SQLServer覆盖索引
为了更好地理解覆盖索引,在正式介绍覆盖索引之前,首先稍微来谈一谈有关索引的一些基础知识。
数据页和索引页
在SQLServer中,数据存储的基本单位是页,一页的大小为8KB,分别由页首,数据行和行偏移量组成,如下图结构:
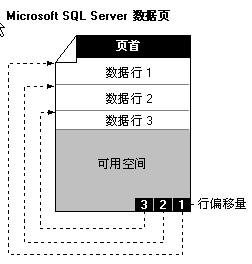
页首固定占用96个字节,用来存储相关的页面系统信息,例如所属的数据库表对象Id等。数据行是真实数据的存储区域,每一行的大小是不固定的。行偏移量是一个数组,数组的每个位置占2个字节,用来存储数据行距离开头的位置偏移量,主要是用来做快速定位,例如想要查找第N行,只要访问行偏移量数组的第N项,就能快速找到数据行所在的位置。索引页和数据页的结构类似,所不同的是索引页的数据行存储的是和索引相关的信息。
聚集索引和非聚集索引
聚集索引定义了表中数据存储的真实物理位置,它是按照指定列的顺序来存储数据的,类比于新华字典中的汉字是按照拼音顺序排列的,所以每张表只能建立一个聚集索引。聚集索引是一棵B+树结构,包含索引页和数据页,最底下的一排叶子节点是数据页,往上则为索引页,来看一张图应该更清晰一些:
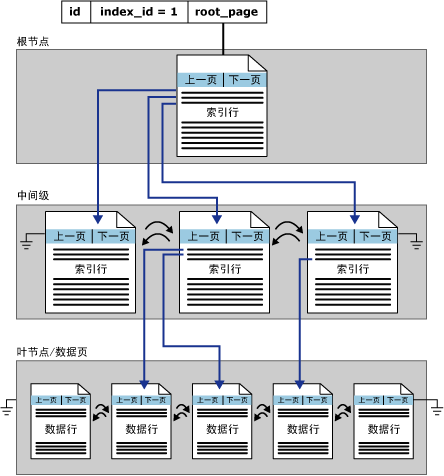
非聚集索引是独立于数据真实存储顺序逻辑而存在的,类比于新华字典中按偏旁部首查找汉字的方式。与聚集索引对比,非聚集索引也是B+树的数据结构,但却只包含索引页,而且在一张表中可以建立多个非聚集索引,有关索引的深入分析可以查看这篇文章。同样来看一张非聚集索引的图:
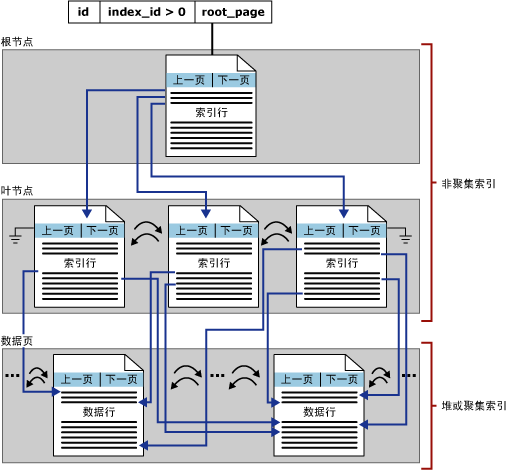
什么是覆盖索引
覆盖索引是在SQLServer2005中引入的概念,只能建立在非聚集索引的基础上,通常情况下,非聚集索引的索引页是不包含真实数据的,只存储着指向数据页中数据行的指针,而覆盖索引则是通过将数据存储在索引页上,从而在查找对应数据的时候,只要找到索引页就可以访问到数据,无需再去查询数据页,所以说这个索引是数据“覆盖”的。


--覆盖索引的创建是在非聚集索引创建的基础上增加INCLUDE语句 CREATE NONCLUSTERED INDEX {index_name} ON {table_name}(column_name...) --非聚集索引可以声明指定多个列作为索引项 INCLUDE(column_name...) --覆盖索引可以指定多个列存储在索引页上
覆盖索引分析
这一小节将通过创建覆盖索引以及使用DBCC命令查看索引的方式进行介绍。
IF DB_ID('Test') IS NULL BEGIN CREATE DATABASE Test; END GO USE Test; GO IF OBJECT_ID('t1','U') IS NULL BEGIN CREATE TABLE t1 ( t1_id INT NOT NULL IDENTITY(1,1), t1_name VARCHAR(20) NOT NULL, t1_name1 VARCHAR(20) NOT NULL, t1_name2 VARCHAR(20) NOT NULL, t1_name3 VARCHAR(20) NOT NULL, t1_name4 VARCHAR(20) NOT NULL, t1_name5 VARCHAR(20) NOT NULL ); END /* *插入测试数据 */ INSERT INTO t1 ( t1_name, t1_name1, t1_name2, t1_name3, t1_name4, t1_name5 ) SELECT 'name', 'name', 'name', 'name', 'name', 'name' FROM sysobjects o1 CROSS JOIN sysobjects o2; /* *创建覆盖索引 */ IF NOT EXISTS(SELECT 1 FROM sysindexes WHERE name='idx_t1_id') BEGIN CREATE NONCLUSTERED INDEX idx_t1_id ON t1(t1_id) INCLUDE(t1_name); END
执行CROSS JOIN插入的测试数据有4000条左右,现在可以使用DBCC命令来查看表的数据页和索引页的情况。
/* *查看页的基本信息 *前提条件:表中必须插入了数据 *所需参数:(数据库名,表名,-1表示显示全部IAM页,数据页, 索引页) */ DBCC IND (Test,t1,-1);
执行完这条命令后,应该可以看到显示的页信息,其中PageType=1的行表示数据页,PageType=2的行表示索引页,任意选择一条PageType=2的行,找到PageFID和PagePID,就可以使用DBCC命令来查看索引页的具体信息。
/* *查看索引页的基本信息 *所需参数:(数据库名,PageFID,PagePID,3表示输出每行每列的信息) */ DBCC PAGE(Test,1,7732,3);
执行完这条命令后,应该可以看到t1_name这一列的信息是包含在这个索引页中的。现在可以通过执行不同的查询SQL来查看覆盖索引所带来的性能提升,在执行SQL的同时开启显示实际的执行计划,从而可以清楚得看到对比结果。
SELECT t1_name FROM t1 WHERE t1_id = 500; SELECT t1_name1 FROM t1 WHERE t1_id =500;

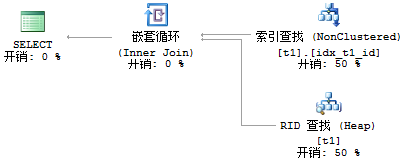
查询1开销为33%,而查询2的开销为67%,对比可以看到查询t1_name的开销比查询t1_name1的开销小很多,因为查询t1_name只需要执行索引,就可以在索引页上找到数据,而查询t1_name1还要去查找数据页。
覆盖索引的思考
创建索引能带来查询的优化,但却带来了更改数据的负担,覆盖索引也不意外。由上面的分析我们知道,覆盖索引是非聚集索引的进一步细化,在更新数据的时候,如果涉及到覆盖索引INCLUDE的列,除了更改数据页之外还要更改索引页,比单纯使用非聚集索引增添了额外的工作。所以,在设计覆盖索引的时候,要综合考虑应该覆盖的列,确保INCLUDE的列能带来最佳的性能优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号