Hive 5、Hive 的数据类型 和 DDL Data Definition Language)
官方帮助文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
-- 扩展数据类型 data_type : primitive_type | array_type | map_type | struct_type | union_type -- (Note: Available in Hive 0.7.0 and later) array_type : ARRAY < data_type > map_type : MAP < primitive_type, data_type > struct_type : STRUCT < col_name : data_type [COMMENT col_comment], ...> union_type : UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later) -- 基本数据类型 primitive_type : TINYINT | SMALLINT | INT | BIGINT | BOOLEAN | FLOAT | DOUBLE | STRING | BINARY -- (Note: Available in Hive 0.8.0 and later) | TIMESTAMP -- (Note: Available in Hive 0.8.0 and later) | DECIMAL -- (Note: Available in Hive 0.11.0 and later) | DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later) | DATE -- (Note: Available in Hive 0.12.0 and later) | VARCHAR -- (Note: Available in Hive 0.12.0 and later) | CHAR -- (Note: Available in Hive 0.13.0 and later)
Hive DDL
Hive完整的DDL
Hive DDL的语方法为类SQL语法,所以标准的SQL语法大多数在Hive中都可用;
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
Hive建表
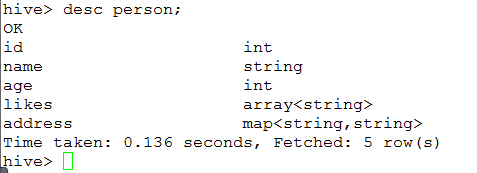
-- Hive建表 语法 CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name LIKE existing_table_or_view_name [LOCATION hdfs_path]; create table person( id int, name string, age int, likes array<string>, address map<string,string> ) row format delimited -- 指定导入数据的列与列之间的分隔符 fields terminated by ',' -- 指定Array类型的分隔符 collection ITEMS TERMINATED BY '-' -- 指定map类型的分隔符 map keys terminated by ':' -- 指定行与行之间的分隔符 lines terminated by '\n';
Hive导入数据
# 三条数据,列与列之间用,号隔开;array之间用-号隔开;map之间用:号隔开;行与行用换行符隔开 1,tom,28,game-music-book,stu:henan-home:henan-work:beijing 2,jack,21,money-meinv,stu:wuhan-home:wuhan 3,lusi,18,shopping-music,stu:shanghai-home:beijing
导入数据:
hive> load data local inpath '/opt/data.txt' overwrite into table person;

数据查询
-- 查询所有 select * from person; -- 还可以这样查 select * from person where name='tom'; -- 或者这样 select * from person where likes[1]='music'; -- 还有这样 select * from person where address['stu']='shanghai'; -- 还有这样 select avg(age) from person; -- ... 等标准的SQL语法大多都可以在Hive中使用包括一些函数,因为Hive是类SQL的;
但在Hive中不推荐进行这些操作:Insert、Update、Delete等操作,因为Hive的特性是对数据仓库的数据进行提取,针对的数据是批量的,不适合行级的运算;
清空表
-- 使truncate清空表 TRUNCATE TABLE person; -- 通过覆盖的方式清空表 insert overwrite table person select * from person where 1=2;
drop table person;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号