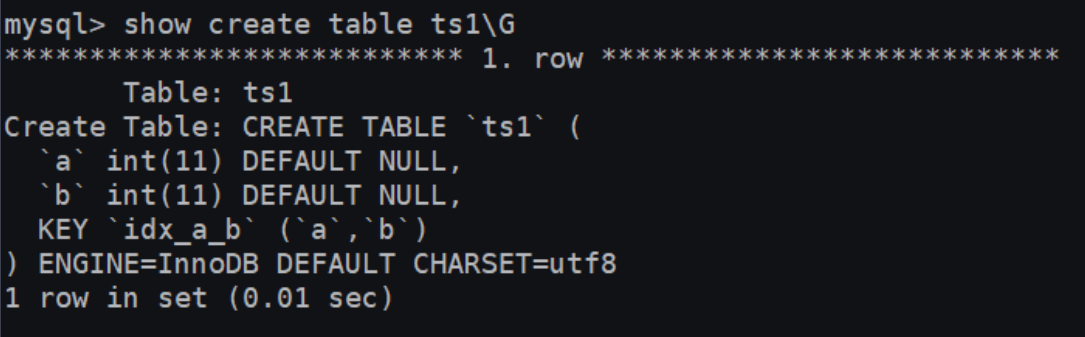
2.1 支持降序索引
举例:分别在MySQL 5.7版本和MySQL 8.0版本中创建数据表ts1,结果如下:
CREATE TABLE ts1(a int,b int,index idx_a_b(a,b desc));
在MySQL 5.7版本中查看数据表ts1的结构,结果如下:
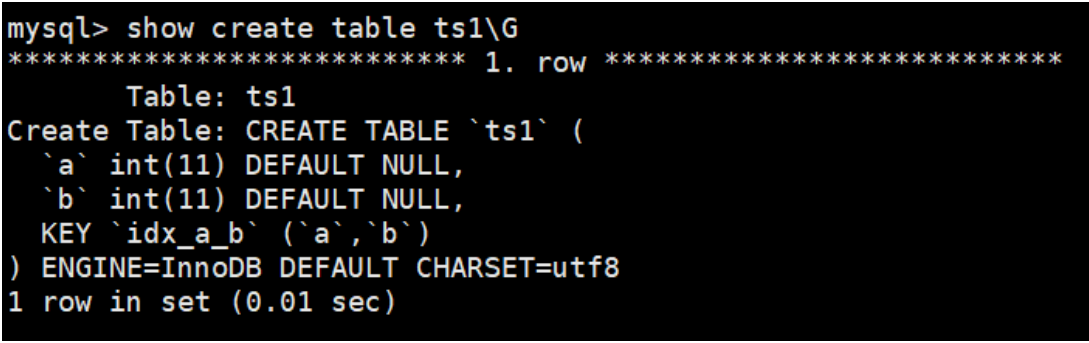
从结果可以看出,索引仍然是默认的升序。
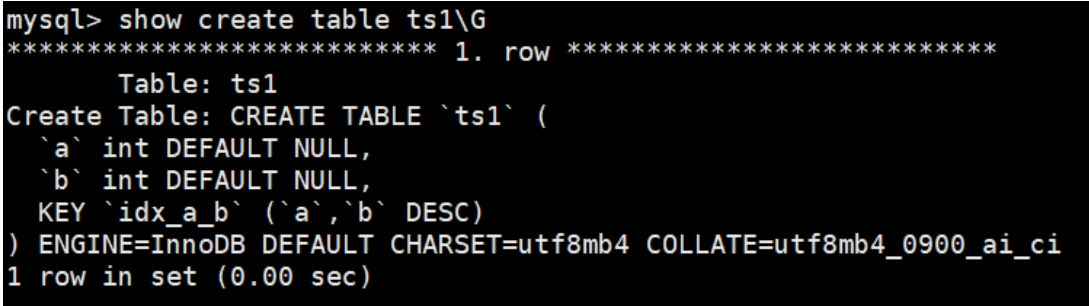
从结果可以看出,索引已经是降序了。下面继续测试降序索引在执行计划中的表现。
DELIMITER // CREATE PROCEDURE ts_insert ( ) BEGINDECLARE i INT DEFAULT 1; WHILE i < 800 DO INSERT INTO ts1 SELECT rand( ) * 80000, rand( ) * 80000; SET i = i + 1; END WHILE; COMMIT; END // DELIMITER; #调用 CALL ts_insert();
在MySQL 5.7版本中查看数据表ts1的执行计划,结果如下:
EXPLAIN SELECT * FROM ts1 ORDER BY a,b DESC LIMIT 5;
从结果可以看出,执行计划中扫描数为799,而且使用了Using filesort。
|
提示 Using filesort是MySQL中一种速度比较慢的外部排序,能避免是最好的。多数情况下,管理员
可以通过优化索引来尽量避免出现Using filesort,从而提高数据库执行速度。
|
在MySQL 8.0版本中查看数据表ts1的执行计划。从结果可以看出,执行计划中扫描数为5,而且没有使用Using filesort。
|
注意 降序索引只对查询中特定的排序顺序有效,如果使用不当,反而查询效率更低。例如,上述
查询排序条件改为order by a desc, b desc,MySQL 5.7的执行计划要明显好于MySQL 8.0。
|
将排序条件修改为order by a desc, b desc后,下面来对比不同版本中执行计划的效果。 在MySQL 5.7版本中查看数据表ts1的执行计划,结果如下:
EXPLAIN SELECT * FROM ts1 ORDER BY a DESC,b DESC LIMIT 5;
在MySQL 8.0版本中查看数据表ts1的执行计划。
2.2 隐藏索引
CREATE TABLE tablename ( propname1 type1 [ CONSTRAINT1 ], propname2 type2 [ CONSTRAINT2 ], …… propnamen typen, INDEX [ indexname ] ( propname1 [ ( length ) ] ) INVISIBLE );
上述语句比普通索引多了一个关键字INVISIBLE,用来标记索引为不可见索引。
2. 在已经存在的表上创建
可以为已经存在的表设置隐藏索引,其语法形式如下:
CREATE INDEX indexname ON tablename(propname[(length)]) INVISIBLE;
语法形式如下:
ALTER TABLE tablename
ADD INDEX indexname (propname [(length)]) INVISIBLE;
4. 切换索引可见状态 已存在的索引可通过如下语句切换可见状态:
ALTER TABLE tablename ALTER INDEX index_name INVISIBLE; #切换成隐藏索引
ALTER TABLE tablename ALTER INDEX index_name VISIBLE; #切换成非隐藏索引
如果将index_cname索引切换成可见状态,通过explain查看执行计划,发现优化器选择了index_cname索引。
注意 当索引被隐藏时,它的内容仍然是和正常索引一样实时更新的。如果一个索引需要长期被隐藏,那么可以将其删除,因为索引的存在会影响插入、更新和删除的性能。
通过设置隐藏索引的可见性可以查看索引对调优的帮助
5. 使隐藏索引对查询优化器可见
mysql> select @@optimizer_switch \G
在输出的结果信息中找到如下属性配置。
use_invisible_indexes=off
(2)使隐藏索引对查询优化器可见,需要在MySQL命令行执行如下命令:
mysql> set session optimizer_switch="use_invisible_indexes=on";
Query OK, 0 rows affected (0.00 sec)
SQL语句执行成功,再次查看查询优化器的开关设置。
mysql > SELECT @@optimizer_switch \ G *************************** 1.ROW *************************** @@optimizer_switch : index_merge = ON, index_merge_union = ON, index_merge_sort_union = ON, index_merge_ intersection = ON, engine_condition_pushdown = ON, index_condition_pushdown = ON, mrr = ON, mrr_co st_based = ON, block_nested_loop = ON, batched_key_access = off, materialization = ON, semijoin = ON, loosescan = ON, firstmatch = ON, duplicateweedout = ON, subquery_materialization_cost_based = ON, use_index_extensions = ON, condition_fanout_filter = ON, derived_merge = ON, use_invisible_ind exes = ON, skip_scan = ON, hash_join = ON 1 ROW IN SET ( 0.00 sec )
此时,在输出结果中可以看到如下属性配置。
use_invisible_indexes=on
explain select * from classes where cname = '高一2班';
mysql> set session optimizer_switch="use_invisible_indexes=off"; Query OK, 0 rows affected (0.00 sec)
mysql> select @@optimizer_switch \G
3. 索引的设计原则
3.1 数据准备
CREATE DATABASE atguigudb1; USE atguigudb1; #1.创建学生表和课程表 CREATE TABLE `student_info` ( `id` INT ( 11 ) NOT NULL AUTO_INCREMENT, `student_id` INT NOT NULL, `name` VARCHAR ( 20 ) DEFAULT NULL, `course_id` INT NOT NULL, `class_id` INT ( 11 ) DEFAULT NULL, `create_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY ( `id` ) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8; CREATE TABLE `course` ( `id` INT ( 11 ) NOT NULL AUTO_INCREMENT, `course_id` INT NOT NULL, `course_name` VARCHAR ( 40 ) DEFAULT NULL, PRIMARY KEY ( `id` ) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
#函数1:创建随机产生字符串函数 DELIMITER // CREATE FUNCTION rand_string ( n INT ) RETURNS VARCHAR ( 255 ) #该函数会返回一个字符串 BEGINDECLARE chars_str VARCHAR ( 100 ) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR ( 255 ) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str = CONCAT( return_str, SUBSTRING( chars_str, FLOOR( 1+ RAND( ) * 52 ), 1 ) ); SET i = i + 1; END WHILE; RETURN return_str; END // DELIMITER;
#函数2:创建随机数函数 DELIMITER // CREATE FUNCTION rand_num ( from_num INT, to_num INT ) RETURNS INT ( 11 ) BEGIN DECLARE i INT DEFAULT 0; SET i = FLOOR( from_num + RAND( ) * ( to_num - from_num + 1 ) ); RETURN i; END // DELIMITER;
This function has none of DETERMINISTIC......
- 查看mysql是否允许创建函数:
show variables like 'log_bin_trust_function_creators'
- 命令开启:允许创建函数设置:
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
- mysqld重启,上述参数又会消失。永久方法:
log_bin_trust_function_creators=1
第3步:创建插入模拟数据的存储过程
# 存储过程1:创建插入课程表存储过程 DELIMITER // CREATE PROCEDURE insert_course ( max_num INT ) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; #设置手动提交事务 REPEAT #循环 SET i = i + 1; #赋值 INSERT INTO course ( course_id, course_name ) VALUES ( rand_num ( 10000, 10100 ), rand_string ( 6 ) ); UNTIL i = max_num END REPEAT; COMMIT; #提交事务 END // DELIMITER; # 存储过程2:创建插入学生信息表存储过程 DELIMITER // CREATE PROCEDURE insert_stu ( max_num INT ) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; #设置手动提交事务 REPEAT #循环 SET i = i + 1; #赋值 INSERT INTO student_info ( course_id, class_id, student_id, NAME ) VALUES ( rand_num ( 10000, 10100 ), rand_num ( 10000, 10200 ), rand_num ( 1, 200000 ), rand_string ( 6 ) ); UNTIL i = max_num END REPEAT; COMMIT; #提交事务 END // DELIMITER ;
第4步:调用存储过程
CALL insert_course(100); CALL insert_stu(1000000);
3.2 哪些情况适合创建索引
1. 字段的数值有唯一性的限制
|
业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。(来源:Alibaba)
说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的。
|
2. 频繁作为 WHERE 查询条件的字段
3. 经常 GROUP BY 和 ORDER BY 的列
4. UPDATE、DELETE 的 WHERE 条件列
5.DISTINCT 字段需要创建索引
SELECT DISTINCT(student_id) FROM `student_info`;
SELECT DISTINCT(student_id) FROM `student_info`;
6. 多表 JOIN 连接操作时,创建索引注意事项
SELECT course_id, NAME, student_info.student_id, course_name FROM student_info JOIN course ON student_info.course_id = course.course_id WHERE NAME = '462eed7ac6e791292a79';
7. 使用列的类型小的创建索引
8. 使用字符串前缀创建索引
create table shop(address varchar(120) not null);
alter table shop add index(address(12));
select count(distinct address) / count(*) from shop;
count(distinct left(列名, 索引长度))/count(*)
SELECT count( DISTINCT LEFT ( address, 10 ) ) / count( * ) AS sub10,-- 截取前10个字符的选择度 count(distinct left(address,15)) / count(*) as sub11, -- 截取前15个字符的选择度 count(distinct left(address,20)) / count(*) as sub12, -- 截取前20个字符的选择度 count(distinct left(address,25)) / count(*) as sub13 -- 截取前25个字符的选择度 FROM shop;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号