分布式数据流的轻量级异步快照
对 https://arxiv.org/abs/1506.08603 (Lightweight Asynchronous Snapshots for Distributed Dataflows) 的翻译和自己理解。
前言
这边文章讲述的是flink的checkpoint(检查点)的原理,checkpoint是目前主流的分布式流式处理框架用于恢复失败作业而保证数据不丢失的常用方法,也是flink实现exactly-once的基础。
以checkpoint为基础,定期生成全局的状态快照(global stat snapshot),当出现作业失败,将集群状态恢复到上一个可用的global stat snapshot再开始继续计算,从而保证数据不丢失。
同时这个“checkpoint/snapshot”还必须尽可能不影响正常的流式计算过程,不能说在生成“checkpoint/snapshot”的时候,对整个集群的处理速度有很大影响,甚至停下来(文章中举了一个反例,叫Naiad,这个不了解),那么这种方案等同于不可用。
这篇文章就是介绍了一种轻量级异步快照,叫做ABS(Asynchronous Barrier Snapshotting)。Flink就是采用了这种方法。
定义
Flink把流式计算编译成任务的有向图,比如下图的最基础的wordcount任务图:总共有三个阶段:输入阶段(source)、计数阶段、输出阶段(sink),每个阶段各有两个task。
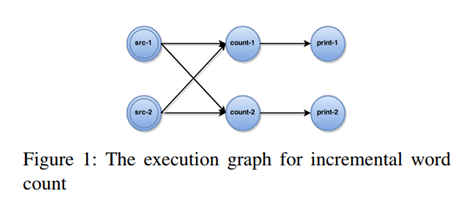
每个阶段都是有状态的:输入阶段保持输入文件的偏移量,计数阶段保持每个word的当前计数值。
任务有向图可以表示为 G = (T,E),其中结点T代表task,有向边E表示数据通道.每个任务t ∈ T, 表示某个算子实例(operator)的一个独立运算,包含三个要素:
1) 输入通道I(t)和输出通道O(t)的集合。I(t) ,O(t) ⊆ E
2) 算子状态s(t)
3) 一个函数f(t)
任务消费从输入通道I(t)进来的数据(record),并更新状态s(t),然后通过f(t)产生输出到输出通道。
对于一个全局快照G = (T ,E),为保证失败时恢复到正确状态,需要满足以下两点:
1) 可终止性(Termination):从触发生成全局快照开始,全局快照应该在有限时间内生成。
2) 可用性(Feasibility):全局快照包含了所有有关计算的信息。
无环图的ABS
定期在source record(src-1,src-2)里面插入barrier(栅栏),barrier经过所有节点(每个节点,即task,会根据收到的barrier,产生新的同步的barrier)到达sink。这样通过barrier可以将每个节点的状态划分为“before barrier”和“after barrier”,所有“barrier前”的节点状态就构成了一个全局快照。
这里有个细节,全局快照G = (T ,E),应该是包括节点T和通道E的状态,但是这里只用了节点T的状态,而忽略了通道E的状态。这是没有问题的,因为通过barrier将数据进行了划分,所有在通道内的数据,有两种:1)“before barrier”的数据,这种数据将会在下游节点被处理,然后一起保存在下游节点的状态快照内。2)“after barrier”的数据,这种数据将会在源头被重放。所以全局快照G实际上变成所有节点T的状态。
算法的示意图和描述如下:


这里有几个前提:
1) 通道内的数据传输都是FIFO的。这样才能保证将数据划分为“before barrier”和“after barrier”。
2) task可以阻塞和恢复它的输入通道。当task阻塞了自己的输入通道,其他task可以继续执行,和整个计算过程都停下来是不一样的。
这样产生的全局快照是满足“可终止性(Termination)”和“可用性(Feasibility)”的。
有环图的ABS
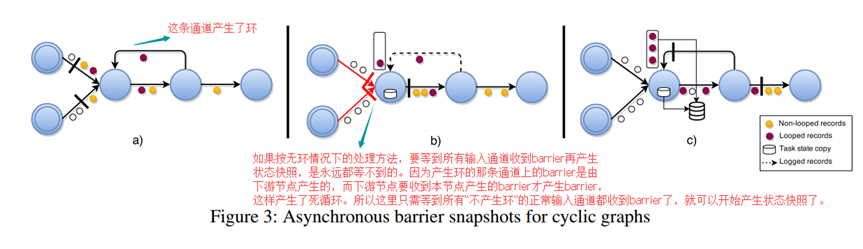
相比无环图的ABS,做了两个变动:
1) 在无环图的ABS里面,节点在收到它的所有输入通道的barrier之后,才能开始生成自己的状态快照。而在有环图的ABS里面,节点只需收到它的所有常规输入通道(排除那些“产生环的输入通道”)的barrier之后,就开始生成自己的快照状态。因为如果不这么做,会产生死循环,见上图中的描述。
2) 当节点开始产生自己的快照状态时,如果阻塞住它的所有输入通道,包括“产生环的输入通道”,这样“产生环的输入通道”中“before barrier”(这个barrier是由下游节点生成的)的数据可能就不会被记录在本次的快照状态内。所以对于“产生环的输入通道”,在开始产生快照状态时,要把所有的数据额外记录在一个backup log文件里面,一直到在该输入通道收到barrier为止。
恢复机制
理解了ABS的原理之后,对出现任务失败时的恢复机制应该就很好理解了,具体说来,就是找到上一个可用的全局快照,所有的节点恢复到该快照时的状态,如果有backup log(有环图)的话,还需要把backup log里面所有的数据输入到该节点处理。
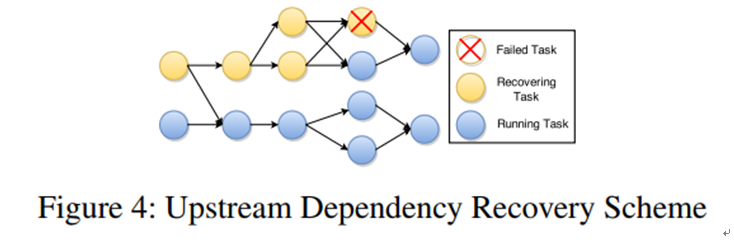
另外,恢复也可以是局部的,只需恢复那些和失败任务有关的节点到快照状态即可,如下图.
不过这里还有一个前提:就是每个节点都必须对上游发过来的数据做去重,否则可能导致数据重复.实现exactly-once也必须有这个前提.
性能影响
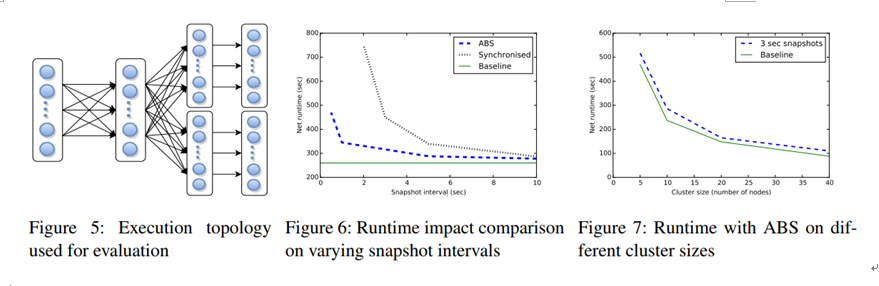
上图是加入ABS后对集群性能的影响,还包括ABS和同步快照方案的性能对比.其中Baseline表示没有采用任务快照方案.
测试采用10亿条数据平均输入到每个源.
Figure 6:集群包含10个nodes,在生成快照的不同间隔下(横轴),比如ABS、Baseline、同步快照方案的对比。
Figure 7:生成快照间隔固定为3s,在集群包含不同个数的nodes,ABS和Baseline的对比。
exactly-once
上述方案其实有一个漏洞,就是sink节点。sink节点一般是外部存储(比如kafka),在ABS方案中,sink节点也是有向图的一部分,也必须能提供状态快照功能才行,否则当恢复到某一个全局快照是,可能有一部分数据已经写入外部存储,如果不回滚的话就重复了。
所以flink有一篇另外描述exactly-once的文章https://flink.apache.org/features/2018/03/01/end-to-end-exactly-once-apache-flink.html。大概思路是:把属于一个全局快照的所有sink数据一次性提交,提交成功才算该全局快照执行成功。另外外部存储还要有事务性写入(一批数据要么写入都成功,要么都失败)的功能。kafka 0.11开始有提供事务性写入功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号