

数据库规范化设计(函数依赖、三大范式)
数据库设计
6.1 函数依赖
关系模式中的各属性之间相互依赖、相互制约的联系称为数据依赖。数据依赖有函数依赖 、多值依赖。
函数依赖(FD ,Functional Dependency)是关系模式中属性之间的一种逻辑依赖关系。
函数依赖的定义:设关系模式R(U,F), U是属性全集,F是U上的函数依赖所构成的集合,X和Y是U的子集,如果对于R(U)的任意一个可能的关系r ,对于X的每一具体值,Y 都有唯一的具体值与之对应,则称X决定函数Y ,或Y函数依赖于X,记作X→Y。我们称X为决定因素, Y为依赖因素。当Y不函数依赖于X 时,记作:X/→Y。当X→Y且Y→X时,则记作:X↔Y。
U={SNo,SN,Age,Dept,MN,CNo,Score}
F={SNo→SN,SNo →Age,SNo→ Dept, (SNo ,CNo)→ Score}
设有关系模式R(U),U是属性全集,X和Y是U的子集。
完全函数依赖:如果 X→ Y ,并且对于 X 的任何一个真子集 X' ,都有 X'/→Y , 则称 Y 对 X 完全函数依赖,记作X→Y(箭头上加 f)。
部分函数依赖:如果对 X 某个真子集 X', 有 X'→Y , 则称 Y 对 X 部分函数依赖,记作 X→Y(箭头上加 p)。
只有当决定因素是组合属性时,讨论部分函数依赖才有意义;当决定因素是单属性时,只能是完全函数依赖。
传递函数依赖:设有关系模式 R(U) ,U 是属性全集,X,Y,Z是 U 的子集。
若X→ Y ,但 Y/→X,而Y→Z(Y∉Z,Z∉Y),则称 Z 对 X 传递函数依赖,记作:X → Z (箭头上加 t)。如果 Y→X,则 X↔Y , 这时称 Z对 X 直接函数依赖,而不是传递函数依赖。
6.2 范式
把关系数据库的规范化过程中为不同程度的规范化要求设立的不同标准称为范式(Normal Form)。关系数据库中的关系必须满足一定的要求。满足不同程度要求的为不同范式
各种范式之间存在联系:5NF⊂4NF⊂3NF⊂2NF⊂1NF
某一关系模式R为第n范式,可简记为R∈ nNF。一个低一级范式的关系模式,通过模式分解可以转换为若干个高一级范式的关系模式的集合,这种过程就叫规范化。
6.2.1 第一范式
如果关系模式R的所有的域为简单域,其元素不可再分,则称R为第一范式的关系,简记为R∈ 1NF
1NF的关系模式要求属性不能再分,即属性项不能是属性组。
第一范式是对关系模式的最起码的要求。不满足第一范式的数据库模式不能称为关系数据库
但是满足第一范式的关系模式并不一定是一个好的关系模式
例:
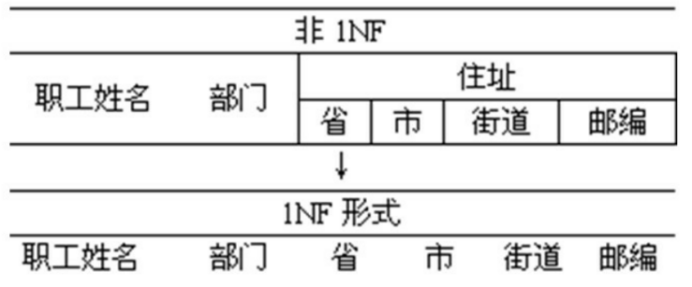
6.2.2 第二范式
若R∈1NF,且每一个非主属性完全函数依赖于任何一个候选码,则R∈2N。
2NF解决了插入异常的问题,如果一个关系模式R不属于2NF,便会产生以下几个问题问题:
- 插入异常:假设 Sno = 07102 , Sdept = CS的学生还未选课,因课程号是主属性,因此该学生的信息无法插入SMC
- 删除异常:假定某个学生本来只选修了3号课程这一门课·现在因身体不适,他连3号课程也不选修了。因课程号是主属性,此操作将导致该学生信息的整个元组都要删除
- 修改复杂:例如学生转系,在修改此学生元组的Sdept 值的同时,还可能需要修改系主任的名字。如果这个学生选修了K门课,则必须无遗漏地修改K个元组中全部 Sdept · Mname信息
- 数据冗余度大:如果一个学生选修了10门课程,那么他的Sdept和Mname 值就要重复存储了10次
采用投影分解法将一个1NF的关系分解为多个2NF的关系,可以在一定程度上减轻原1NF关系中存在的插入异常、删除异常﹑数据冗余度大、修改复杂等问题
·将一个1NF关系分解为多个2NF的关系,并不能完全消除关系模式中的各种异常情况和数据冗余
6.2.3 第三范式
3NF:关系模式R<U,F>中若不存在这样的码X﹑属性组丫及非主属性Z(Y ⊈Z),使得× ->Y,Y →z,y ↛X ,成立,则称R<U,F>∈3NF若。R∈ 3NF,则每一个非主属性既不部分依赖于码也不传递依赖于码。
采用投影分解法将一个2NF的关系分解为多个3NF的关系,可以在一定程度上解决原2NF关系中存在的插入异常﹑删除异常﹑数据冗余度大﹑修改复杂等问题。
将一个2NF关系分解为多个3NF的关系后,并不能完全消除关系模式中的各种异常情况和数据冗余
6.2.4 BCNF
BC范式(BCNF):设关系模式R<U,F> ∈ 1NF ,如果对于R的每个两数依赖X→Y,若Y ∉X,则X必含有候选码,那么R∈BCNF。若R∈ BCNF:每一个决定属性集(因素)都包含候选码,R中的所有属性(主,非主属性)都完全函数依赖于码。
6.2.5 小结

范式的优点:
1)范式化的数据库更新起来更加快;
2)范式化之后,只有很少的重复数据,只需要修改更少的数据;
3)范式化的表更小,可以在内存中执行;
4)很少的冗余数据,在查询的时候需要更少的distinct或者group by语句。
范式的缺点:
范式化的表,在查询的时候经常需要很多的关联,因为单独一个表内不存在冗余和重复数据。这导致,稍微复杂一些的查询语句在查询范式的schema上都可能需要较多次的关联。这会增加让查询的代价,也可能使一些索引策略无效。因为范式化将列存放在不同的表中,而这些列在一个表中本可以属于同一个索引。
反范式的优点:
1)可以避免关联,因为所有的数据几乎都可以在一张表上显示;
2)可以设计有效的索引;
反范式的缺点:
表格内的冗余较多,删除数据时候会造成表有些有用的信息丢失。

