K-近邻算法(KNN)
KNN算法描述
输入:训练样本$X = (x_1,x_2,...,x_n)$。训练样本标签$Labels = (l_1,l_2,...,l_n)$。待测样本$y$。参数K
输出:待测样本$y$的标签t
算法描述:计算待测样本与每个训练样本的相似度,然后选出最相似的前K个训练样本,则待测样本的标签定义为这K个训练样本中出现次数最多的标签类别。
每个样本$x_i$都是一个向量$x_i = (x_{i1},x_{i2},...,x_{im})$,表示样本具有m个特征值。计算两个样本之间的相似度,可以用向量之间的距离表示。距离的计算通常采用欧式距离。
西瓜书上对KNN算法有如下描述:
它没有显示的训练过程。事实上,它是“懒惰学习”的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进行处理
KNN分类器的性能
KNN分类器的性能主要跟两个方面有关系:一是距离的计算方式。除了采用欧式距离,还有用曼哈顿距离等其它的距离表示方式。不同的方法计算的结果有很大的不同。二是参数k的选择。假设一个二分类问题(0或1)。选出的与测试样本最相似的五个训练样本的标签分别为(100111)。则当k=1时,待测样本的标签t=1;k=3时,t=0;k=5时,t=1。可见不同的k的取值对结果有很大的影响。对于一个待测样本集,选取怎样的k才能使得训练误差最小,需要具体实验的测定。
Python2.x 代码实现
这是 《机器学习实战》上的源码
# -*- coding: utf-8 -*- from numpy import * import os import operator # 输入待分类向量inX,训练数据集dataSet,训练标号labels,使用近邻的K个数据测试 def classify0(inX,dataSet,labels,K): # 计算每个训练样本和待测样本之间的欧式距离 dataSetSize = dataSet.shape[0] diffMat = tile(inX,(dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 # 按距离排序 sortedDistIndicies = distances.argsort() classCount = {} # 选出距离最近的K个训练数据的标号 for i in range(K): voteIlabel = labels[sortedDistIndicies[i]] # 利用字典来存储选出的每个类别的个数 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 # python 内置的排序函数,对任何可迭代对象进行排序。现在对字典的值(即类别的个数)进行排序 sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True) # 返回字典的值最高的那个键值(即类别) return sortedClassCount[0][0]
其中,inX和dataSet需要用numpy的array或者matrix表示。
手写体识别应用
每个样本的数据化表示如下
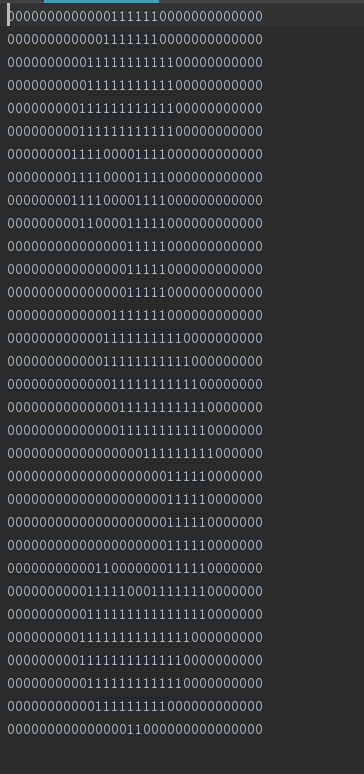
如图,这是一个3的样本。训练样本集里面总共有十个(0-9)数字的样本,每个数字有199个样本。每个样本由32*32的数字表示。
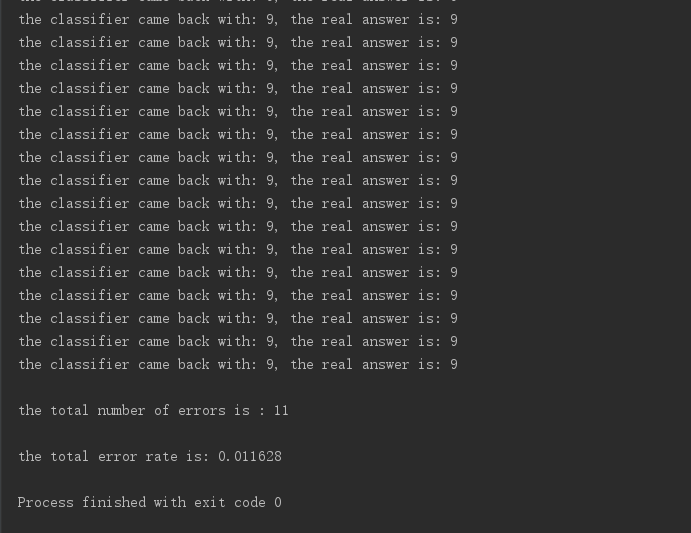
具体的源码就不放出来了。其实都是读取文件数据,转化成向量,然后调用上面的函数做训练。训练的结果和书上的结果一模一样
思考
有一个问题我想不太明白,KNN算法需要将样本向量化表示。假设一个电影样本有这么两个特征:参演的演员人数,票房。数据化之后,前者扣除龙套人物,一般在数十或者数百量级,后者则是数亿量级。现实中有很多这样的例子,它的特征数据化之后,有些特征会很大,有些特征会很小。很小的数字做差,依然很小,很大的数字做差可能会很大。这样,不同的特征对于距离的贡献便有很大区别。数字越大的贡献越多。如果一类样本有一个特征数字表现很大,其余的很小,那么这类样本之间的距离几乎都由该大数字特征决定。这显然是不合理的。
我觉得现实应用可能需要对特征进行同区间归一化,或者进行加权,以解决上述问题。不知道是不是这样做。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号