一 clickhouse-简介
实时数据 ,事件,快

ClickHouse是一个完全的列式分布式数据库管理系统(DBMS),允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器,支持线性扩展,简单方便,高可靠性,容错。它在大数据领域没有走 Hadoop 生态,而是采用 Local attached storage 作为存储,这样整个 IO 可能就没有 Hadoop 那一套的局限。它的系统在生产环境中可以应用到比较大的规模,因为它的线性扩展能力和可靠性保障能够原生支持 shard + replication 这种解决方案。它还提供了一些 SQL 直接接口,有比较丰富的原生 client。
补充OLAP概念
OLAP基础概念篇 https://blog.csdn.net/qq_37933018/article/details/111535904
OLAP开源组件篇https://blog.csdn.net/qq_37933018/article/details/111537128
-
灵活的MPP架构,支持线性扩展,简单方便,高可靠性
-
多服务器分布式处理数据 ,完备的DBMS系统
-
底层数据列式存储,支持压缩,优化数据存储,优化索引数据 优化底层存储
-
容错跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可处理的数据级别已达到10亿级别
-
功能多:支持数据统计分析各种场景,支持类SQL查询,异地复制部署
海量数据存储,分布式运算,快速闪电的性能,几乎实时的数据分析 ,友好的SQL语法,出色的函数支持
2 缺点
-
不支持事务,不支持真正的删除/更新
-
不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下
-
不支持二级索引
-
不擅长多表join *** 大宽表
-
元数据管理需要人为干预 ***
-
尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作
3 应用场景
1.绝大多数请求都是用于读访问的, 要求实时返回结果 2.数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作 3.数据只是添加到数据库,没有必要修改 4.读取数据时,会从数据库中提取出大量的行,但只用到一小部分列 5.表很“宽”,即表中包含大量的列 6.查询频率相对较低(通常每台服务器每秒查询数百次或更少) 7.对于简单查询,允许大约50毫秒的延迟 8.列的值是比较小的数值和短字符串(例如,每个URL只有60个字节) 9.在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行) 10.不需要事务 11.数据一致性要求较低 [原子性 持久性 一致性 隔离性] 12.每次查询中只会查询一个大表。除了一个大表,其余都是小表 13.查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
4 核心概念
1) 数据分片
数据分片是将数据进行横向切分,这是一种在面对海量数据的场 景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现。 ClickHouse支持分片,而分片则依赖集群。每个集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量上限 取决于节点数量(1个分片只能对应1个服务节点)。ClickHouse并不像其他分布式系统那样,拥有高度自动化的分片功能。ClickHouse提供了本地表(Local Table)与分布式表(Distributed Table)的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。这种设计类似数据库的分库和分表,十分灵活。例如在业务系统上线的初期,数据体量并不高,此时数据表并不需要多个分片。所以使用单个节点的本地表(单个数据分片)即可满足业务需求,待到业务增长、数据量增大的时候,再通过新增数据分片的方式分流数据,并通过分布式表实现分布式查询。这就好比一辆手动挡赛车,它将所有的选择权都交到了使用者的手中!
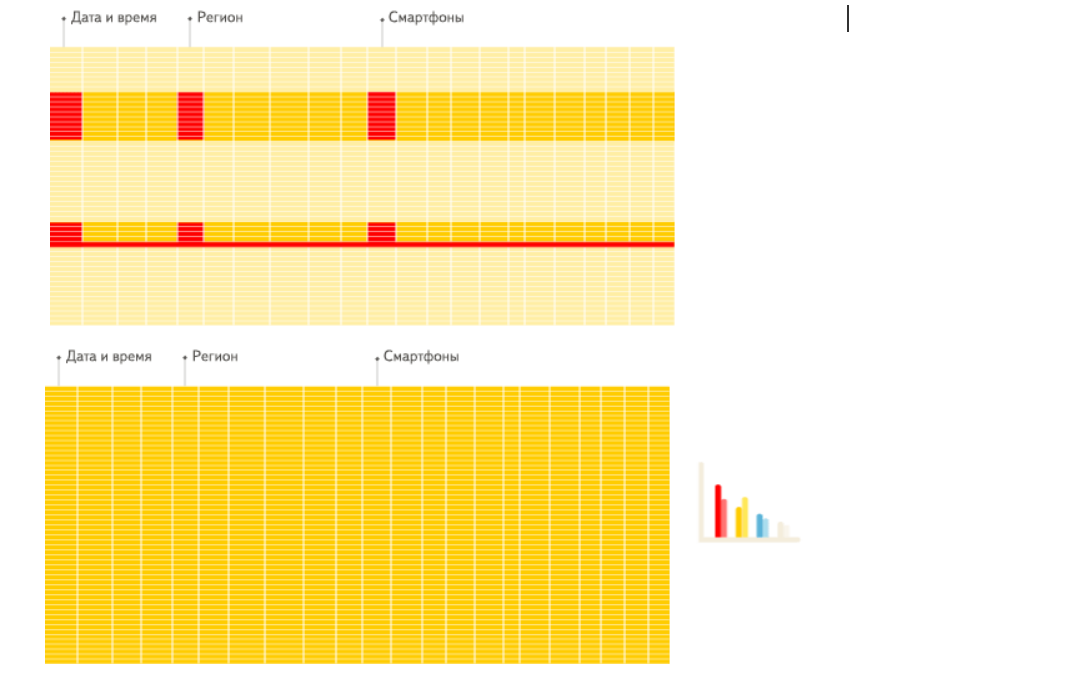
2) 列式存储
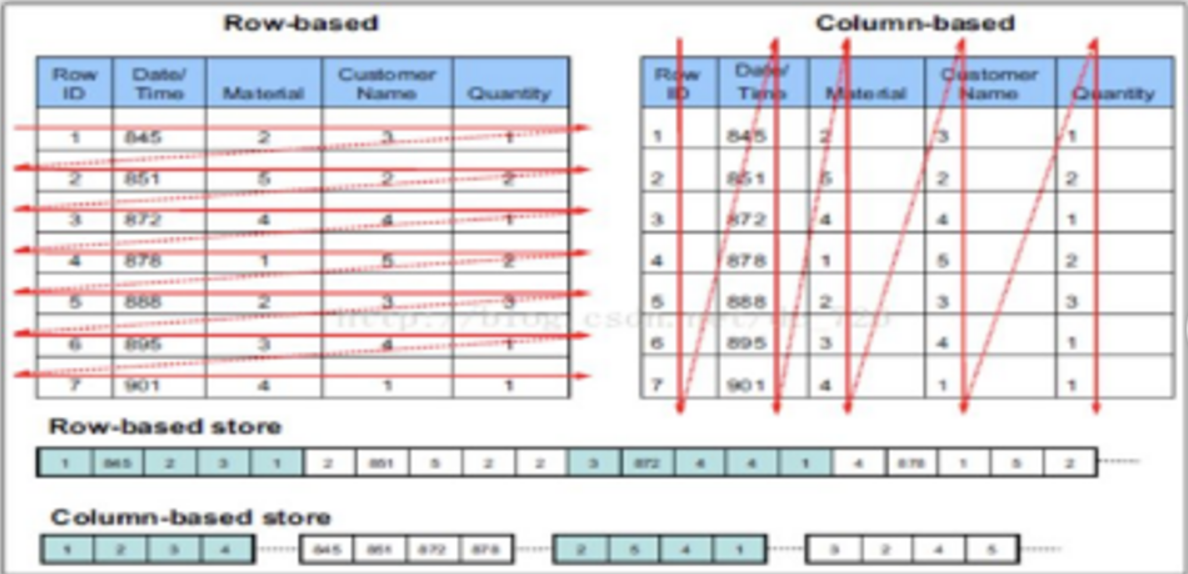
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
3) 向量化
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗: 1)对每一行数据都要调用相应的函数,函数调用开销占比高; 2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重; 3)按行处理,无法利用高效的SIMD指令; ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。 (SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个
4) 表
上层数据的视图展示概念 ,包括表的基本结构和数据
5) 分区
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。数据以分区的形式统一管理和维护一批数据!
6) 副本
数据存储副本,在集群模式下实现高可用 , 简单理解就是相同的数据备份,在CK中通过复制集,我们实现保障了数据可靠性外,也通过多副本的方式,增加了CK查询的并发能力。这里一般有2种方式:(1)基于ZooKeeper的表复制方式;(2)基于Cluster的复制方式。由于我们推荐的数据写入方式本地表写入,禁止分布式表写入,所以我们的复制表只考虑ZooKeeper的表复制方案。
7) 引擎
不同的引擎决定了表数据的存储特点,位置和表数据的操作行为:
-
决定表存储在哪里以及以何种方式存储
-
支持哪些查询以及如何支持
-
并发数据访问
-
索引的使用
-
是否可以执行多线程请求
-
数据复制参数
-
并发操作 insert into tb_x select * from tb_x ;
表引擎决定了数据在文件系统中的存储方式,常用的也是官方推荐的存储引擎是MergeTree系列,如果需要数据副本的话可以使用ReplicatedMergeTree系列,相当于MergeTree的副本版本。读取集群数据需要使用分布式表引擎Distribute。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号