google protocol buffer——protobuf的问题和改进2
2020-09-20 15:43 tera 阅读(902) 评论(0) 收藏 举报这一系列文章主要是对protocol buffer这种编码格式的使用方式、特点、使用技巧进行说明,并在原生protobuf的基础上进行扩展和优化,使得它能更好地为我们服务。
在上一篇文章中,我们举例了在移动互联网场景下原生protobuf类库使用上的问题,并且自己完成了一个java的编码类库。本文中将展示swift版本的解码类库,并且用网络请求的demo来模拟实际的使用场景,最后再进一步优化protobuf的编码过程
本文包括以下几个部分
1.swift版本的解码类库实现,这里要特别说明,因为大部分情况下请求参数的数据量是不大的,所以优先关心返回参数的解码
2.用网络请求模拟实际的使用场景,包括java和swift
3.根据移动互联网应用场景的特点进一步优化protobuf的编码过程
Swift解码类库
因为swift也是一个强类型语言,所以主要思路和java的完全一致,包括所有的基础算法都是从java那里搬过来的,因此大部分代码都会比较类似。不过swift和java相比比较大的区别是对于反射的支持并不是很好,所以在模型定义上会有一些限制。
1.模型定义
为了能正常使用反射,需要将模型和其中的字段定义为@objc,且类需要实现NSObject接口,另外为了方便转换json,类还需要实现Codable接口
在上一篇文章最后,我们做了一个模型的测试CoderTestStudent,这里就在swfit中定义同样一个模型
import Cocoa
@objc class CoderTestStudent:NSObject,Codable{
@objc var age:Int = 0
@objc var father:Parent
@objc var friends:[String]
@objc var hairCount:Int64 = 0
@objc var height:Double = 0
@objc var hobbies:[Hobby]
@objc var isMale:Bool
@objc var mother:Parent
@objc var name:String?
@objc var weight:Float
}
@objc class Parent:NSObject,Codable{
@objc var age:Int = 0
@objc var name:String?
}
@objc class Hobby:NSObject,Codable {
@objc var cost:Int = 0
@objc var name:String?
}
2.类的定义和入口方法
首先是入口方法,这里思路和java类库一样,首先需要一个入口方法接收2个参数,编码后的字节数组data和对象的类型typeT
class Decoder: NSObject{
...
func deserialize<T: NSObject>(data:[Int], typeT:T.Type) ->T{
buffer = data
pos = 0;
limit = data.count;
let result = T.init()
return deserializeObject(limit:data.count, obj:result);
}
...
}
3.主逻辑方法,可递归调用
接着是用于递归的方法,总体思路还是利用反射获取到类型中的所有字段,并将其按字母顺序进行排序,之后根据其类型分别调用不同的数据读取方法
func deserializeObject<T: NSObject>(limit:Int, obj:T)->T{
//这里对模型字段进行排序
let result = obj
let mirror = Mirror(reflecting: result)
if(mirror.children.count == 0){
pos = limit
return result;
}
var fieldNameDict:[String: Mirror.Child] = [:]
for property in mirror.children{
fieldNameDict[property.label!] = property
}
let sortedKeys = Array(fieldNameDict.keys).sorted(by:{$0.lowercased()<$1.lowercased()})
var fieldNumberDict:[Int: Mirror.Child] = [:]
var order = 1
for key in sortedKeys{
fieldNumberDict[order]=fieldNameDict[key]
order += 1
}
//排序是否完成
while(pos < limit){
//读取字节中的序号字段
let fieldNum = readTag();
//为了老版本客户端的兼容性,如果读取到的序号已经超过了模型的最大字段序号
//那么就说明这是新版本客户端新增的字段,老版本客户端就不需要解析了
if(fieldNum >= order){
pos = limit
return result
}
//获取和序号相符合的字段
if let field = fieldNumberDict[fieldNum] {
//通过反射获取字段信息
let fm = Mirror(reflecting: field.value)
//根据字段描述判断出字段的类型,然后进入不同的读取数据的方法
if(fm.description == "Mirror for Optional<String>"){
let r = readString();
result.setValue(r, forKey: field.label!)
}else if (fm.description == "Mirror for Int"){
let r = readInt()
result.setValue(r, forKey: field.label!)
}else if (fm.description == "Mirror for Bool"){
let r = readBool()
result.setValue(r, forKey: field.label!)
}else if (fm.description == "Mirror for Double"){
let r = readDouble()
result.setValue(r, forKey: field.label!)
}else if (fm.description == "Mirror for Float"){
let r = readFloat()
result.setValue(r, forKey: field.label!)
}else if (fm.description == "Mirror for Int64"){
let r = readInt64()
result.setValue(r, forKey: field.label!)
}
else if (fm.description == "Mirror for Optional<Array<String>>"){
let r = readStringArray()
let value = result.value(forKey: field.label!)
//如果nil则新建一个数组,否则append
if(value == nil){
result.setValue(r, forKey: field.label!)
}else{
var array = (value as! [String])
array.append(contentsOf: r)
result.setValue(array, forKey: field.label!)
}
}else if (fm.description == "Mirror for Optional<Array<Int>>"){
let r = readIntArray()
result.setValue(r, forKey: field.label!)
}else if (fm.description == "Mirror for Optional<Array<Double>>"){
let r = readDoubleArray()
result.setValue(r, forKey: field.label!)
}else if (fm.description == "Mirror for Optional<Array<Float>>"){
let r = readFloatArray()
result.setValue(r, forKey: field.label!)
}else if (fm.description == "Mirror for Optional<Array<Int64>>"){
let r = readLongArray()
result.setValue(r, forKey: field.label!)
}else if (fm.description == "Mirror for Optional<Array<Bool>>"){
let r = readBoolArray()
result.setValue(r, forKey: field.label!)
}else if (fm.description.hasPrefix("Mirror for Optional<Array<")){
//如果是一个Object的Array,那么就比较复杂一些
//首先获取该Object类型的字符串
if let match = fm.description.range(of: "(?<=<)[^>]+", options: .regularExpression) {
let first = fm.description.substring(with: match)
let className = first.split{$0 == "<"}.map(String.init)[1]
//通过反射加载类
let cls: AnyClass = NSClassFromString("\(_namespace!).\(className)")!;
let objType = cls as! NSObject.Type
let object = objType.init()
//递归调用
let r = readObject(obj: object)
let currentValue = result.value(forKey: field.label!)
//判断数组是否为空
if(currentValue == nil){
result.setValue([r], forKey: field.label!)
}else{
var array = currentValue as! [NSObject]
array.append(r)
result.setValue(array, forKey: field.label!)
}
}
}else{
//如果是一个Object,那么和Array类似,通过字符串动态获取模型的类
if let match = fm.description.range(of: "(?<=<)[^>]+", options: .regularExpression) {
let className = fm.description.substring(with: match)
let cls: AnyClass = NSClassFromString("\(_namespace!).\(className)")!;
let objType = cls as! NSObject.Type
let object = objType.init()
//递归调用
let r = readObject(obj: object)
result.setValue(r, forKey: field.label!)
}
}
}
}
return result
}
4.读取单独字段的方法
这里都会调用一些基础方法
func readBool()->Bool{
return readRawVarint32() == 1
}
func readInt()->Int{
return readRawVarint32()
}
func readInt64()->Int64{
return readRawVarint64();
}
func readDouble()->Double{
return longBitsToDouble(bits: readRawLittleEndian64())
}
func readFloat()->Float{
return intBitsToFloat(bits: readRawLittleEndian32())
}
5.单独字段的基础方法
因为readRawVarint32、readRawVarint64是照搬java版本google提供的官方逻辑,里面全是位的运算,这里就不展示了,有兴趣的可以去git查看完整代码,这里主要看下longBitsToDouble和intBitsToFloat
swift中的Double和Float类型都提供了一个接受bitPattern类型参数的构造函数,这就是swift提供的按照IEEE754标准将字节转换成Double和Float的方法
但是在swift中,所有的字节都是无符号的,而java中是有符号的,并且readRawLittleEndian64和readRawLittleEndian32是按照java版本的逻辑编写的,返回的值是有正有负,因此在swift中还原就会有问题
所以这里就需要对bits的正负做一个判断,如果是负数则需要将其最高位的符号位置为0
9223372036854775807表示01111111 11111111 111111111 11111111 11111111 11111111 111111111 11111111
2147483647表示01111111 11111111 111111111 11111111
经过&运算后,即可将最高位置为0,之后将得到的Double和Float取负即可得到实际的值
func longBitsToDouble(bits:Int64)->Double{
if(bits > 0){
return Double(bitPattern: UInt64(bits))
}else{
let postiveBits:Int64 = bits & 9223372036854775807
return -Double(bitPattern: UInt64(postiveBits))
}
}
func intBitsToFloat(bits:Int)->Float{
if(bits > 0){
return Float(bitPattern: UInt32(bits))
}else{
let postiveBits:Int = bits & 2147483647
return -Float(bitPattern: UInt32(postiveBits))
}
}
6.读取数组字段的方法
这里就是调用读取单独字段的方法,并将其构造成一个数组即可
func readBoolArray()->[Bool]{
var result:[Bool] = []
let length = readRawVarint32()
let limit = pos + length;
while (pos < limit) {
result.append(contentsOf: [readBool()]);
}
return result
}
func readLongArray()->[Int64]{
var result:[Int64] = []
let length = readRawVarint32()
let limit = pos + length;
while (pos < limit) {
let ss = readInt64()
result.append(contentsOf: [ss]);
}
return result
}
func readDoubleArray()->[Double]{
var result:[Double] = []
let length = readRawVarint32()
let limit = pos + length;
while (pos < limit) {
result.append(contentsOf: [readDouble()]);
}
return result
}
func readFloatArray()->[Float]{
var result:[Float] = []
let length = readRawVarint32()
let limit = pos + length;
while (pos < limit) {
result.append(contentsOf: [readFloat()]);
}
return result
}
func readIntArray()->[Int]{
var result:[Int] = []
let length = readRawVarint32()
let limit = pos + length;
while (pos < limit) {
result.append(contentsOf: [readInt()]);
}
return result
}
func readStringArray()->[String]{
return [readString()]
}
7.读取Object和ObjectArray的方法
这里就是递归调用主逻辑方法
需要特别注意的是,即使是ObjectArray,也是调用这个读取单个Object的方法
在第三篇详解protobuf编码原理的文章中有展示,对于子对象的Array,protobuf其实是将其每一个元素都编码成了独立的完整的protobuf结构,因此可以一个一个读取
https://www.cnblogs.com/tera/p/13578660.html
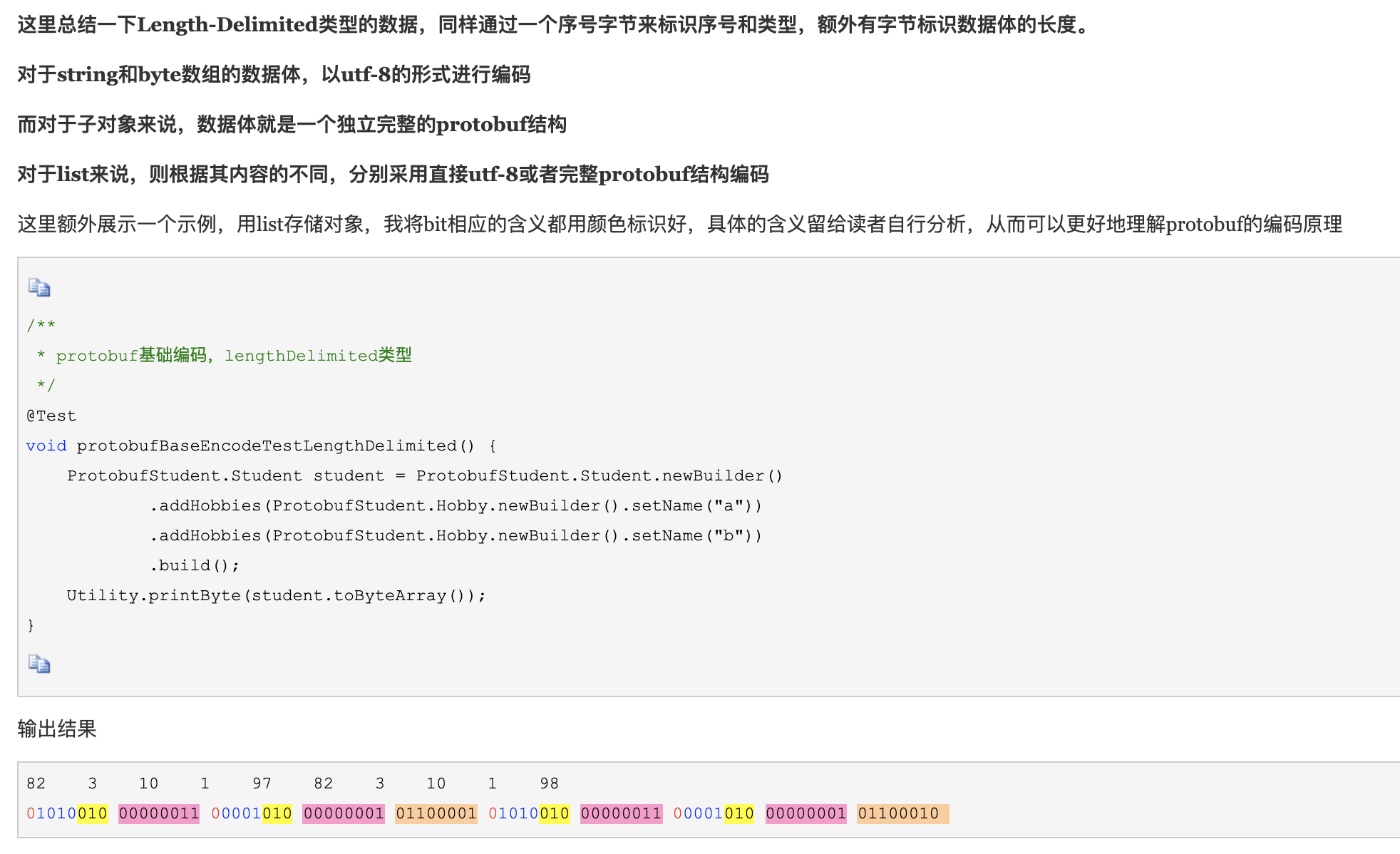
func readObject<T:NSObject>(obj: T)->T{
let length = readRawVarint32()
let limit = pos + length
return deserializeObject(limit: limit, obj: obj)
}
以上就是对于解码代码的解析
完整的demo代码在https://github.com/TeraTian/protobuf-ios-demo
接着我们就可以看下实际使用的例子
客户端的模拟请求
接着我们就用2个简单的模拟请求看下客户端和服务端的实际交互
首先我们写一个服务端的接口
这里需要注意的是,因为protobuf最终结果是一个byte数组,所以不能用常规的对象返回,而是需要直接将结果byte数组写入到返回流中
@RestController
@RequestMapping("/protobuf")
public class ProtobufController {
@Autowired
private HttpServletResponse response;
@GetMapping("/getStudent")
public void getStudent() throws IOException {
String source = "{\"age\":13,\"father\":{\"age\":45,\"name\":\"Tom\"},\"friends\":[\"mary\",\"peter\",\"john\"],\"hairCount\":342728123942,\"height\":180.3,\"hobbies\":[{\"cost\":130,\"name\":\"football\"},{\"cost\":270,\"name\":\"basketball\"}],\"isMale\":true,\"mother\":{\"age\":45,\"name\":\"Alice\"},\"name\":\"Tera\",\"weight\":52.34}";
CoderTestStudent student = JSON.parseObject(source, CoderTestStudent.class);
ServletOutputStream out = response.getOutputStream();
byte[] result = BasicEncoder.serialize(student, CoderTestStudent.class);
Parent a = new Parent();
out.write(result);
}
}
1.Android的请求解析
先看android的客户端请求,也就是java版本的解码类库
/**
* 模拟安卓端的网络请求
*/
@Test
public void httpTest() throws IOException {
Request request = new Request.Builder()
.url("http://localhost:8080/protobuf/getStudent")
.build();
OkHttpClient client = new OkHttpClient();
try (Response response = client.newCall(request).execute()) {
byte[] bytes = response.body().bytes();
CoderTestStudent student = new BasicDecoder().deserialize(bytes, CoderTestStudent.class);
System.out.println(JSON.toJSONString(student, SerializerFeature.PrettyFormat));
}
}
2.IOS的请求解析
接着看ios端的请求,也就是swift版本的类库
这里需要注意的是,因为所有解码的基础方法都是翻自java,正如之前所述,java中的字节是带符号的,而swift中字节是无符号的,在进行数字运算的时候就会导致结果不正确,所以这里将所有的字节都转换成了Int类型
var pd = Decoder(namespace:"commond_line")
func request(){
let sem = DispatchSemaphore(value:0)
let url = URL(string: "http://localhost:8080/protobuf/getStudent")
var request = URLRequest(url: url!)
request.httpMethod = "GET"
let session = URLSession(configuration: .default)
let task = session.dataTask(with: request, completionHandler: {(data, response, error) in
//这里做了一个字节到Int8的转换
let buffer = data!.map({ (bit) -> Int in
let int8Bit: Int8 = Int8(bitPattern: bit)
return Int(int8Bit)
})
let model = pd.deserialize(data: buffer, typeT: CoderTestStudent.self)
printJson(object:model)
});
task.resume()
sem.wait(timeout: DispatchTime.now() + 100)
}
request()
两者输出结果如下
{
"age":13,
"father":{
"age":45,
"name":"Tom"
},
"friends":[
"mary",
"peter",
"john"
],
"hairCount":342728123942,
"height":180.3,
"hobbies":[
{
"cost":130,
"name":"football"
},
{
"cost":270,
"name":"basketball"
}
],
"isMale":true,
"mother":{
"age":45,
"name":"Alice"
},
"name":"Tera",
"weight":52.34
}
至此,整个protobuf在移动互联网端的使用上就完全闭环了
protobuf的定制化优化
现在我们已经解决了原生类库会导致客户端体积不可控的问题,那么接下去我们可以在原生类库的基础上再次根据我们的实际情况进行进一步优化
通过之前的几篇编码原理的文章,我们可以了解到protobuf的编码结果的大小比json小的原因在于,它将很多信息在编码的过程中舍弃了,而这部分被舍弃的信息则是直接存放在了信息发送方和接收方的本地类库中,概括来说就是用存储空间换取传输空间。
那么此时我们就可以考虑,能否继续扩展这种思想,将其做得更进一步
结合日常工作的实际情况来看,很多时候APP接口在设计的时候为了达成尽可能的“服务端可控”,大部分客户端的文案、数据都是服务端返回的。那么在这个过程中,我就发现很多文案虽然是可能发生改变的,但是变化的频率是很低的,例如一些界面的标题(订单详情、商品列表)、一些营销文案(尊敬的白金会员)、一些长期固定的说明文案(预订提示:可随时取消)等等。这些文案大部分时候都是不会变的,但是又说不定哪一天产品一拍脑袋就需要修改,所以我在开发接口的时候都会将这些文案从服务端返回,而不是写死在客户端,这样在将来某一天需要修改的时候直接服务端改个配置就行。
那么在上述场景下,客户端每一次请求到这些文案的时候都是从服务端拿数据,但是大部分时候又不变,那么这些数据的传输其实就是浪费的,然而又需要应对将来可能的变化,不能写死在客户端。为了解决这个矛盾,我们可以在定义字段的时候增加默认值的概念。
1.单一默认值
例如我们定义如下的模型
public class DefaultStringStudent {
public String name;
}
假设我们在传递的时候,这个学生大部分情况name都是Peter,那么我们可以同时在客户端和服务端的模型中定义一个默认值Peter
java模型采用annotation的方式
这里Encode的注解是在编码的时候用,即服务端
而Decode则是在解码的时候用,即客户端
public class DefaultStringStudent {
@EncodeDefault(value = {"Peter"})
@DecodeDefault(value = {"Peter"})
public String defaultName;
}
swift模型采用默认值的方式
@objc class DefaultStringStudent:NSObject,Codable{
@objc var name:defaultName? = "Peter"
}
于是,如果我们需要传递的json数据如下
{
"name": "Peter",
"age": 13
}
在编码的时候我们就不需要将Peter进行编码,而只需要编入一个标志位,表示该字段是一个默认值,那么数据接收方在解析的时候就可以从自己的模型定义中拿到Peter的默认值。而当name改变的时候,我们就可以按照正常方式将其编码,而数据接收方也会直接取编码中的值
2.多种默认值
除了单一默认值的情况,还有可能是多种默认值。例如订单的状态,可能包括预订成功、预订失败、预订取消等等,如果我们采用一个int的枚举值表示,让客户端根据int枚举值判断之后展示相应文案,那么当将来需要新增一个预订确认中的状态时已经发布的老版本客户端将无法处理,所以这些文案也应当是从服务端返回。
顺着之前的思路,我们在定义默认值的时候可以定义多个,而在编码的时候,除了用标记位表示是否使用默认值,再需要一个Int表示默认值的索引。
还是用上面的DefaultStringStudent举例
java模型
public class DefaultStringStudent {
@EncodeDefault(value = {"Peter"})
@DecodeDefault(value = {"Peter"})
public String defaultName;
@EncodeDefault(value = {"Peter", "Mary", "John"})
@DecodeDefault(value = {"Peter", "Mary", "John"})
public String multipleDefaults;
}
swift模型,因为没有自定义annotation这种机制,所以只能采用|分隔
@objc class DefaultStringStudent:NSObject,Codable{
@objc var defaultName:String? = "Peter"
@objc var multipleDefaults:String? = "Peter|Mary|John"
}
3.可替换的默认值
还有一种情况,一个字符串中的大部分都是不变的,只有其中的几个字符会根据不同的情况改变,例如“亲爱的XXX用户您好,欢迎回来”,在这种情况下,只有XXX需要根据实际情况进行替换,而其余的字符都是可以不变的,因此在传输该数据的过程中,我们只需要传递会变化的部分,而不变的部分就存放到模型中
java模型
public class DefaultStringStudent {
@EncodeDefault(value = {"Peter"})
@DecodeDefault(value = {"Peter"})
public String defaultName;
@EncodeDefault(value = {"Peter", "Mary", "John"})
@DecodeDefault(value = {"Peter", "Mary", "John"})
public String multipleDefaults;
@EncodeDefault(value = {"亲爱的%s用户您好,欢迎回来"}, replace = true)
@DecodeDefault(value = {"亲爱的%s用户您好,欢迎回来"})
public String replacedDefault;
}
swift模型
@objc class DefaultStringStudent:NSObject,Codable{
@objc var defaultName:String? = "Peter"
@objc var multipleDefaults:String? = "Peter|Mary|John"
@objc var replacedDefault:String? = "亲爱的%@用户您好,欢迎回来"
}
4.代码修改
那么为了实现上述三种情况下的编码,我们就必须修改编码和解码的代码以满足我们的要求
a.java编码过程
这里主要修改了主逻辑中和String相关的部分,针对EncodeDefault的注解进行处理,并且会调用writeDefaultString进行默认字符串的编码
if (value instanceof String) {
String str = (String) value;
//这里为了APP多版本的兼容,因此允许定义多个EncodeDefault
EncodeDefaults multiple = f.getAnnotation(EncodeDefaults.class);
if (multiple != null) {
EncodeDefault[] singles = multiple.value();
if (singles.length > 0) {
int startIndex = 0;
//这里就需要遍历多个EncodeDefault了,每一个EncodeDefault代表了一个APP的版本
for (int i = 0; i < singles.length; i++) {
EncodeDefault single = singles[i];
//这里判断当前请求的APP版本是否符合当前Default配置的版本要求
if (single.version().isEmpty() || comparator.compare(appVersion, single.version()) >= 0) {
//寻找数据的值是否在默认值的列表中,并且还需要判断默认值是否是只替换部分的默认值
FindIndexResult indexResult = findIndex(startIndex, single.value(), str, single.replace());
int index = indexResult.index;
//如果找到了索引,那么久调用writeDefaultString方法,否则则直接调用最后正常写入字符串的方法
if (index >= 0) {
bytes.addAll(writeDefaultString(fieldNum, index, indexResult.params));
break label1;
}
startIndex += single.value().length;
} else {
break;
}
}
}
} else {
//如果只有一个Default,那么就直接处理即可
EncodeDefault single = f.getAnnotation(EncodeDefault.class);
if (single != null && (single.version().isEmpty() || comparator.compare(appVersion, single.version()) >= 0)) {
FindIndexResult indexResult = findIndex(0, single.value(), str, single.replace());
int index = indexResult.index;
if (index >= 0) {
bytes.addAll(writeDefaultString(fieldNum, index, indexResult.params));
break label1;
}
}
}
bytes.addAll(writeString(fieldNum, (String) value));
}
writeDefaultString方法
private List<Byte> writeDefaultString(int fieldNum, int index, List<String> params) {
List<Byte> bytes = new ArrayList<>();
//序号类型字节的最后一个bit用1表示需要默认值
bytes.addAll(writeTag(fieldNum, 1));
if (params == null || params.size() == 0) {
//如果是非替换的默认值,那么直接写入默认值的索引即可,并且索引的最后一个bit标识为0
bytes.addAll(writeInt32NoTag(index << 1 | 0));
} else {
//如果是需要替换的默认值,那么默认值的索引值最后一个bit需要标识为1
bytes.addAll(writeInt32NoTag(index << 1 | 1));
//将需要替换的部分用^分隔开,写入编码结果中
bytes.addAll(writeStringNoTag(String.join("^", params)));
}
return bytes;
}
b.java的解码修改
if (field.getType().equals(String.class)) {
//判断是否需要走默认值逻辑
if (isDefault) {
int defaultIndex = readRawVarint32();
int index = defaultIndex >> 1;
//获取序号字节类型的最后一个bit,判断是否要走替换的逻辑
boolean replace = (defaultIndex & 1) == 1;
//对于客户端来说,没有多版本的概念,所以直接
DecodeDefault feature = field.getAnnotation(DecodeDefault.class);
if (feature != null) {
String[] values = feature.value();
if (values.length > index) {
if (replace) {
//如果需要替换,那么久一个一个替换
String params = readString();
List<String> paramList = Arrays.asList(params.split(split));
field.set(result, Helper.format(values[index], paramList, split));
} else {
//不需要替换,那就直接取索引对应的默认值即可
field.set(result, values[index]);
}
}
}
} else {
//不需要默认值,那么就正常解码即可
field.set(result, readString());
}
}
c.swift的解码修改
if(fm.description == "Mirror for Optional<String>"){
let isdefault = tuple.1 == 1
//判断是否需要走默认值逻辑
if(isdefault){
let defaultIndex = readRawVarint32();
let index = defaultIndex >> 1;
//取索引的最后一个bit判断是否需要替换
let replace = (defaultIndex & 1) == 1;
let defaultValues = result.value(forKey: field.label!)
if(defaultValues != nil){
let array = (defaultValues! as! String).components(separatedBy: "|")
if(index < array.count){
if(replace){
//替换的逻辑
let r = readString().split(separator: "^");
var strarr:[String] = []
for rr in r{
strarr.append(String(rr))
}
let replaceResult = String(format:array[index], arguments:strarr)
result.setValue(replaceResult, forKey: field.label!)
}else{
//直接根据索引取默认值
result.setValue(array[index], forKey: field.label!)
}
}else{
result.setValue(nil, forKey: field.label!)
}
}
}else{
//不需要走默认值逻辑,就正常解码
let r = readString();
result.setValue(r, forKey: field.label!)
}
}
所有类库的修改主要就是针对3种情况下字符串的处理
5.优化后的类库demo
我们做如下一个测试,相同的模型,比较默认值和非默认值的编码结果
@Test
void defaultValueTest() {
//默认值
String source = "{" +
" \"defaultName\": \"Peter\"," +
" \"multipleDefaults\": \"Mary\"," +
" \"replacedDefault\": \"亲爱的Tera用户您好,欢迎回来\"" +
"}";
test(source, DefaultStringStudent.class, DefaultStringStudent.class);
//非默认值
String source2 = "{" +
" \"defaultName\": \"NotDefault\"," +
" \"multipleDefaults\": \"Ben\"," +
" \"replacedDefault\": \"不是默认值\"" +
"}";
test(source2, DefaultStringStudent.class, DefaultStringStudent.class);
}
test方法如下
static <T, U> void test(String source, Class<T> encodeClass, Class<U> decodeClass) {
try {
System.out.println(source);
System.out.println("------------------- 编码结果 -------------------");
T javaModel = JSON.parseObject(source, encodeClass);
//这里传入了一个APP版本的比较方法,以确定默认值能否匹配当前请求对应的APP版本
byte[] teraBytes = new CustomProtobufEncoder("47", (app, target) -> {
int a = Integer.parseInt(app);
int b = Integer.parseInt(target);
return a > b ? 1 : (a == b ? 0 : -1);
}).serialize(javaModel, encodeClass);
Helper.printBytes(teraBytes);
} catch (Exception e) {
System.out.println(e.getMessage());
}
System.out.println("");
}
输出结果
{ "defaultName": "Peter", "multipleDefaults": "Mary", "replacedDefault": "亲爱的Tera用户您好,欢迎回来"}
------------------- 编码结果 -------------------
3 0 5 2 7 1 4 84 101 114 97
count:11
{ "defaultName": "NotDefault", "multipleDefaults": "Ben", "replacedDefault": "不是默认值"}
------------------- 编码结果 -------------------
2 10 78 111 116 68 101 102 97 117 108 116 4 3 66 101 110 6 15 -28 -72 -115 -26 -104 -81 -23 -69 -104 -24 -82 -92 -27 -128 -68
count:34
可以看到如果不带用默认值的编码结果为34个字节,而采用默认值的编码结果则只有11个字节
本文总结
1.swift版本类库的编写
2.一个网络请求的demo使得整个protobuf的使用完成了闭环
3.在protobuf原始类库的基础上进一步进行了优化,使得传输数据的大小进一步减小
至此,通过5篇文章讨论了和protobuf相关的几个问题
是什么;怎么用;编码原理;使用上的问题;改进问题的方法;进一步优化的思路

 浙公网安备 33010602011771号
浙公网安备 33010602011771号